How Well Does Generative Recommendation Generalize? (2026) @Meta
Note
GR 모델이 기존 item ID 기반 모델보다 일반화를 잘한다는 가설을 체계적으로 검증
- 기존 연구는 GR의 성능 우위를 “더 나은 일반화”로 뭉뚱그렸지만, 이 논문은 데이터 인스턴스를 memorization/generalization으로 분류해 모델별 강약점을 분리해서 분석함
- GR의 item-level generalization은 사실상 token-level memorization으로 환원됨
- item ID 모델과 semantic ID 모델을 합쳐 adaptive한 ensemble 모델을 만들 수 있고 성능 향상을 확인
Background
- Generative Recommendation (GR): item을 단일 unique ID 대신 semantic ID(sub-item 토큰 시퀀스)로 표현하고, 다음 item을 autoregressive하게 생성하는 패러다임
- 대표 모델: Semantic IDs, Generative Retrieval (TIGER)
- 기존 ID 기반 모델보다 전체 성능이 높다고 알려져 있고 보통 generalization을 잘해서 그렇다고 함 → 진짜 그런가?
- 기존 연구는 cold-start item(rare/unseen target)만 분석해서 GR이 cold item에서 잘하니 일반화를 잘한다고 했었음
- 이 연구는 item transition이라는 프레임으로 봄 = 인기 있는 item이라도, 특정 history에서 해당 item으로의 transition은 training에서 한 번도 등장하지 않을 수 있어 이를 맞히려면 일반화 능력이 필요할 수 있음
Method
분류 프레임워크: Item Transition 기반
- Item Transition: , 유저 히스토리에서 에서 로의 방향성 있는 쌍
- Hop count: 와 사이의 거리. 이면 1-hop
