Closing the Online-Offline Gap: A Scalable Framework for Composed Model Evaluation / Recsys25
Problem Formulation
- 대규모 추천·광고 시스템에서 실제 온라인 성과는 여러 모델의 예측과 복잡한 서빙 비즈니스 로직이 결합하여 생성됨
- 예를 들어 메타의 광고 서빙 시스템에서는 key score가 eCVR(expected CVR)인데,
eCVR (purchase)= P(click |imp.)·P(1d_conv. |click)+ P(click |imp.)·(1− P(1d_conv. |click))· P(conv. after 1d |no 1d_conv.)+P (1d_conv. & no click |imp.)+customized_functor(context_data)이런식의 prediction composition을 사용함.- 이게 뭔가 싶은데.. 하나의 광고가 보여졌을 때 클릭할 확률, 클릭했을 때 바로 전환(구매)할 확률, 클릭하고 나중에 살 확률, 안 클릭했지만 나중에 구매할 확률 등등이 있고 이를 예측하는 여러 모델들이 존재. 추가로 복잡한 캠페인별 가중치나 유저별 보정 등의 비즈니스로직까지 들어감. 하지만 이 중 어떤 경로로 구매를 하든 간에 결국 구매를 하는 게 중요하므로 이런 전체 시나리오를 평균 낸 기대값을 사용하는 것임.
- 예를 들어 메타의 광고 서빙 시스템에서는 key score가 eCVR(expected CVR)인데,
- 그러나 모델을 선택할 때는 각 단일 모델의 오프라인 지표(AUC, NE)에 의존하기 때문에 결국 온라인 결과와의 불일치(gap)이 발생하게 됨
- 일반적인 off-policy eval의 한계를 해결하기 위한 evaluator들(IPS, Doubly Robust 등)을 시도해봤지만 Meta Ads에서는 단순 point-wise evaluator보다 항상 결과가 좋지 않았다고 함. 왜냐하면 결국 마지막에는 이런 복잡한 prediction composition으로 서빙되기 때문에 weighting이 의미를 잃고 불안정해지는 것 같다고 함. 이론적인 방법론들은 항상 한가지 모델+한가지 정책을 가정하는데 실제 시스템이 그렇지 않기 때문에
- 그래서 아래 프레임워크는 실제 behavior distribution을 건드리지 않고 미세한 모델 교체에 대한 성능을 상대 비교하는 방식으로 접근함. 오프라인-온라인 갭에 있어서 distribution shift보다는 한가지 모델 ↔️ 복잡한 서빙 스코어 간의 차이에서 오는 문제가 더 영향이 크다고 보는 것.
- 물론 ground truth는 여전히 현재 시스템이 만든 것이라는 점이 문제지만 어차피 완벽한 counterfactual은 불가능하고, 현실적으로 대규모 시스템 운영하는 데 있어 보통 전체 모델/로직을 완전히 갈아끼우는 radical한 변화보다는 보통 한개의 모델을 미세하게 바꾸면서 최적화하는 경우가 많으니 이런 방향성도 꽤 의미가 있겠다고 생각함.
