Deploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify (2026)
Note
Spotify의 팟캐스트 추천에서 Semantic ID + LLM 기반 생성형 추천 시스템 GLIDE를 프로덕션에 배포하여 non-habitual 스트리밍 +5.4%, 신규 쇼 발견 +14.3%를 달성
- Semantic ID를 LLM 어휘에 직접 추가해 대규모 동적 카탈로그를 grounding하고, Residual K-Means 양자화로 안정적·효율적으로 SID를 구성
- collaborative filtering 유저 임베딩을 soft prompt로 주입해 프롬프트 길이를 늘리지 않고 장기 선호도를 반영
- familiar/unfamiliar 두 discovery 목표를 control token 하나로 단일 모델 내에서 전환 가능하게 설계
Background
- 팟캐스트 청취는 습관적 소비와 탐색 욕구가 공존
- 사람들은 이미 구독한 쇼에 주로 돌아오면서도, 출퇴근·간식 시간 등 맥락에 따라 전혀 다른 콘텐츠를 원하기도 함
- 기존 추천 시스템은 장기 interaction 패턴 위주 → 맥락 변화와 discovery 목표에 취약
- LLM은 시퀀스 모델링·instruction conditioning·풍부한 사전 시맨틱 표현 등에서 강점
- 다만 프로덕션 적용 시 3가지 장벽: 카탈로그 grounding(실제 존재하는 아이템만 추천하도록 묶어두는 것), 유저 수준 개인화, 지연 시간 제약
- Non-habitual streaming 정의 :
- Habitual show: 최근 28일 내 청취 시간 분
- Non-habitual but familiar: 분이지만 과거 청취 이력 있음
- Non-habitual and unfamiliar: 청취 이력 자체가 없음
- → 28일 윈도우는 단기 노이즈를 줄이면서 최근 습관을 포착하는 경험적 선택, 10분 임계값은 우발적 청취와 의미 있는 engagement를 분리
Method
전체 구조: GLIDE (Grounded LLM for Interest Discovery rEcommendations)
추천을 instruction-following 태스크로 정형화:
- 모델 입력 4종:
- 최근 청취 이력을 SID 시퀀스로 직렬화
- 자연어 토큰으로 표현된 경량 유저 컨텍스트 (locale, affinity topics 등)
- collaborative filtering 유저 임베딩을 soft prompt로 주입 (장기 선호)
- 추천 목표를 지정하는 자연어 instruction (familiar vs. unfamiliar)
- 백본: Llama 3.2 1B 기반, ~1B 이하 compact 모델로 지연 시간·비용 제약을 맞춤
- Stage 1에서 SID와 자연어의 양방향 번역으로 카탈로그 grounding, Stage 2에서 soft prompt + instruction tuning을 추가해 개인화 추천을 학습함을 보여줌
Semantic IDs (SID) 구성
- 에피소드 임베딩 소스: 제목·설명을 multilingual BGE-M3 구조 기반 전용 텍스트 인코더로 인코딩 → content-based 임베딩
- CF 임베딩 대신 content 임베딩을 쓰는 이유:
- Cold-start: 새 에피소드는 interaction 없이 즉시 추천 가능해야 함
- Stability: CF 임베딩은 유저 행동에 따라 변화 → train-serve mismatch 유발; content 임베딩은 메타데이터가 변경되지 않는 한 안정적
- CF 임베딩 대신 content 임베딩을 쓰는 이유:
- Residual K-Means (R-KMeans) 양자화:
- 레벨 마다 잔차를 가장 가까운 centroid 로 양자화:
- , → 1024개 SID 토큰, 에피소드 1개 = 4토큰 (레벨별 독립 namespace)
- 예시:
