Note
추천 문제를 sequential transduction으로 재정의한 Generative Recommenders(GR) 프레임워크와 HSTU 아키텍처 - 1.5조 파라미터 모델을 Meta 플랫폼에 배포해 A/B 테스트 +12.4% 달성.
- DLRM의 수천 개 heterogeneous feature를 unified time series로 통합 → 수백 명의 엔지니어가 수년간 쌓은 feature engineering을 sequential modeling으로 대체
- HSTU가 FlashAttention2 Transformer 대비 training 최대 15.2x, inference 최대 5.6x 빠름 (8192 length 기준)
- M-FALCON 알고리즘으로 285x 복잡한 모델을 동일 inference budget에서 1.5x~3x 높은 QPS로 서빙
- 추천 시스템 최초로 3 orders of magnitude에 걸친 power-law scaling law 검증 (GPT-3/LLaMa-2 수준까지)
Background
- 기존 DLRM(Deep Learning Recommendation Model)의 한계
- 수천 개의 heterogeneous feature(categorical + numerical)를 사용하지만 compute 대비 성능이 잘 스케일되지 않음
- feature engineering에 크게 의존 → 수백 명의 엔지니어가 수년간 쌓아온 결과물
- 추천 시스템에서 순수 sequential 모델 적용의 세 가지 도전
- Feature 구조 부재: NLP와 달리 추천 시스템의 feature는 explicit 구조가 없고 heterogeneous함
- Billion-scale 동적 vocabulary: NLP의 100K 정적 vocabulary와 달리, 추천은 매 분마다 새로운 아이템이 추가되는 non-stationary 환경
- 계산 비용: 대규모 플랫폼은 LLM이 1-2개월간 처리하는 것보다 수 배 많은 user action을 하루에 처리해야 함 (user sequence 길이 최대 )
- Generative Recommenders (GRs) 의 핵심 아이디어
- user action을 generative modeling의 새로운 modality로 취급
- 추천의 핵심 태스크(ranking, retrieval)를 sequential transduction으로 재정의
- feature space 통합 + generative training으로 동일 compute 대비 훨씬 많은 데이터 학습 가능
Method
Heterogeneous Feature → Unified Time Series
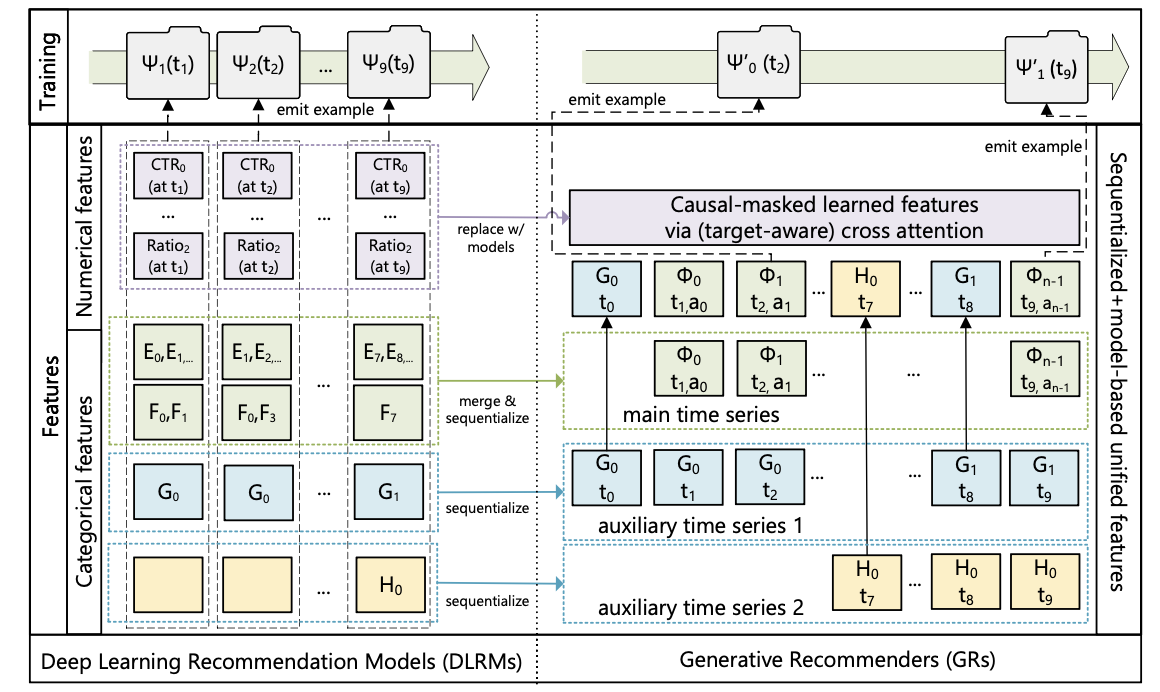
-
DLRM과 GR의 feature 통합 및 학습 과정을 나란히 비교한 도식
-
categorical feature는 merge & sequentialize, numerical feature는 model-based로 대체 → 이질적인 feature space가 단일 time series로 수렴하는 과정을 보여줌
