Is Augmentation Effective in Improving Prediction in Imbalanced Datasets? (2024)
Intro
- 라벨의 불균형이 극심하면 대부분 언더샘플링/오버샘플링을 하라고 함
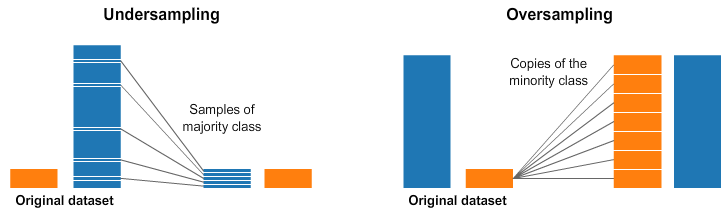
-
언더샘플링 : 더 많은 클래스(보통 majority 라고 함)를 랜덤으로 샘플링해서 일부만 사용
-
오버샘플링 : 더 적은 클래스(보통 minority 라고 함) 를 이렇게 저렇게 샘플링해서 더 많이 사용
- 이렇게 저렇게 란?
- 이미 있는 minority 데이터들을 랜덤하게 똑같이 복제해서 뽑을 수도 있고
- 이미 있는 minority 데이터들과 비슷하지만 살짝 다른 가상의 데이터를 새로 생성해서 뽑을 수도 있고
- 예를 들면 SMOTE(Synthetic Minority Over-sampling Technique) 같은 방법들
- 이렇게 저렇게 란?
-
근데 개인적으로는 지금까지 샘플링으로 뭐 대단히 나아진 적이 없고 차라리 학습하면서 loss에 weight을 주는 게 훨씬 더 효과적이었던 기억이 있다. 이 논문은 ⚠️ 오버샘플링의 효과 없음을 보여주는 증명과 실험을 포함하는데 평소에 경험적으로 생각한 내용과 일치해서 재밌었음
정리
- 전제: 분류 모델은 기본적으로 주어진 데이터 에 대해 관심 있는 타겟 변수 가 특정 값을 가질 확률을 최대한 정확하게 추정하는 것, 즉 를 배우는 것
- 모든 상황은 0 또는 1의 이진분류이며 1이 minority class라고 가정
- 어떤 임계값 를 정해서, 가 를 넘어가면 이 샘플은 1이고 그렇지 않으면 0
- 핵심 결론:
- 원래 데이터 기준의 와 데이터를 랜덤하게 오버샘플링하여 비율을 동등하게 맞춘 기준의 가 있을 때
- 와 는 1:1 대응이 가능하기 때문에, 를 가지고 를 0.5로 설정한 분류기나 애초에 오버샘플링을 하지 않은 에 대해서 최적의 를 설정한 분류기나 결국 차이가 없다
- 증명은 여기의 supplementary material에
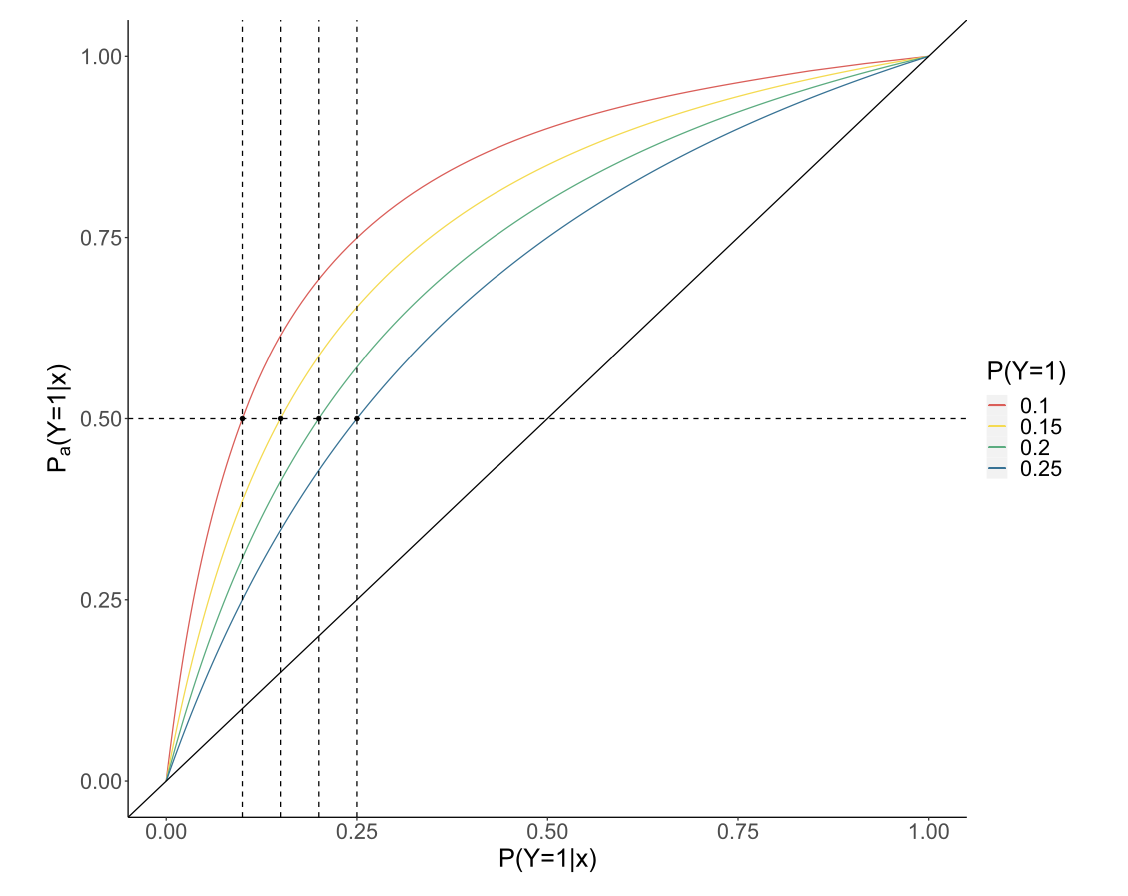
- : 원래 데이터셋의 불균형 정도, 즉 인 경우 전체 데이터 중 1이 10%라는 뜻
- 이 그림을 보면 에 대해 0.5라는 임계값을 정하는 것은 사실상 원본 데이터를 가지고 학습한 에 대해 를 로 정한 것과 맵핑되므로 괜히 오버샘플링을 해서 리소스를 더 쓸 게 아니라 그냥 애초에 decision threshold를 0.1로 하라는 것
실험
- 심지어 단순 랜덤 샘플링 (복제) 뿐 아니라 SMOTE 나 ADASYN처럼 데이터를 추가로 생성하는 테크닉마저도 랜덤 샘플링과 다를 바 없는 결과를 낸다라는 주장
- 여러 오버샘플링 방식을 비교
- 랜덤 샘플링: 데이터를 새로 생성하는 것이 아닌 minority를 단순 랜덤하게 복제해서 샘플링
- SMOTE: minority 샘플들과 가까운 이웃들로 가상의 데이터를 생성
- Borderline SMOTE: 기본적으로 SMOTE이지만, 분류기가 헷갈리는 라벨간 경계에 있는 샘플들 위주로 선정하여 그 이웃들로 가상의 데이터를 생성
- ADASYN: Borderline SMOTE와 유사하지만, 경계선에 있는 샘플들마다 근처에 있는 majority 클래스 개수에 따라 샘플링 비율을 다르게 가져감
- 여러 오버샘플링 방식을 비교
성능