⟨SID1=13⟩ ⟨SID2=65⟩ ⟨SID3=188⟩ ⟨SID4=7⟩ - 다중 레벨 구조 → 자연스러운 coarse-to-fine 시맨틱 계층 (예: News → Sports-News) → autoregressive 생성의 inductive bias
- 레벨 마다 잔차를 가장 가까운 centroid 로 양자화:
Soft Prompt 유저 개인화
- 유저 임베딩 를 2-layer MLP로 LLM hidden dimension으로 projection:
- system instruction 바로 뒤, 유저 컨텍스트 앞에 단일 soft prompt 토큰으로 삽입
- 장점: 유저 정보를 텍스트로 직렬화하면 프롬프트가 매우 길어지는 문제를 회피하면서도 collaborative signal 보존

- continuous soft prompt와 discrete 토큰이 혼합된 hybrid conditioning 방식임을 보여줌
Stage 1: Semantic Grounding
- 문제: 새로 추가된 SID 토큰은 LLM에게 의미 없는 기호에 불과
- 새 어휘를 추가하고 곧바로 full fine-tuning → representation collapse, catastrophic forgetting 위험
- 해결: SID ↔ 텍스트 설명 양방향 번역 목표로 continued training
- → (SID에서 에피소드 텍스트 설명 생성)
- → (텍스트에서 SID 생성)
- 2-stage 안정화:
- Transformer 백본 freeze, 새 SID 토큰 임베딩만 학습
- 전체 모델 freeze 후 Transformer block에 LoRA 적용
- Soft prompt projection은 이 단계에서 제외 → collaborative signal 오염 방지
Stage 2: Instruction Tuning
- Grounding된 모델에 추천 태스크를 학습
- Multi-task: familiar/unfamiliar 두 discovery 목표를 단일 모델로 동시 학습
- control token:
familiar또는unfamiliar - 추론 시 토큰만 바꿔 목적 전환 → 재학습 불필요
- control token:
- 편향 완화 전략 3가지:
- Cross-surface sampling: 단일 서페이스의 feedback loop 방지
- Exploration upweighting: 무작위·탐색 배치에서 발생한 interaction에 높은 샘플링 가중치 → 추천 노출 편향 없는 clean signal
- Popularity capping: 특정 에피소드의 학습 기여 상한 설정 → 인기도 편향 억제
서빙 설계
- Collision resolution: 여러 에피소드가 동일 SID를 가질 수 있음 → 인기도 기반 deterministic tie-breaker (daily 업데이트)
- collision은 대개 설명이 짧거나 동일 쇼 내 유사 에피소드에서 발생
- Beam Search: 30 beams → 요청당 30개 후보 생성
- 초기 배포에서 wide-beam이 CPU 오케스트레이션 병목 + accelerator 저활용 문제 야기
- inference engine 수정 없이 오케스트레이션 레이어 스케일링 + 설정 튜닝으로 해결 → 처리량 8× 향상, beam width 14 → 30으로 확대
Experiments
평가 프레임워크
3가지 상호보완적 구성 요소:
- Retrieval Metrics: Recall@30, HitRate@30, NDCG@30 (familiar / unfamiliar 세그먼트 분리)
- Human Evaluation: Spotify 직원 어노테이터가 interest alignment, 신선도, 다양성, 친숙도 평가 + 자유 텍스트 코멘트
- LLM-judge: 유저 프로파일 + 추천 에피소드 메타데이터 + 트랜스크립트 발췌를 입력으로 topic/host/style/tone 축으로 interest alignment 점수화