- A→B→C 순으로 소비했을 때 A→C는 2-hop transition
- 각 테스트 인스턴스 를 training data 내 transition 패턴 유무로 분류
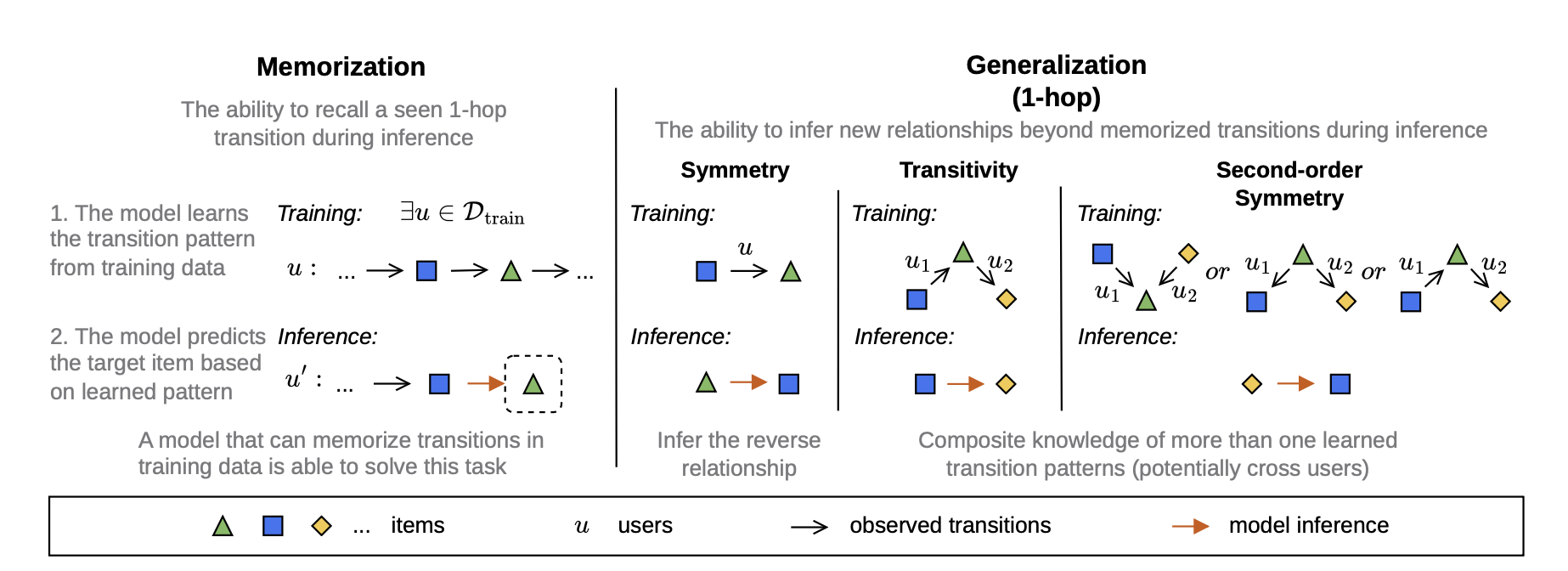
Memorization
- 1-hop transition이 training에 등장했으면 → 단순 암기로 맞출 수 있음
Generalization
memorization이 아닌 경우에만 해당:
- Transitivity: 중간 item 를 통해 와 가 각각 training에 존재 (다른 유저)
- 두 개의 학습 예시를 조합해야 함
- Symmetry: 역방향 이 training에 존재
- 단일 학습 예시에서 역관계를 추론해야 함
- 2nd-Order Symmetry: 중간 item 를 통한 복잡한 대칭 관계 (common cause / common effect / reverse path)
Multi-hop Generalization
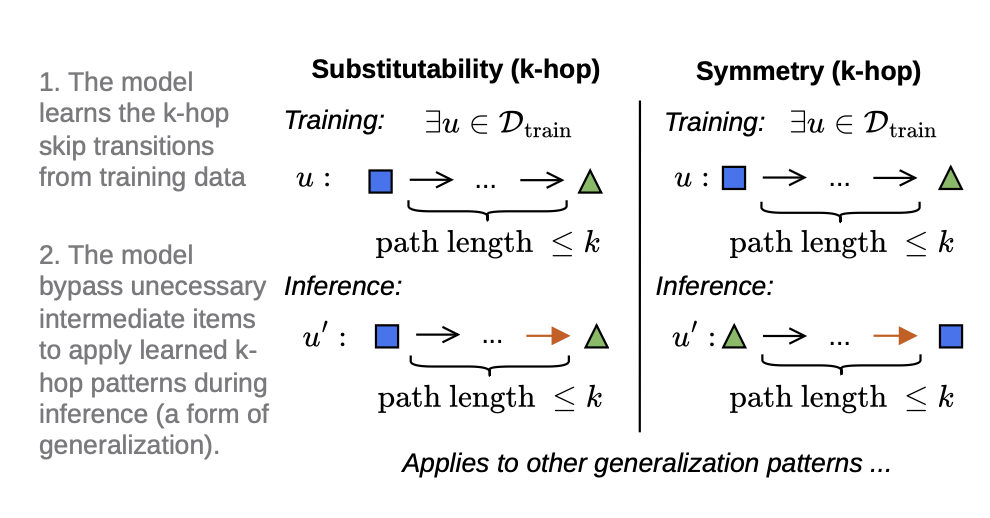
-
“multi-hop memorization”은 사실 memorization이 아닌 generalization의 일종 → 불필요한 중간 item을 건너뛰는 능력, 다른 길이의 시퀀스에서 패턴을 끌어오는 능력이 필요하기 때문
-
Substitutability: 인 k-hop transition 가 training에 존재
- Transitivity와의 차이는 같은 유저 시퀀스 안에 있는 Multi-hop sequence라는 점
Uncategorized
- 위 어떤 범주에도 해당하지 않는 인스턴스 (최대 hop count=4 기준)
- training에 없는 item, 더 높은 차수의 패턴, 또는 근본적으로 예측 불가한 경우
Prefix N-Gram Memorization (Token-level 분석)
GR 모델이 왜 item-level generalization에서 강한가를 설명하기 위해 토큰 레벨로 분석 단위를 내림.
