Never Miss an Episode: How LLMs are Powering Serial Content Discovery on YouTube (2025)
Note
Few-shot LLM 프롬프트만으로 시리얼 플레이리스트를 식별해, 기존 REG-EXP 대비 25% 더 많은 시리얼 플레이리스트를 찾아내고 satisfied engagement +0.39%를 달성함
- 학습 데이터 없이 few-shot 프롬프트만으로 recall 100%를 달성 (Gemini V2 XS 기준)
- 단순 분류 과제에서 Persona/Reasoning 추가는 precision을 오히려 낮추거나 무효했음. 명확한 objective가 핵심
Background
- YouTube에서 시리얼 콘텐츠(드라마, 에피소드 시리즈 등)는 순서대로 시청해야 하는 핵심 유저 여정
- 기존 시리얼 식별 방법은 두 가지:
- Creator 태깅: 크리에이터가 직접 플레이리스트를 serial로 표시 → 부정확하거나 누락 많음
- REG-EXP 시스템: 엔지니어가 수동으로 정규표현식을 관리 → high precision, low recall
- REG-EXP는 플레이리스트에 추가되지 않은 시리얼 콘텐츠의 30%만 식별 가능
- 국제(비영어) 콘텐츠 및 새로운 패턴에 대한 일반화 실패
- BERT 등 기존 텍스트 분류 모델은 대규모의 레이블링된 학습 데이터 필요 → 생성 비용 과다
플레이리스트 유형 정의:
- 세 가지 플레이리스트 유형
- Episodic:Serial e.g. Hell’s Kitchen Season 20
- Episodic:Non-Serial e.g. Hot Ones
- Not Episodic eg. Chill Songs
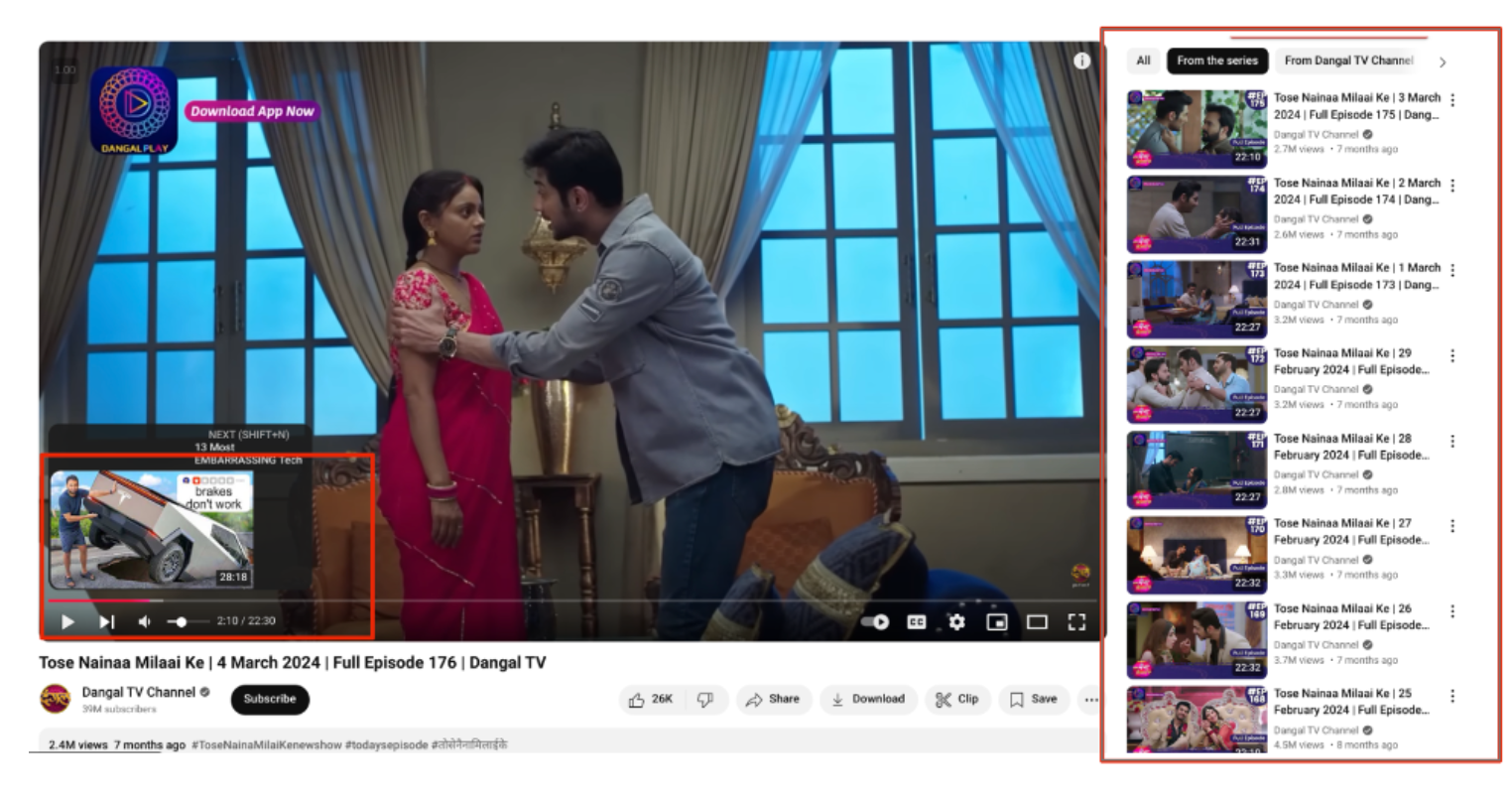
- 기존 시스템이 “다음 에피소드”를 잘못 추천하는 사례: 시리얼 시청 중 시리즈와 무관한 영상이 추천됨 → 유저 경험 저하의 동기를 시각화
Method
- Multi-headed few-shot LLM classifier: 플레이리스트의 첫 5개 영상 제목을 입력으로 받아 세 가지를 동시 예측
- Episodic 여부 (Yes/No)
- Serial 여부 (Yes/No)
- 에피소드 순서 (Ascending/Descending/None)
- 프롬프트 설계 핵심: 손으로 선별한 in-context 예시 몇 개만 사용 (few-shot)
- 긍정 예시 (serial): 에피소드 번호가 명확한 플레이리스트
- 긍정 예시 (episodic non-serial): “Hot Ones” 스타일
- 출력 형식:
Episodic - Yes <> Serial - Yes <> Order - Descending

- 실제 사용된 few-shot 프롬프트 전문
- 두 개의 완성된 예시 뒤에 실제 추론할 플레이리스트 제목들을 제시하는 구조로, 간결하고 명확한 출력 포맷 강제
