Generalized User Representations for Large-Scale Recommendations and Downstream Tasks / RecSys2025
- 다양한 사용자/콘텐츠 신호 기반 공통된 사용자 표현을 먼저 학습(오토인코더 기반) → 다운스트림 태스크에서 재사용 (transfer learning)
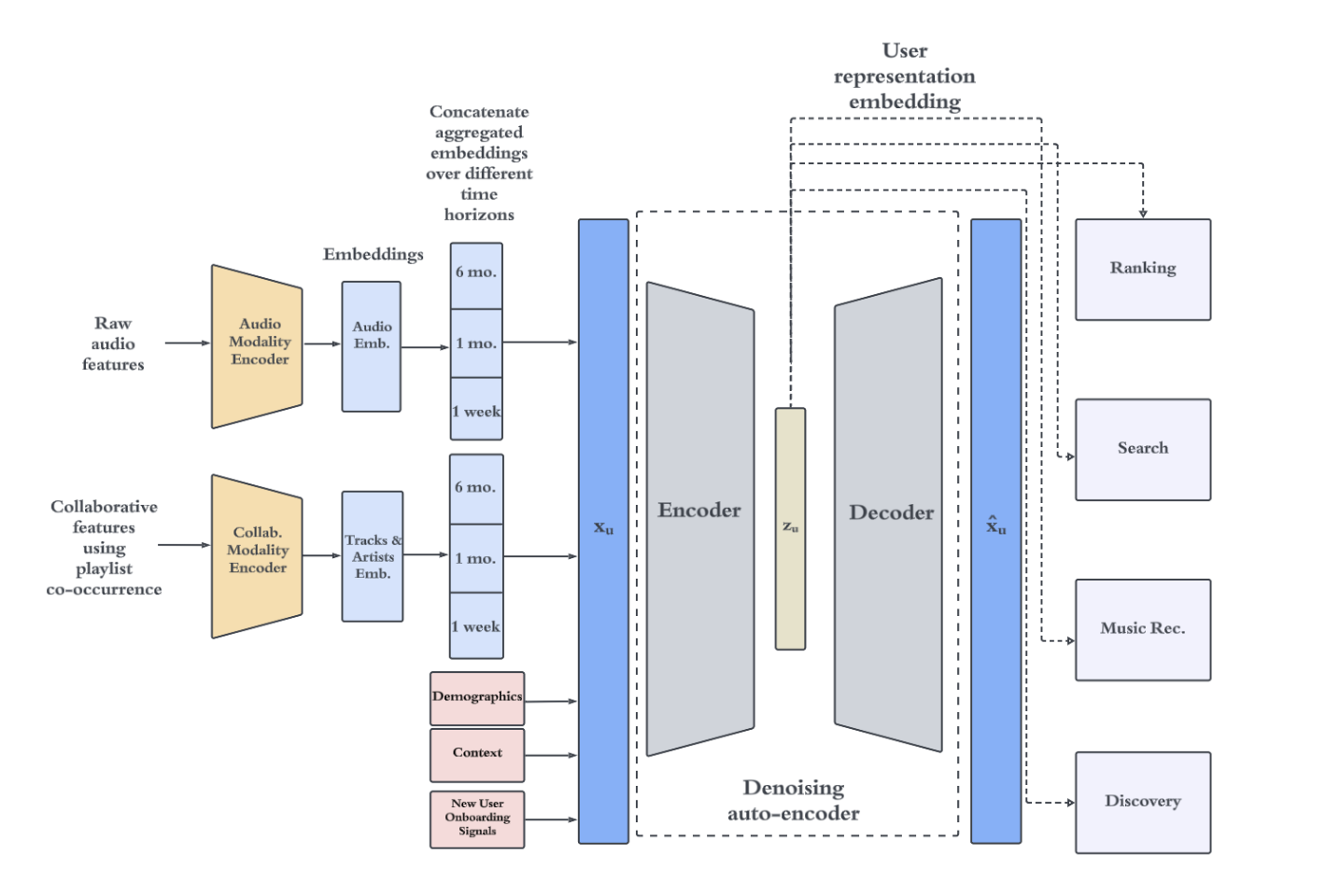
- 입력
- 콘텐츠: audio features, playlist co-occurrence 기반(collaborative) features (Track/Artist Embedding)
- 이 콘텐츠 임베딩을 여러 타임 윈도우로 aggregate(1주/1달/6개월)해서 concat
- 그외 유저 정보: 온보딩시 선택한 아티스트, 언어 / 국가, 가입 정보 등 demographic / contextual signal
- 콘텐츠: audio features, playlist co-occurrence 기반(collaborative) features (Track/Artist Embedding)
- Denoising Autoencoder
- 고차원 사용자 feature → latent user embedding (encode) → 원래 피쳐 (decode)
- 이렇게 얻은 유저 표현을 랭킹/검색/음악 추천/discovery 등 다운스트림 태스크에서 입력으로 사용함
- 운영
- batch management
- 유저 임베딩은 주기적으로 재학습되므로 매번 batch ID를 부여하고 다운스트림 모델도 동일한 batch ID 기준으로 오프라인 학습됨
- 모든 다운스트림 모델이 준비됐을 때 한번에 batch switch하고 추론시에서도 batch ID가 섞이지 않도록 함
- near-real time inference
- batch management
결과
- 미래 청취 예측
- 7일 내 청취 여부 예측
- 전통적인 MF 및 LightFM/DLRM 등 딥모델과 대비해서도 AUC, accuracy 모두 개선
- 범용 임베딩 + 단순 다운스트림 모델이 task-specific heavy 모델보다 강함
- 4시간 이내의 cold user 대응
- 인기곡 휴리스틱 추천, 온보딩에서 누른 아티스트 평균과 대조했을 때 온보딩 완료/미완료 모두에서 큰 개선
- 특히 온보딩 미완료에서도 안정적 성능을 보였고 행동 데이터가 거의 없는 상황에서도 인구통계 + 초기 신호를 잘 통합한 유저 표현을 활용할 수 있음을 보여줌
- 유저 클러스터링 (임베딩 품질 자체 평가)
- 유저 임베딩만 가지고 nearest neighbor를 뽑은 뒤 동일 아티스트 취향/동일 국가 취향/ 동일 온보딩 그룹 등으로 relevance를 정의하고 nDCG@50으로 평가했을 때 평균 embedding 대비 우수
- 프로덕션 적용 (online A/B)
- Candidate Generation
- album discovery 증가
- i2s(impression-to-stream) 크게 개선
- Search Re-ranking
- 전체 0.06% (이미 최적화된 시스템에서 의미 있는 상승이라고 함)
- Home Ranking
- discovery 증가, consumption share(전체 소비 중 특정 지면이 차지하는 비중) 증가
- 라이브러리/검색 재생대비 홈화면에서 추천을 통한 재생이 차지하는 비중이 늘었다 = 익숙한 것 → 새로운 것으로 사용자 행동 이동
- Artist Preference Model
- 성능 유지하면서 인프라/피쳐 비용 50% 절감
- Candidate Generation
- ablation 온보딩 피쳐 제거, modality embedding 제거, 데모그래픽 제거 등 → 모델이 단일 신호에 많이 의존하고 있다기보단 성공적으로 멀티 소스를 통합하고 있음