- Token Prefix: — semantic ID의 앞 개 토큰
- Prefix N-Gram Memorization: 정확한 item transition은 아니더라도, 두 item의 n-gram prefix transition이 training에 존재하면 token-level memorization으로 간주
- Semantic ID는 계층적(coarse-to-fine) 의미 정보를 인코딩 → prefix가 같은 item들은 의미적으로 유사 → item이 다르더라도 prefix가 일치하면, GR 모델은 해당 prefix transition을 “암기”해서 새 item 조합에 적용 가능
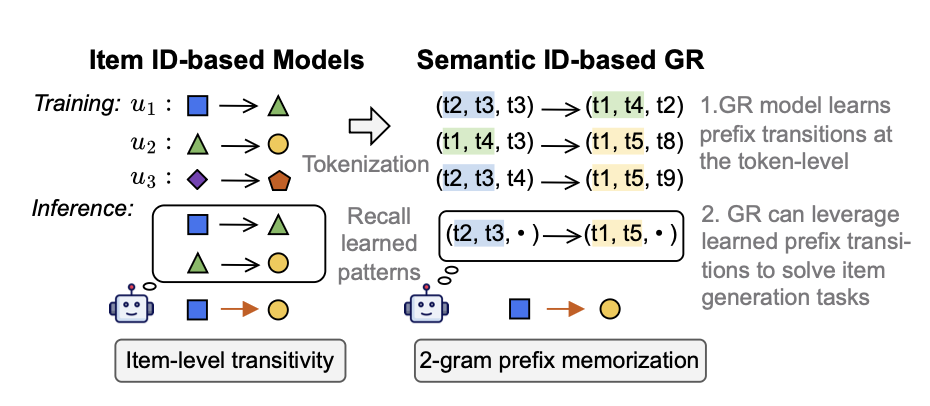
- SASRec은 item ID 전체를 직접 학습하므로 이 메커니즘이 불가능함. TIGER는 prefix 공유 덕분에 unseen item transition에서도 추론 가능
Adaptive Ensemble
두 패러다임이 보완적임을 확인하고, 인스턴스별로 가중치를 조정하는 앙상블 구성.
- 핵심 아이디어: memorization likelihood가 높은 인스턴스 → ID 모델에 더 높은 가중치, 낮은 경우 → GR 모델에 더 높은 가중치
- Indicator: Maximum Softmax Probability (MSP) - ID 기반 모델의 최대 예측 확률
- memorization-related 인스턴스는 training distribution에 가까워 ID 모델이 더 confident → MSP가 memorization likelihood proxy로 유효
- Ensemble weight:
- 가 클수록 GR 모델 비중 증가, 작을수록 ID 모델 비중 증가