-
Categorical(‘sparse’) features
- user가 관여한 아이템 목록을 main time series로 설정
- demographics, followed creators 등 auxiliary time series는 연속 구간별 earliest entry만 유지 후 main series에 merge
- 이 feature들은 매우 느리게 변하므로 sequence 길이가 크게 늘지 않음
-
Numerical(‘dense’) features
- CTR, ratio 등은 매 (user, item) interaction마다 변하므로 fully sequentialize 불가
- 하지만 집계 기반이 되는 categorical feature들은 이미 sequentialize됨
- → 충분히 표현력 있는 sequential transduction + target-aware formulation이 있으면 numerical feature 없이도 포착 가능 (sequence 길이가 늘어날수록)
Ranking/Retrieval as Sequential Transduction
- Retrieval: user representation 를 이용해 학습
- positive engagement인 경우에만 가 정의됨
- Ranking: target-aware formulation 필요
- item과 action을 interleave:
- → target이 sequence 안에 들어가므로 history와의 interaction이 early stage에서 발생 (late softmax가 아님)
- 모든 개 engagement에 대해 target-aware cross-attention을 one pass로 적용 가능
Generative Training
- 기존 impression-level training의 계산 복잡도: → cost prohibitive
- user 의 sampling rate를 로 설정
- 전체 비용이 으로 O(N) factor 감소
- 실제 구현: user request/session 종료 시점에 training example emit → 자연스럽게 달성
- 동일 compute로 훨씬 많은 데이터를 학습할 수 있게 됨
HSTU 아키텍처
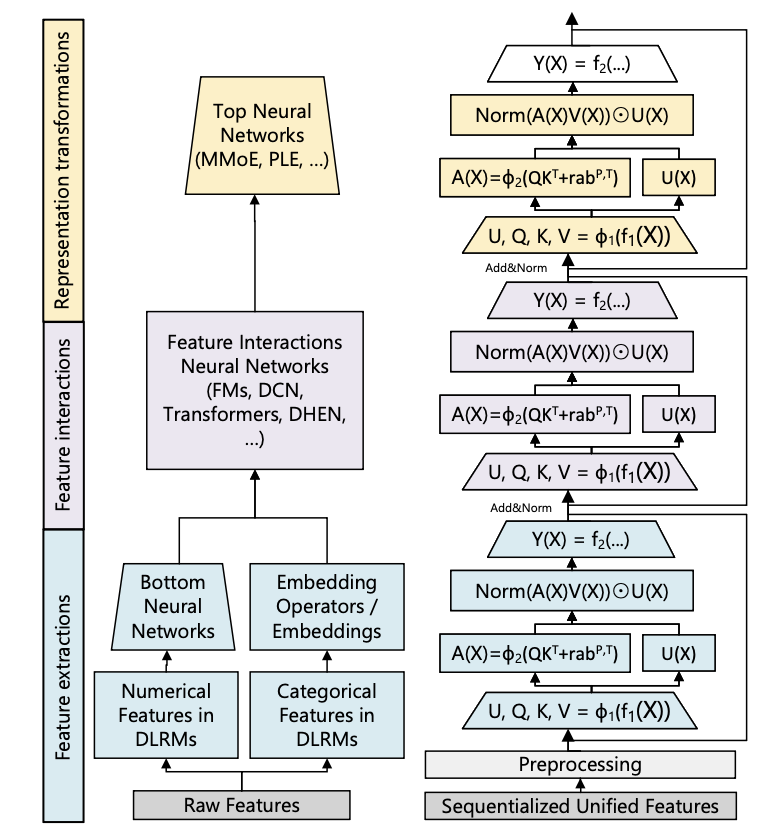
- DLRM의 복잡한 모듈 조합과 HSTU 비교
HSTU(Hierarchical Sequential Transduction Unit)는 세 개의 sub-layer로 구성된 identical block을 stack:
U(X), V(X), Q(X), K(X) = \text{Split}(\phi_1(f_1(X))) \tag{1}
A(X)V(X) = \phi_2\left(Q(X)K(X)^T + r^{abp,t}\right) V(X) \tag{2}
Y(X) = f_2\left(\text{Norm}(A(X)V(X)) \odot U(X)\right) \tag{3}