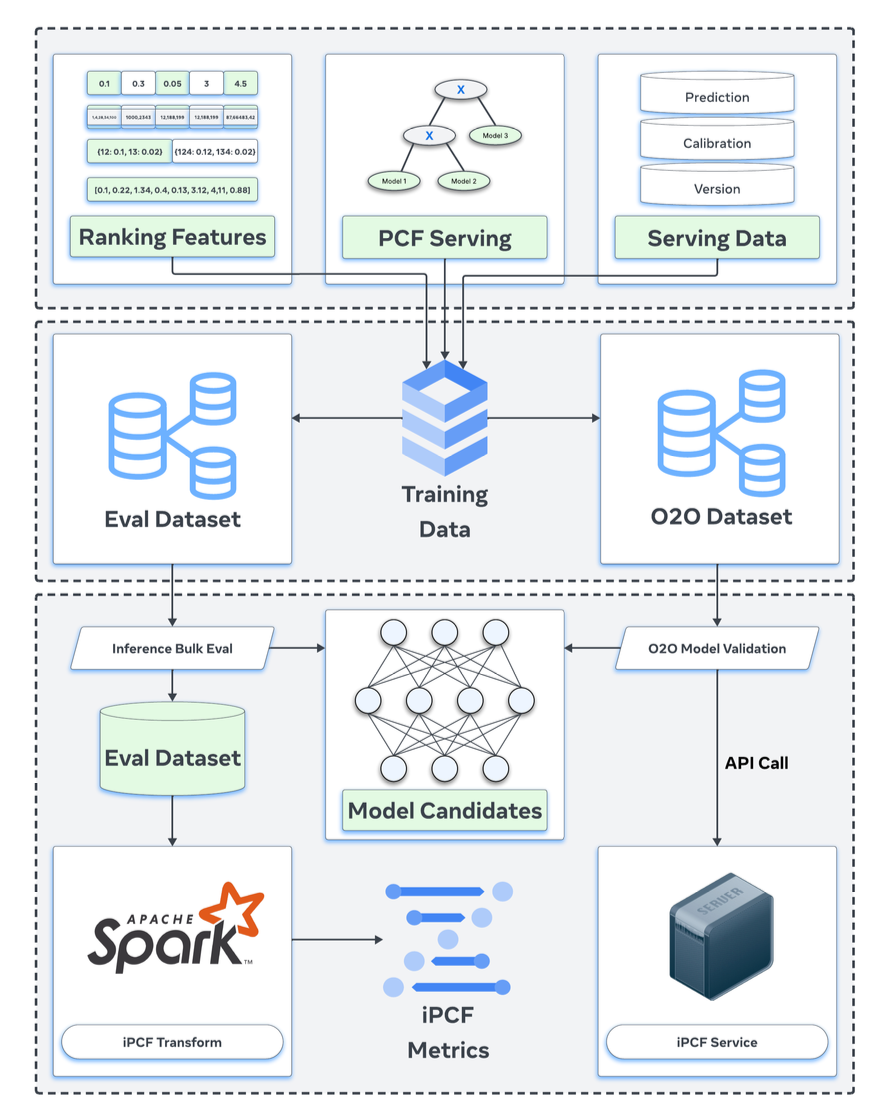
Proposal: iPCF (Intelligent Prediction Composition Framework)
- 핵심 아이디어: 과거의 동일한 (복잡한 composition) 서빙 맥락에서 이 모델을 썼다면 무슨 일이 벌어졌을까? 를 오프라인에서 시뮬레이션하자.
- 이때 단일 모델의 예측 품질이 아니라, 실제 서빙 시 사용된 예측 조합 구조 전체를 재현해 평가하자
- detail
- configuration versioning
- 서빙 로직(예: eCVR 합성식)은 시시각각 바뀌므로, 과거의 “정확히 그 로직”을 모르면 재현 불가함
- 서빙-time prediction composition(PCF)을 버전된 트리(tree)로 만들고, 각 트리에 고유 ID를 부여해 중앙 DB에 저장. 로그에는 그 PCF version ID가 찍힘
- data augmentation
- 모델 학습 & 평가 데이터에 feature, label외에도 PCF version ID, serving시 raw model prediction, PCF tree하에서 각 모델 출력이 어떻게 꽂히는지 등을 포함함
- candidate inference & simulation
- 과거 요청에 대해 해당 PCF version tree를 오프라인 DB에서 가져온다. 그다음 평가하고 싶은 새로운 모델 예측을 정확히 PCF tree안에 서빙시와 동일하게 주입하고 나머지 부분은 당시 예측을 그대로 사용해 최종적인 eCVR을 재합성
- 이렇게 얻은 재합성 eCVR을 이용해 서빙과 정렬된 방식으로 오프라인 평가를 계산 = iPCF NE
- configuration versioning
- system architecture
- 공용 시뮬레이션 코어 라이브러리 사용(온라인/오프라인 둘다 동일하게 구현을 맞춤)
- Spark 기반 대규모 배치 평가
- Stateless RPC 서비스
- Training loop 통합
- 🪄 applications
- 후보 모델의 평가를 서빙 기준으로 바꾼다.