- Hyperparameter: ,
- Training-free (추가 학습 없이 inference 시점에 적용 가능)
Experiments
실험 설정
- 7개 공개 데이터셋 (Sports, Beauty, Science, Music, Office, Steam, Yelp) 사용
- 대부분 sparsity 99.9% 이상, AvgLen 8~12
- 모델: TIGER (GR 대표) vs SASRec (ID 기반 대표)
- SASRec은 공정 비교를 위해 cross-entropy loss + all-item negative 방식으로 학습
- 분류: memorization / generalization / uncategorized (상호 배타적)
- 단, generalization 유형은 중복 가능 → 비율 합이 100% 초과 가능
Performance Breakdown
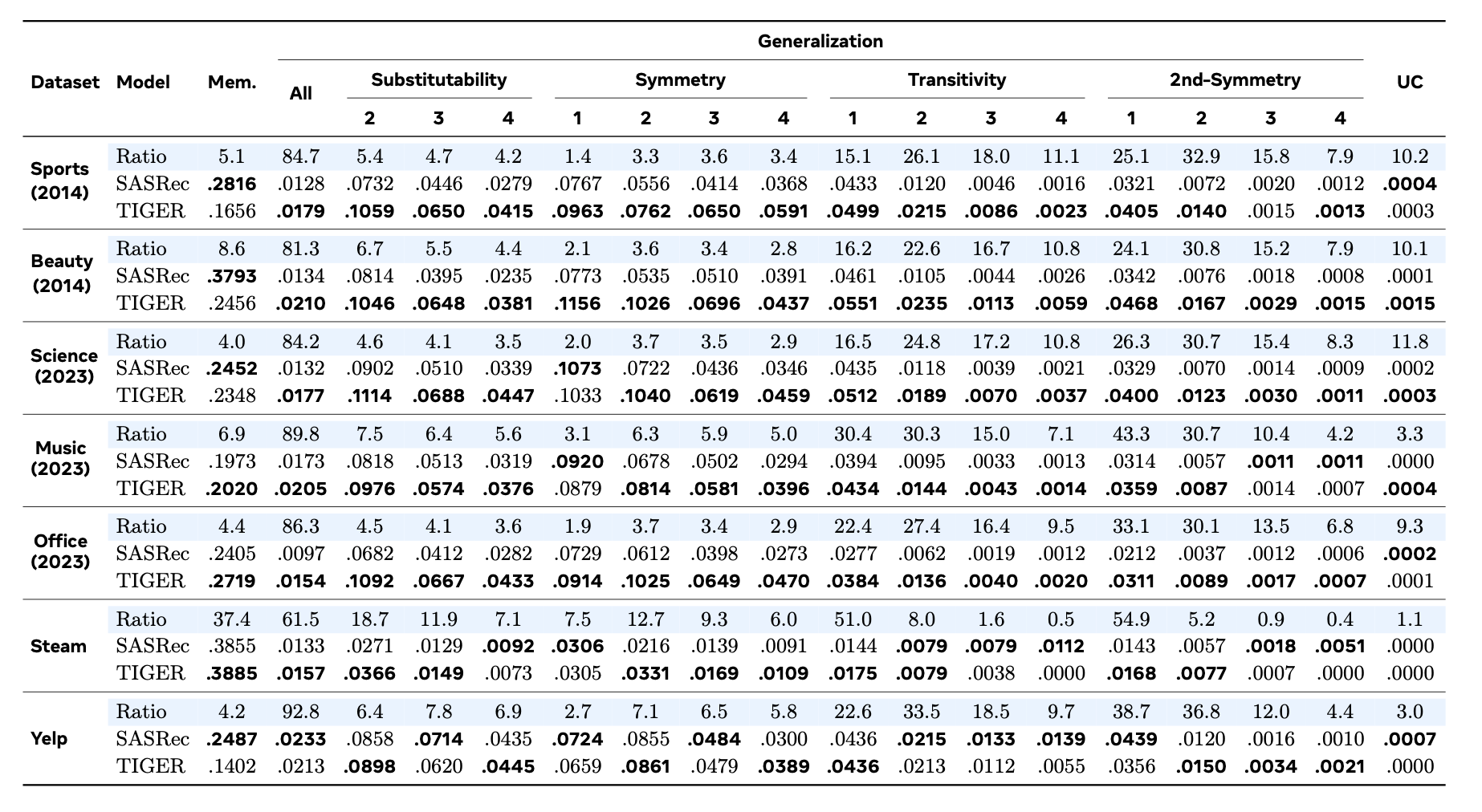
- 7개 데이터셋 × 2개 모델의 NDCG@10을 memorization/generalization 카테고리별로 분해
주요 결과
- SASRec: memorization에서 일관되게 강함 / TIGER: generalization에서 일관되게 강함
- TIGER가 SASRec 대비 memorization subset에서 열세: Yelp −43.6%, Sports −41.2%, Beauty −35.2%
- TIGER가 SASRec 대비 generalization subset에서 우세: Office +58.8%, Beauty +56.7%, Sports +39.8%