- : 단일 linear layer (compute 줄이고 Q, K, V, U를 fused kernel로 배치 처리)
- : SiLU 비선형 함수
- : positional(p) + temporal(t) 정보를 담은 relative attention bias
DLRM 3단계를 HSTU 하나로 대체:
- Feature Extraction → HSTU의 attention pooling이 target-aware pooling 포함
- Feature Interaction → : attention pooled feature 간 interaction
- dot product를 learned MLP로 근사하는 어려움을 우회
- SwiGLU의 변형으로도 해석 가능
- Transformation of Representations → element-wise dot product가 MoE의 gating operation과 유사하게 동작 (normalization 차이만 있음)
Pointwise Aggregated Attention
-
기존 softmax attention 대신 pointwise aggregated (normalized) attention 사용
-
이유 1: target 관련 prior data point 수 자체가 user preference intensity의 강한 feature → softmax normalization이 이 정보를 희석
- engagement 강도 예측(time spent)과 상대적 순위(AUC) 모두 포착해야 하므로 중요
-
이유 2: softmax는 non-stationary vocabulary streaming 환경에 덜 적합
-
pointwise attention 이후 layer norm 필수 (training 안정화)
-
Synthetic streaming data에서 Transformers, HSTU(softmax), HSTU(pointwise) 간 HR@10, HR@50 비교 시 pointwise attention이 softmax 대비 HR@10 기준 최대 44.7% 높음 → non-stationary vocabulary 환경에서 pointwise attention의 우위를 보여줌
Sparsity 활용 + Stochastic Length (SL)
- 추천 user history의 길이 분포는 skewed → sparse input
- Ragged attention computation으로 GPU kernel 최적화 (FlashAttention 방식의 fully raggified 버전)
- self-attention이 memory-bound가 되어 로 스케일 → 이것만으로 2-5x throughput 향상
- Stochastic Length (SL): user history의 temporal repetitiveness를 이용해 sequence를 확률적으로 sub-sample
- 복잡도를 로 줄임 ()