- 기준: balanced accuracy
- 지표: percentage gain
- 오버샘플링 테크닉을 적용한 모델을 라고 하고 적용하지 않은 기본 모델을 라고 할 때 두 버전의 모델의 성능 차이
- 비교대상
- 랑 모두 로 결정했을 때
- 는 c=0.5로 하고, 는 앞서 수식과 같이 최적의 기준으로 결정했을 때
- 와 모두 최적의 로 결정했을 때
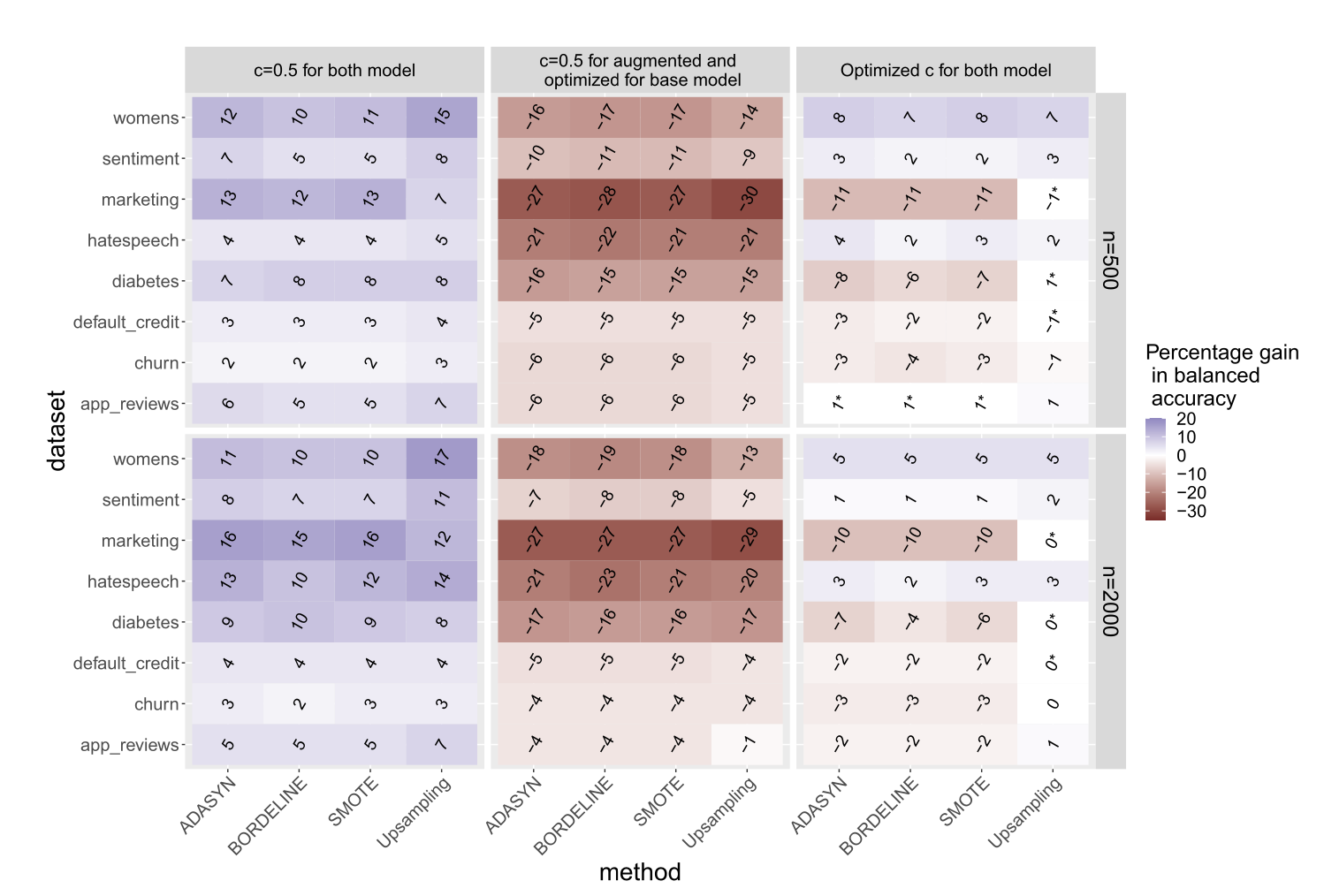
- 우선 둘 다 를 0.5로 고정시키면(이것은 지금까지 오버샘플링이 효과 있다고 보여진 대부분의 세팅과 동일한 세팅임) 대부분의 케이스에서 오버샘플링의 percentage gain이 양수로서 즉 오버샘플링이 balanced accuracy를 상당히 증가시키고 있는 것을 확인할 수 있음
- 그러나 기본 모델에서 를 최적의 로 선택한 것과 비교하면 오히려 오버샘플링 테크닉들이 더 나쁜 balanced accuracy를 보여주고 있으며 랜덤 복제가 아닌 SMOTE나 ADASYN 같은 생성 방식도 동일함
- 오버샘플링 모델에서도 최적의 를 선택해봤지만 별 차이가 없음 = 임계값을 고르는 것 외에 다른 모든 것이 동일하다면 오버샘플링의 업사이드는 없다고 보여짐
x,y관계를 잘 추정하는지
- 정해진 임계값에 의존하는 balanced accuracy라는 어떤 단일 지표가 아닌, 모델이 전체적으로 를 잘 추정했는지를 비교해봄
- 지표: AUC와 Brier Score
- 그 결과 AUC 면에서는 대부분 오버샘플링이 효과가 떨어지고 심지어 Brier Score 면에서는 더 나쁜 결과를 낸다는 것을 확인할 수 있음. ROC curve를 그려봐도 기본 모델과 오버샘플링 모델의 차이가 없음