- 두 모델 모두 memorization > generalization in absolute performance → generalization 자체가 어려운 태스크
- Uncategorized에서 두 모델 모두 near-zero → 이 인스턴스들은 실제로 예측하기 어려움
Generalization 유형별 난이도
- Substitutability, Symmetry > Transitivity, 2nd-Symmetry (성능이 더 높음)
- Substitutability/Symmetry는 단일 training 예시에서 추론 가능; Transitivity/2nd-Symmetry는 여러 예시 조합 필요
Hop distance 효과
- hop이 커질수록 두 모델 모두 성능 단조 감소
- SASRec은 낮은 hop에서 TIGER를 이기기도 하지만 hop 증가 시 더 급격히 하락 → 로컬 컨텍스트 의존적
- TIGER는 장거리 hop에서 더 robust
데이터 분포
- 대부분 데이터셋에서 memorization 비율이 매우 낮음 (4~37%, Steam 제외)
- 효과적인 추천을 위해 generalization이 필수적임을 시사
Token-Level 메커니즘 분석
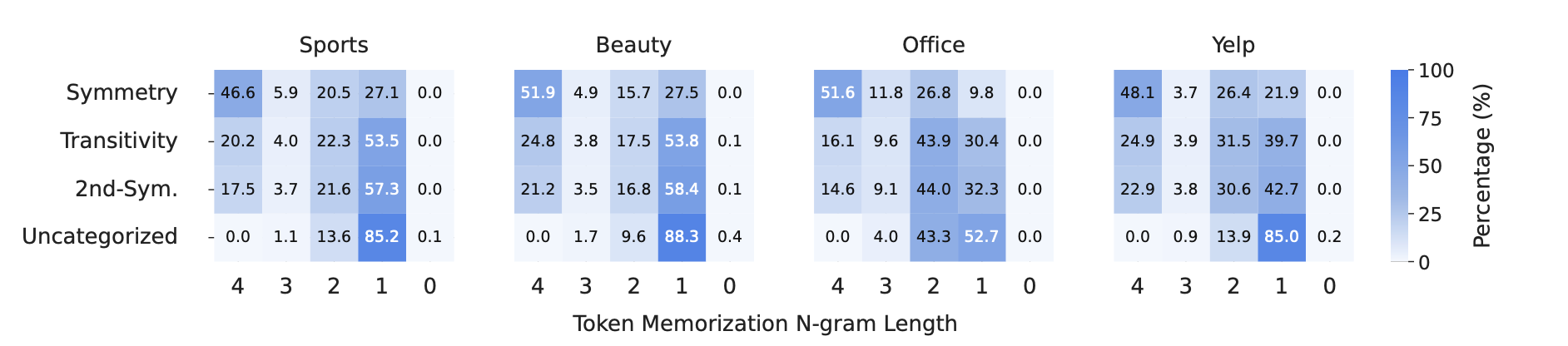
- item-level generalization 카테고리별 token memorization 비율 (n-gram prefix 길이별)
- 99% 이상의 인스턴스가 최소 1-gram prefix memorization에 해당 → item transition이 unseen이어도 prefix transition은 training에 존재
- 청바지A → 운동화B는 exact하게는 존재하지 않지만 청바지계열 → 운동화계열은 본적이 있다는 것