- post-composition 성능을 평가할 수 있다. (각 모델 지표는 좋았는데 합치면 망하는 경우를 찾아냄)
- 비용이 드는 온라인 테스트에 대한 의존도를 낮춘다.
- 서빙 정책(eCVR 합성식의 weight 등의 hyper parameter)을 튜닝할 수 있다.
- 추가 온라인 실험 없이 서빙 로직의 하이퍼파라미터 튜닝을 통해 매출 +0.03% 개선 달성하기도 했음
- 후보 모델의 평가를 서빙 기준으로 바꾼다.
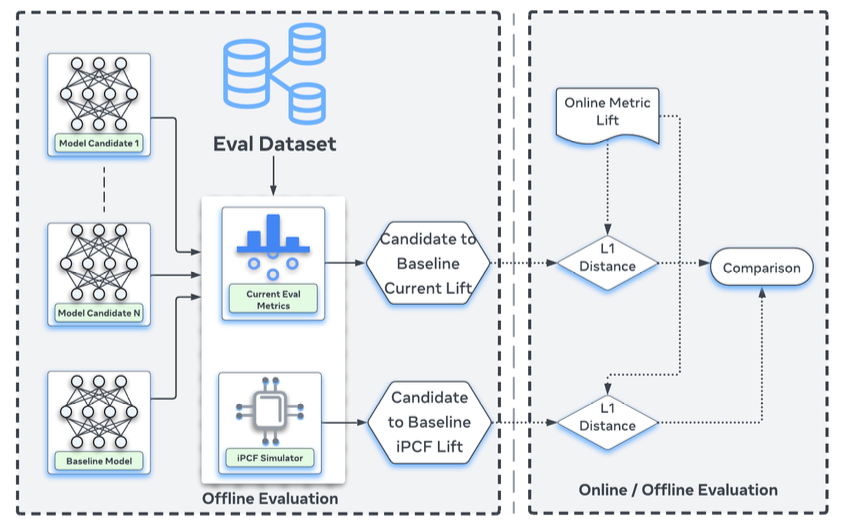
Results
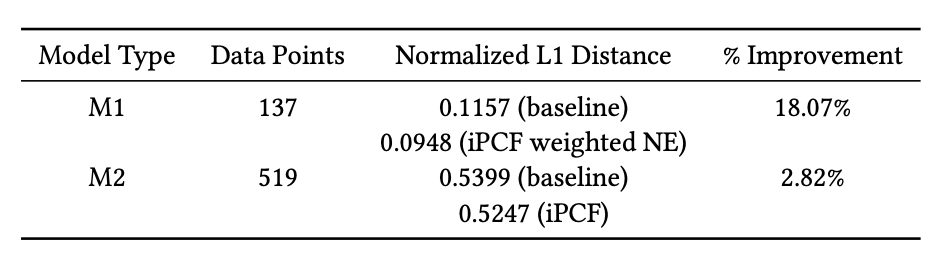
- Meta 광고 시스템의 두 개 핵심 모델(M1, M2) 에 적용
- iPCF 기반 오프라인 지표가 온라인 실험 결과와의 L1 거리를 최대 18%까지 감소 → 오프라인-온라인 상관성 유의미하게 개선
- 이건 모델의 성능이 아니라 온라인 지표가 오프라인 지표로 예측될 때 얼마나 틀리느냐를 18% 감소한것임
- offline lift: 신규 모델 오프라인 성능 - 베이스라인 오프라인 성능
- online lift: 신규 모델 온라인 성능 - 베이스라인 온라인 성능
- online lift는 offline lift에 의해 선형적으로 예측된다고 가정함 (predicted online lift = beta * offline lift, beta는 leave-one-out방식으로 추정)
- 모든 후보 모델에 대해 predicted online lift - actual oneline lift를 계산하고 평균낸 l1 distance를 봤을 때 이게 18% 감소했다
- 이건 모델의 성능이 아니라 온라인 지표가 오프라인 지표로 예측될 때 얼마나 틀리느냐를 18% 감소한것임