Offline 결과
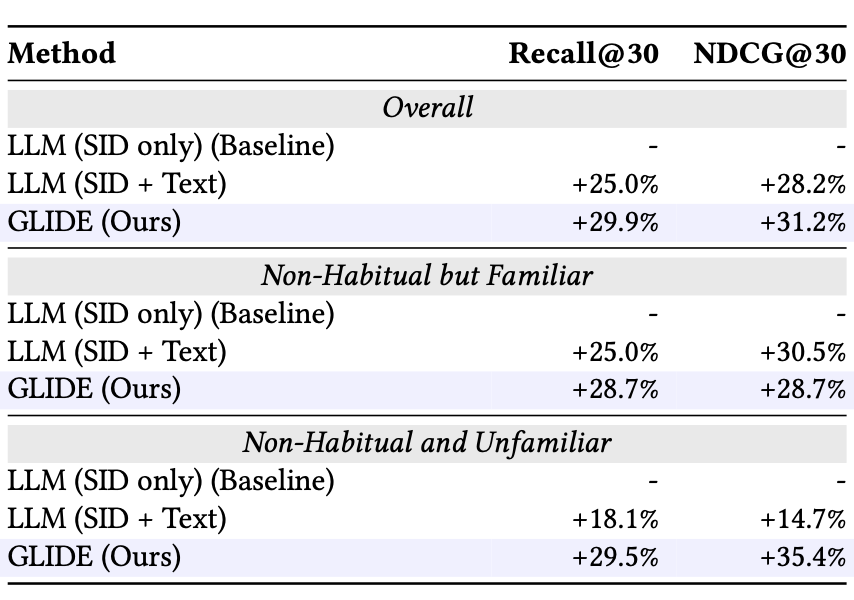
-
세 가지 방법(SID-only, SID+Text, GLIDE)의 familiar/unfamiliar 세그먼트별 Recall@30, NDCG@30 상대 개선율
- GLIDE가 전체 Recall@30 +29.9%, NDCG@30 +31.2%; 특히 Non-Habitual Unfamiliar에서 NDCG@30 +35.4% (SID+Text의 +14.7% 대비 압도적)
-
Ablation: SID quantizer 비교 (R-KMeans vs R-LFQ vs RQ-VAE)

-
세 양자화 방식의 HR@30 및 intra-bucket cosine similarity 비교
- R-KMeans가 HR@30 기준 RQ-VAE 대비 +9.52%, R-LFQ 대비 +4.76%; intra-bucket similarity도 0.856으로 가장 높아 collision resolution 품질 보장
-
R-KMeans 채택 이유: RQ-VAE·R-LFQ는 codebook collapse, 초기화 민감성 등 학습 불안정 문제 → 프로덕션 운영 복잡도 높음
-
Ablation: Multi-task controllable learning
- Unfamiliar mode: single-task 대비 Recall@30 +11.8%
- Familiar mode: +4.9%
- single-task는 더 빈번한 familiar 데이터 쪽으로 분포 collapse → control token이 두 목표를 명시적으로 분리
-
Ablation: Semantic Grounding
- Grounding 없이 바로 instruction tuning vs. 전체 GLIDE 파이프라인
- Recall@5 기준 +8.34% 향상 → SID를 의미 있는 표현으로 먼저 정렬하는 것이 중요
-
Ablation: Beam Search
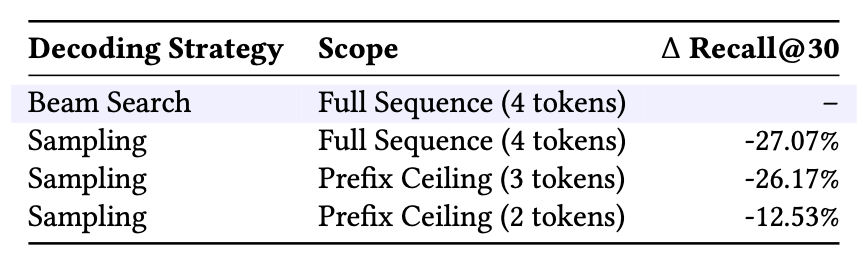
-
Beam Search vs. Sampling의 Recall@30 비교 및 Prefix Ceiling 분석
- Greedy decoding으로 교체 시 Recall@30 -27.07%
- 처음 2토큰 prefix까지는 -12.53%에 그치지만 이후 급락 → fine-grained SID 구조 탐색에 beam search가 필수
- Greedy decoding으로 교체 시 Recall@30 -27.07%
-
LLM-judge 결과
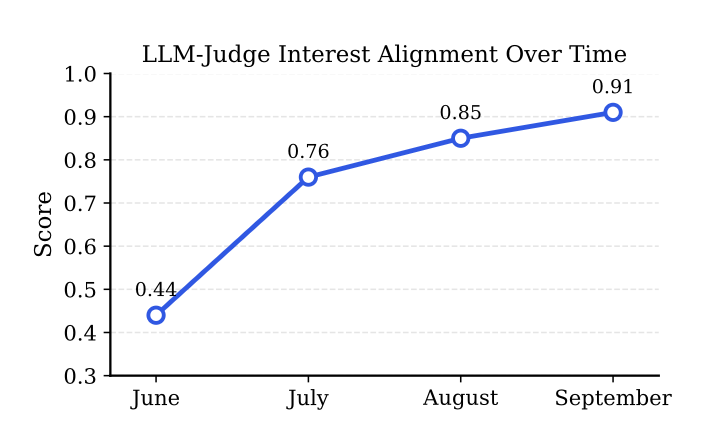
- 6월~9월 모델 개발 반복에 따른 LLM-judge interest alignment 점수 추이 (0.44 → 0.91)
- 학습 레시피·데이터 품질 개선이 지속적인 품질 향상으로 이어짐을 확인
- 한 라운드에서 LLM-judge와 인간 평가자는 동일 모델을 선호했으나 offline recall 지표는 popularity bias가 강한 다른 모델을 선호 → recall만으로 quality를 평가하는 한계 드러남
- 학습 레시피·데이터 품질 개선이 지속적인 품질 향상으로 이어짐을 확인
Online A/B Test
- 21일 랜덤화 유저 수준 실험, 영어권 시장, 약 2,000만 impressions
- 기존 프로덕션 추천 시스템(Control) vs. GLIDE를 추가 candidate retrieval source로 추가한 Treatment
- GLIDE 후보가 treatment 그룹 추천의 ~34% 차지
- 결과:
- Non-habitual 스트리밍 per user: +5.4% ()
- 신규 쇼 non-habitual 스트리밍: +14.3% ()
- 전체 engagement·유저 만족도 지표: regression 없음
- 서빙 비용·지연 시간: 할당 예산 내 유지