- 99% 이상의 인스턴스가 최소 1-gram prefix memorization에 해당 → item transition이 unseen이어도 prefix transition은 training에 존재
![]()
- prefix transition count vs NDCG@10 (Beauty, Office)
- token memorization support가 많을수록(prefix transition이 많이 등장했을수록) TIGER 성능 향상; SASRec과의 격차도 prefix support 증가 시 확대
Dilution Effect
![]()
- token memorization이 item memorization을 희석시킴
- item transition probability 와 prefix transition probability 에 따라 TIGER의 SASRec 대비 advantage를 본 것
- 높고 낮음 → 같은 prefix를 공유하는 많은 item으로 확률 질량이 분산 → specific item transition 암기 어려움
- 높음 → TIGER가 SASRec을 이기기도 함
Codebook size 조절 실험
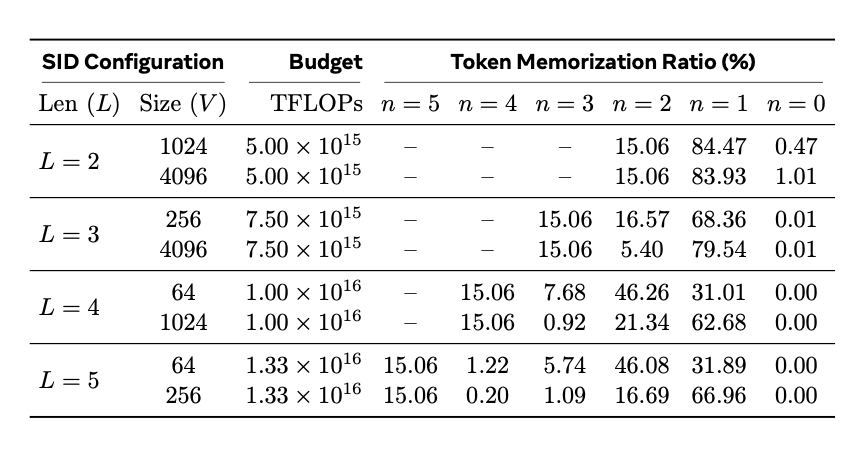
- SID length 과 codebook size 를 변경했을 때 token memorization ratio 변화
- 작은 → denser codebook → 더 많은 prefix 공유 → token memorization ratio 증가 → generalization은 올라가고 memorization은 감소
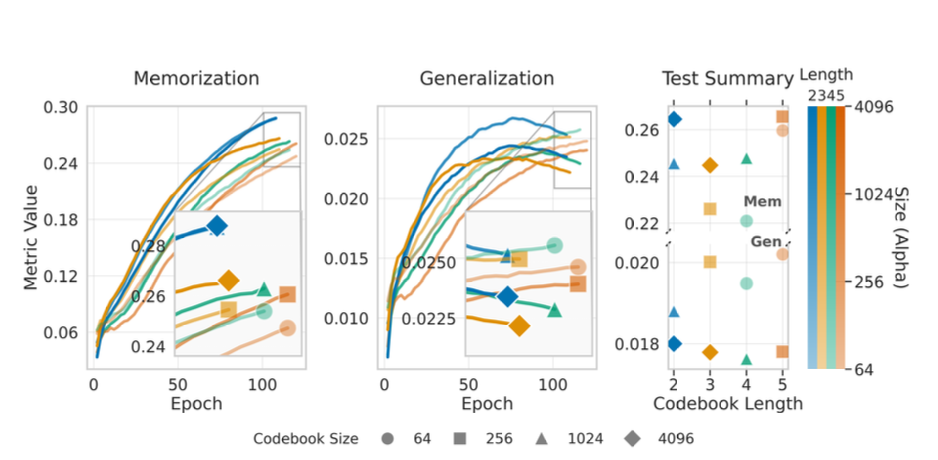
