배경
- Search와 Recommendation은 이론적으로 “같은 동전의 양면”이지만, 실제로는 별개 시스템으로 운영되어 왔음
- Exploratory search (탐색형 쿼리): 좁은 intents (특정 곡/아티스트)가 아닌, 폭넓은 선호를 표현하는 쿼리
- “italian 80s nostalgia”, “new podcasts for me”, “composers like Mozart”
- 이런 쿼리는 추천 태스크에 가까움 (넓은 후보군 + 유저 선호 기반 shortlist)
- 전통적인 검색 시스템의 한계
- lexical/semantic matching에 최적화, personalization은 re-ranking 단계에만 반영
- 반면 추천 시스템은 user-item / item-item 유사도를 통해 exploratory 쿼리에 더 적합
- lexical/semantic matching에 최적화, personalization은 re-ranking 단계에만 반영
- Agentic 접근법의 가능성
- LLM의 강한 query understanding + multilingual reasoning
- Tool 호출(API routing)을 통해 적절한 downstream service로 동적 routing
- 단, 수백만 유저를 대상으로 하는 프로덕션 환경에서의 scalability가 핵심 도전이었음
Parallel Fusion Router (PFR)
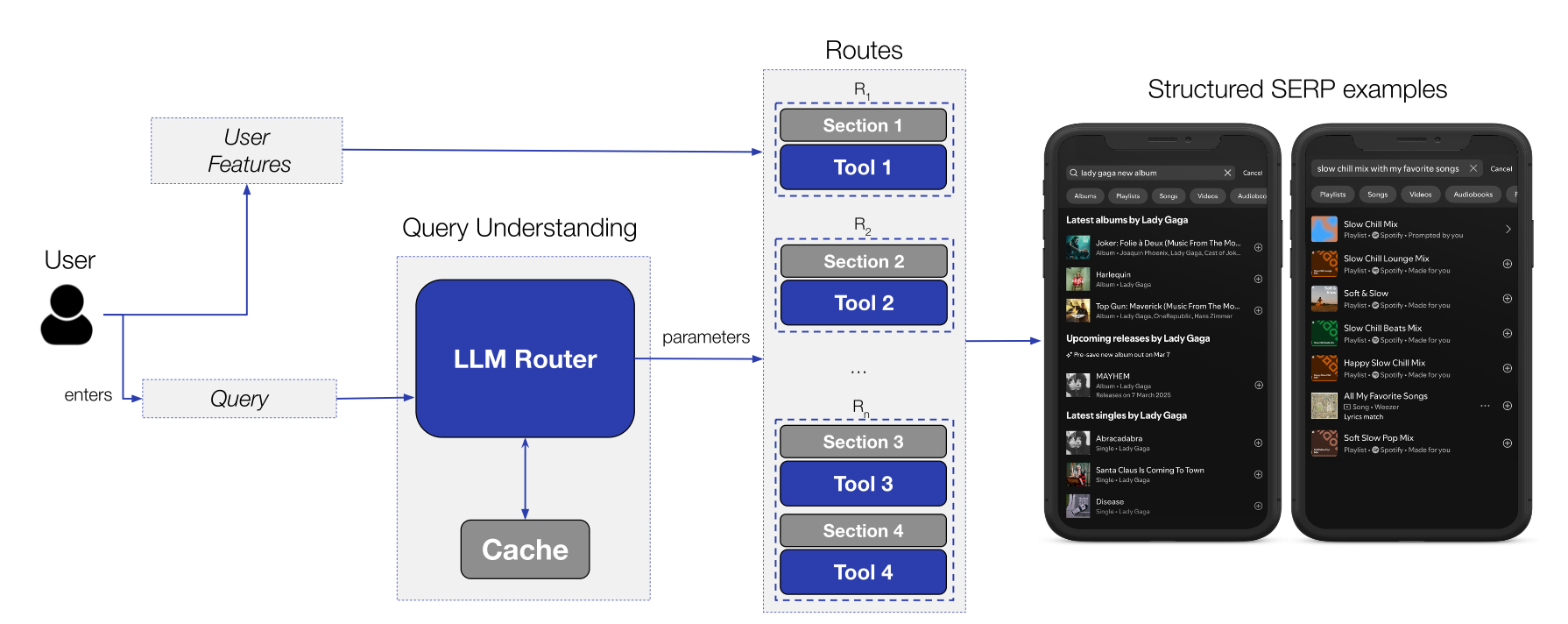
- LLM router가 query + user features를 입력으로 받아 적절한 route를 선택
- 각 route는 하나 또는 여러 개의 병렬 tool call에 대응
두 가지 동작 모드
- Pre-fusion 모드: 가능한 route(bundle)를 미리 정의 → LLM이 파라미터만 생성, 출력 토큰 수 최소화 → 빠르고 효율적
- → scalability 요건 충족을 위해 이 모드 채택
- Post-fusion 모드: LLM이 런타임에 동적으로 tool 조합 → 유연하지만 latency 증가
멀티 인텐트 처리
- 예: “latest albums by Lady Gaga” → 가능한 인텐트 3가지
- 최신 앨범 찾기
- 앨범 발매 여부 확인
- “album”을 네비게이션 힌트로 쓴 싱글 검색
- 세 가지 tool call을 병렬로 실행 → 각 결과를 SERP의 별도 섹션에 배치
- 단순히 가장 가능성 높은 인텐트만 충족하는 것이 아니라, 덜 명시적인 goal도 함께 커버
Caching 전략
- LLM router에는 user features 없이 query만 전달 → cache hit rate 극대화
- User features는 downstream tool(search/rec API)에 전달 → 개인화는 tool이 담당
- → LLM은 personalization을 직접 하지 않고 intent 분류와 query 파라미터화에만 집중
Query Understanding (LLM의 부산물)
- LLM router가 route를 선택하면서 동시에 query 이해를 수행
- query rewriting, expansion, facet extraction이 tool call 파라미터 생성 과정에서 자연스럽게 처리
- 예: “new indie rock releases” →
{"route": "personalized_recs", "genre": "indie rock", "entity_types": ["track", "album"], "max_weeks_from_release": 4}
- 전통 시스템에서 여러 dedicated classifier + re-ranker로 구현하던 것을 LLM 하나로 대체
Downstream Tools 구성
