Semantic IDs for Joint Generative Search and Recommendation (2025)
Note
Joint Search&Recommendation 생성 모델에서 어떤 Semantic ID 구성 전략이 두 태스크를 동시에 잘 처리하는지 비교함
- 기존 task-specific Semantic ID는 단일 태스크에서 최강이지만, 상대 태스크 성능을 최대 60% 이상 하락시킴
- Multi-task bi-encoder로 생성한 Semantic ID가 두 태스크 모두에서 경쟁력 있는 균형을 달성
- RQ-KMeans 토크나이저가 학습 기반 RQ-VAE보다 일관되게 우수하여 실용적이고 안정적인 선택지임
Background
- Generative Retrieval 모델의 부상: LLM 기반 생성 모델이 검색과 추천을 단일 아키텍처로 처리하는 방향으로 수렴 중
- 아이템을 discrete token 시퀀스로 표현 → LLM이 직접 생성
- SASRec 같은 전통적 방식의 고유 item ID 대신 Semantic ID 사용 추세
- Semantic ID란?: 사전 학습된 임베딩을 quantization해 얻은 discrete token 집합
- 비슷한 임베딩의 아이템은 토큰을 공유 → generalization 및 cold-start 대응 가능
- 핵심 설계 변수: 어떤 임베딩 공간을 사용하느냐
- 기존 한계: 선행 연구들은 태스크별 임베딩 (검색용 bi-encoder, 추천용 collaborative filtering) 으로 Semantic ID를 구성
- 연구 질문: 단일 Semantic ID 공간으로 검색과 추천 모두를 효과적으로 처리할 수 있는가?
Method
실험 세팅
- 데이터셋: MovieLens 25M 기반 Joint S&R 데이터셋
- 62,138개 영화, 1.24M 유저-아이템 인터랙션
- 아이템당 Gemini-2.0-flash로 생성한 자연어 쿼리 20개 (train 10 / test 10)
- 검색 popularity bias 제거를 위해 uniform 분포 사용 → 실제 서비스에서는 유사 popularity 분포면 더 유리할 것
- 생성 모델:
flan-t5-base, Search & Recommendation 동시 학습 (3 epochs) - 평가 지표: Recall@30
- ID 토크나이저: RQ-KMeans (FAISS residual quantiser), 코드북 2개 × 크기 256 (총 512 토큰)
Semantic ID 구성 전략
Task-specific 접근 (베이스라인)

- Search-based:
all-mpnet-base-v2기반 bi-encoder를 검색 데이터 로 fine-tuning- In-batch random negatives, MultipleNegativesRankingLoss
- 임베딩 차원: 386
- Rec-based: ENMF (Efficient Neural Matrix Factorization) 협업 필터링 모델
- 임베딩 차원: 256
- 이 두 방법은 각 태스크에서 최고 성능이지만 상대 태스크에서 폭락
Cross-task 접근
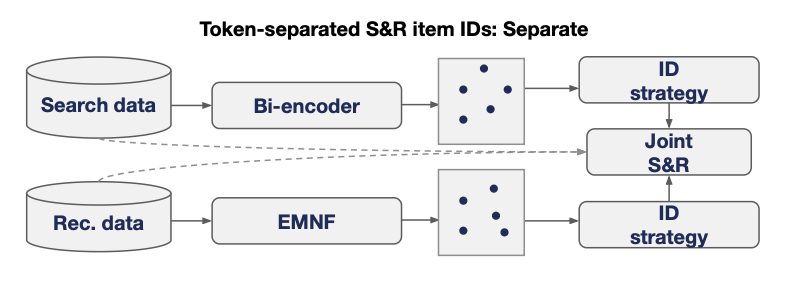
- Separate: 검색/추천 ID에 태스크 태그(
SEARCH:,REC:)를 prefix로 붙여 분리- 토큰 vocabulary를 2배(1024개)로 늘림 (같은 모델 안에 두 개의 독립적인 vocab이 존재하는 셈)
- 검색 프롬프트는 검색 토큰만, 추천 프롬프트는 추천 토큰만 생성하도록 함
- 두 태스크 간 지식 공유가 불가 → 오히려 Joint 학습의 정규화 효과를 상쇄
- Prefix-share: 공유 코드북 256 + 태스크별 코드북 512 = 혼합 구조
- 두 임베딩을 concatenation해서 단일 quantizer에 입력