- 작은 : generalization +10.24% (평균), memorization −7.62% (평균)
- 작은 에서 generalization이 학습 내내 안정적 or 개선; 큰 에서는 early peak 후 degradation → denser tokenization이 regularization 효과
Adaptive Ensemble 결과
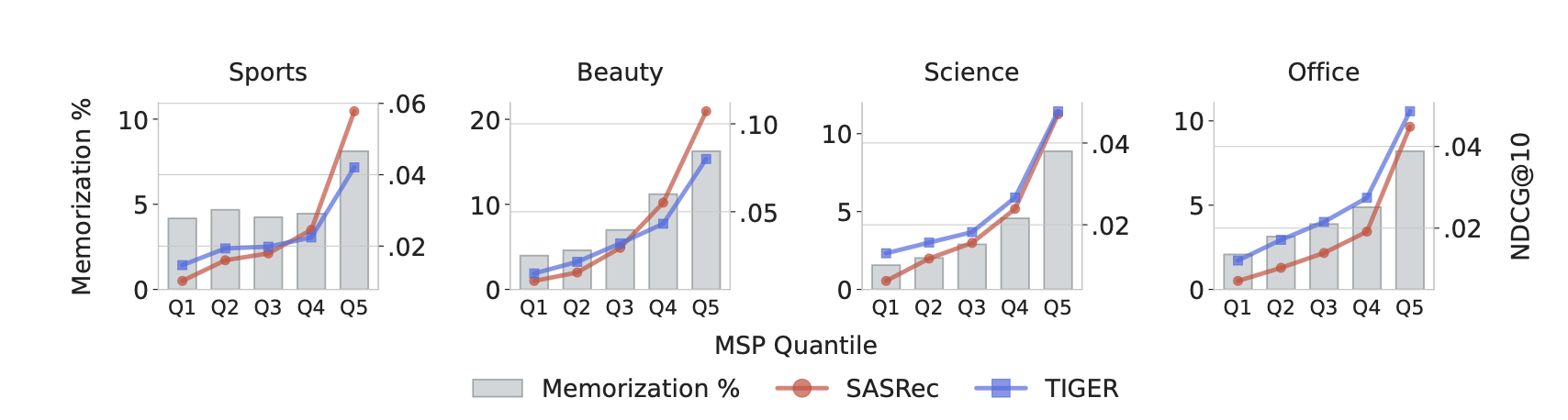
- MSP quantile이 증가할수록 memorization 인스턴스 비율 단조 증가 → indicator 유효성 확인
- 낮은 MSP quantile에서 TIGER 우세, 높은 quantile에서 SASRec 우세 → performance crossover 패턴
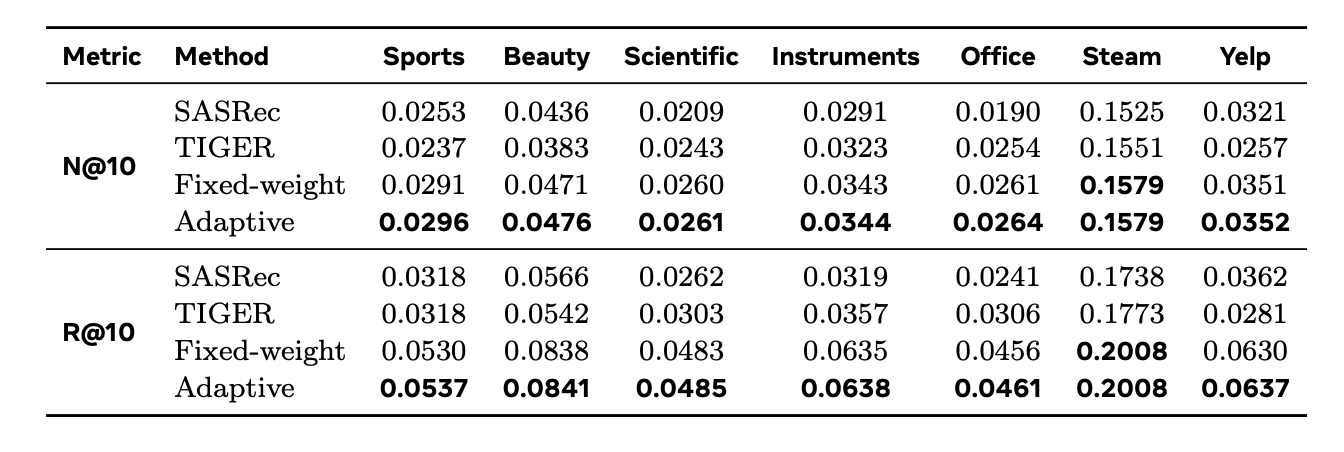
- Adaptive ensemble이 SASRec, TIGER, Fixed-weight ensemble 모두를 일관되게 상회
- R@10 기준 향상 폭이 더 큰 경향 (고정 가중치 앙상블도 개별 모델 대비 큰 폭 향상. 사실 앙상블>>>앙상블 안함 차이가 크고 adaptive > fixed는 미미함)
- model cross-over 효과가 강한 (위 그림에서 선이 뚜렷하게 교차하는 = 두 모델이 각자 잘하는 영역이 나뉘는) 데이터셋일수록 adaptive ensemble의 개선폭이 더 큼
💭
- GR의 generalization이 실제로는 token-level memorization이라는 발견 = 즉, semantic ID를 쓰는 것 자체가 item space를 coarse-grained 공간으로 압축하는 효과를 내고 이게 cross-item 일반화처럼 보이는 것