- 오프라인 배치 파이프라인: 소형 LLM으로 inference 수행 후, 식별된 시리얼 플레이리스트를 추천 엔진에 전달
- 사용 모델: Gemini V2 계열 (S: 24B / XS: 8B)로 품질과 자원 효율의 균형 고려
Experiments
프롬프트 튜닝
- 평가용 golden set: YouTube 플레이리스트 코퍼스에서 수백 개 수동 레이블링
- 튜닝 모델: Gemini V2 S
분류 objective 명확성의 중요성:
- Episodic 최고 precision: 66% / Serial 최고 precision: 77%
- “Serial” (순서 있음 여부)이 “Episodic” (에피소드 형식 여부)보다 훨씬 더 명확한 objective → LLM 성능 직결
- “Episodic”은 형식적/주관적 판단이 필요한 반면, “Serial”은 순서 의존성이라는 명확한 기준이 있기 때문
Persona/Reasoning 추가 실험:
- Persona 추가(imagine you are a film critic) 시 Episodic precision이 67.62% → 55.26%로 급락 (Serial은 거의 변화 없음)
- film critic은 솔직히 누가 봐도 도움 안 될 것 같은 페르소나긴 함..
- Reasoning 추가(Please show your work with reasoning)도 Episodic precision 소폭 하락, Serial은 무효
- 결론: 단순한 분류 태스크에서 persona/reasoning은 오히려 노이즈 → 최종 프롬프트에서 제거
모델 크기 vs 품질 vs 자원
- Gemini V2 S (24B): Accuracy 82%, Precision 76.39%, Recall 96.29%, ~256 TPUs
- Gemini V2 XS (8B): Accuracy 79%, Precision 69%, Recall 100%, ~128 TPUs
- XS 모델이 절반의 자원으로 comparable한 성능 → 프로덕션에 XS 채택
-
- recall 100%는 golden set 기준이며, false negative가 0이라는 뜻
프로덕션 배포 결과
- LLM이 크리에이터 태깅 시리즈 플레이리스트의 30% 를 실제 시리얼로 (재)분류
- 즉 크리에이터 태깅이 부정확했거나, LLM이 creator label을 정제한 셈 → 이부분은 일부 human eval로라도 확인했어야 하지 않나
- REG-EXP 대비 시리얼 플레이리스트 식별 25% 증가
- 증가분의 74%: 외국어 시리얼 플레이리스트 (REG-EXP의 핵심 약점)
- 증가분의 12%: REG-EXP가 커버하지 못한 새로운 패턴
- 증가분의 14%: 오탐 (false positives)
온라인 실험:
- Satisfied Engagement: +0.39%
- Daily Active Users: +0.02%
- 시리얼 콘텐츠 발굴 개선이 실제 유저 참여도 향상으로 이어짐