- Fused_concat: 와 를 -normalize 후 concatenation
- 차원 불균형 문제: bi-encoder(386d) > ENMF(256d) → 검색 임베딩이 더 큰 영향력
- Fused_SVD: 두 임베딩을 truncated SVD로 차원을 로 맞춘 후 element-wise 합산
- Fused_concat 대비 추천 성능 개선, 검색 성능은 소폭 하락
- Multi-task: bi-encoder를 검색()과 추천()을 동시에 학습
- 검색: query-item 쌍, 추천: co-occurring item 쌍
- Loss = 두 contrastive loss의 합
- 단일 encoder가 retrieval + collaborative filtering 신호를 모두 담음
Experiments
주요 결과

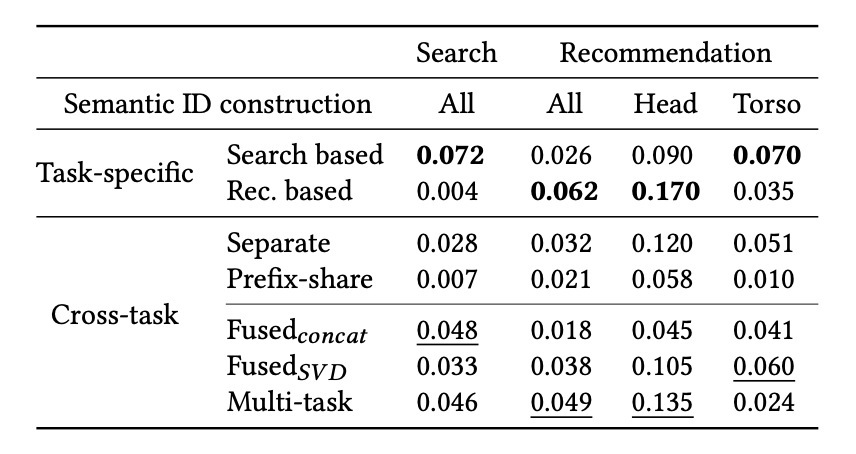
-
Task-specific:
- Search-based: Search R@30=0.072 (최고), Rec R@30=0.026
- Rec-based: Search R@30=0.004, Rec R@30=0.062 (최고)
- 검색 fine-tuned IDs는 추천 성능 60% 하락, 반대도 동일한 패턴
-
Cross-task:
- Separate → 태스크 간 지식 공유 없어 정규화 효과 소실
- Prefix-share → quantization 품질 문제(인 것 같다고 함..)로 최하위
- Fused_concat → 차원 불균형으로 추천 성능 저하
- Fused_SVD: → SVD로 차원 맞추면 추천 회복, 검색 소폭 손실
- **Multi-task → 두 태스크에서 가장 균형 잡힌 성능
-
Popularity 분석 (Head vs. Torso):
- Rec-based ID는 Head(상위 1% 인기 아이템)에서 R@30=0.170으로 압도적
- Torso에서는 Search-based ID(0.070)가 Rec-based(0.035)보다 우수
Tokenization Method Ablation
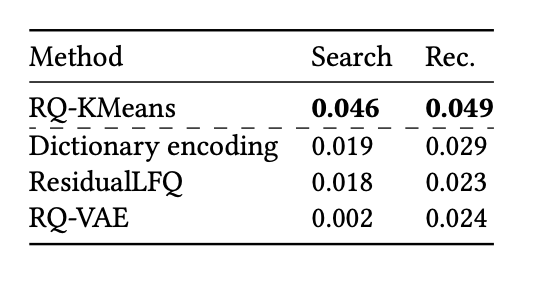
- Multi-task 임베딩 고정 후 quantizer 방법 비교함
- RQ-KMeans가 학습 기반 auto-encoder 방식(RQ-VAE)을 일관되게 압도
💭
- RQ-VAE가 k-means보다 나쁜 건 다른 논문에서도 일관적으로 언급
- 이미 fine tuned된 임베딩을 quantize만 하는 거라 그런지 학습 없이 단순하게 k-means로 묶어주는 게 잘 워킹하는 것 같기도
- MovieLens에서 검색 쿼리를 LLM으로 자동 생성했는데 실제 서비스 검색 쿼리와 차이가 클 것 같음 (특히 이 점을 고려하면 popularity 분석 결과는 어떻게 보면 당연한 듯)
- Fused_concat에서 임베딩 차원 불균형(386 vs 256)이 성능에 크게 영향을 준다는 점은 실제 적용 시 중요한 포인트