- 전통 ML-based retriever/ranker: search/rec API (user-item, item-item similarity 활용)
- Sub-agent (AI DJ): 추가 LLM 호출 수행, broad music search 시 사용자 쿼리 기반 on-the-fly 음악 세션 생성
- LLM은 필요할 때만 호출 (external knowledge, complex reasoning, SERP refinement 필요 시)
Post-training
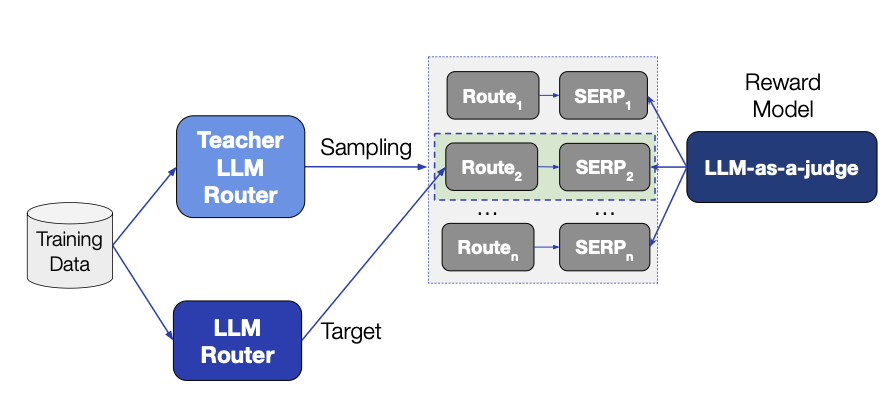
전통 LLM 프롬프팅 방식은 높은 latency/cost 문제가 있음 → 작은 LLM을 fine-tuning해 효율화
프로세스
- Training data: real + synthetic 예시 혼합 (evaluation set과 분리)
- Teacher LLM: 강력한 LLM을 프롬프팅해 각 예시의 correct routing 결정 생성
- high temperature로 샘플링 → 다양한 후보 확보
- RFT (Rejection sampling Fine-Tuning):
- Reward model로 낮은 품질의 샘플 필터링
- Reward model = LLM-as-a-judge (PASS/NO PASS 평가)
- PASS 받은 응답만 fine-tuning 데이터로 사용
- Fine-tuned 소형 LLM router: 더 큰 teacher LLM의 성능을 smaller 모델로 재현
성능 비교 (Teacher LLM 대비 offline 상대적 개선)

- Post-training은 품질까지 소폭 향상하면서 latency 60%, cost 99% 감소
- 동일 모델 대비 prompt 방식보다 post-training이 더 빠른 이유: input context 크기 축소
평가
Offline: LLM-as-a-judge
- 강력한 LLM (real-time world knowledge 보유)이 SERP 품질 평가
- 입력: query + user profile + 반환된 items (title, artist, genre, release date 메타데이터 포함)
- 평가 차원: relevance, diversity, freshness
- 출력: absolute score (PASS/NO PASS) 또는 pairwise preference (X better than Y)
- Test set: real + synthetic query-user pair 혼합
Online: user interaction signals
- clicks, streams 등 실제 유저 행동 지표
운영 guardrail
- latency, cost 지속 모니터링
결과

- 주요 영어권 국가에 production 배포, p75 latency ~450ms 달성
- Broad music searches는 AI DJ sub-agent가 on-the-fly 음악 세션 생성으로 처리
- 이후 여러 Spotify search 경험 플랫폼으로 rollout 확대
핵심 설계 포인트 정리
- LLM을 query understanding에만 집중: personalization은 downstream tool이 담당 → caching 효과 극대화
- Pre-fusion route bundle: 유연성보다 scalability 우선 → production 요건에 적합
- Post-training으로 비용 해결: LLM 기반 시스템의 가장 큰 pain point(latency, cost)를 teacher-student + RFT로 해소
- Sub-agent 선택적 호출: 모든 쿼리에 LLM을 쓰지 않고, 복잡한 reasoning이 필요한 경우에만 추가 LLM 호출