- , sequence length 4096: 80% 이상의 토큰 제거 가능하면서 NE 0.2% 이하 하락
Activation Memory 최소화
- HSTU: attention 외부의 linear layer를 6개 → 2개로 축소, 계산을 단일 operator로 aggressive fusion
- activation memory: 14d per layer (bfloat16)
- vs Transformer: 33d per layer (standard assumption 기준)
- → 2x 이상 깊은 네트워크 구성 가능
- 10B vocabulary, 512d embedding, Adam optimizer 기준: embedding + optimizer states만 60TB
- rowwise AdamW + optimizer states on DRAM으로 HBM 사용량을 float당 12 bytes → 2 bytes로 절감
M-FALCON: Inference Cost Amortization
- Ranking 추론 시 수만 개의 candidates를 처리해야 하는 문제
- M-FALCON (Microbatched-Fast Attention Leveraging Cacheable OperatioNs)
- 개 candidate를 병렬로 처리하도록 attention mask와 bias를 수정
- cross-attention 비용: (인 경우)
- 개 전체를 개 microbatch로 분할 → encoder-level KV caching 활용 가능
- cached forward pass 복잡도: → microbatch + caching 결합 시 추가 1.99x 절감
- 결과: 285x 복잡한 모델을 동일한 inference budget으로 1.50x~2.99x 높은 throughput으로 서빙
Experiments
Public Dataset (전통적 sequential 설정)
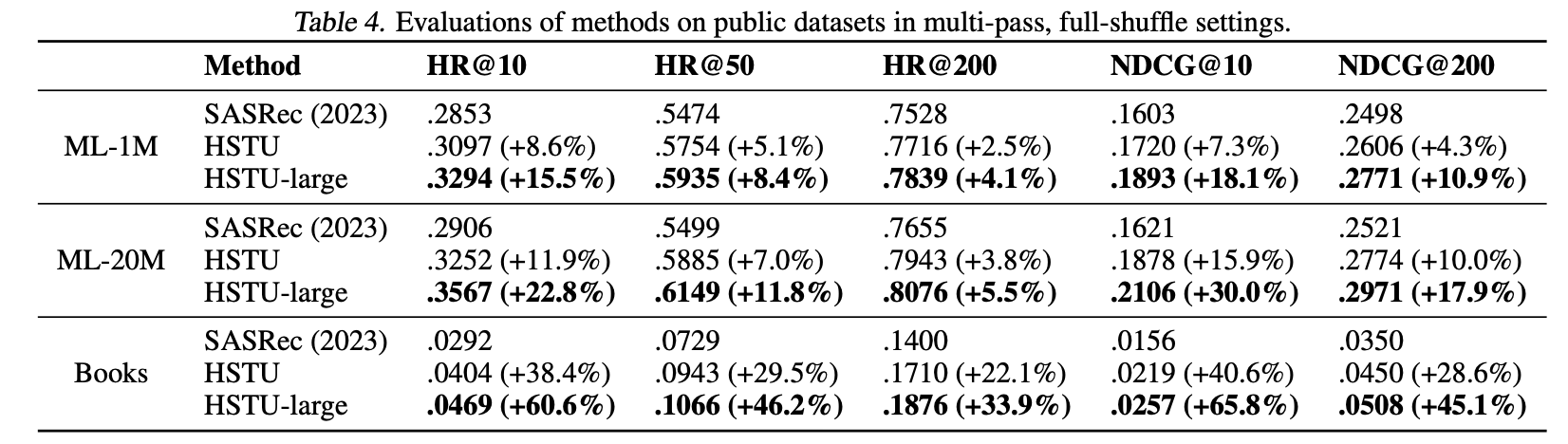
- ML-1M, ML-20M, Amazon Books에서 SASRec(2023), HSTU, HSTU-large의 HR@K, NDCG@K 비교 (multi-pass full-shuffle)
- HSTU가 동일 구성에서 SASRec 대비 일관되게 우월하며, HSTU-large는 Books 기준 NDCG@10 +65.8% → 모델 크기를 키울수록 성능이 함께 향상됨을 보여줌
Industrial-Scale Streaming 설정
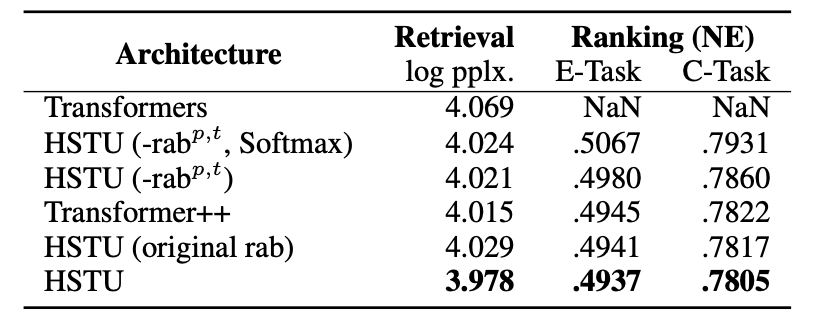
- HSTU, ablated HSTU 변형들, Transformers, Transformer++의 retrieval log perplexity와 ranking NE 비교 (100B examples, streaming)
- 표준 Transformer는 ranking에서 NaN 발생. HSTU가 모든 변형 대비 최저 NE 달성 → pointwise attention과 temporal bias 각각의 기여가 ablation으로 확인됨
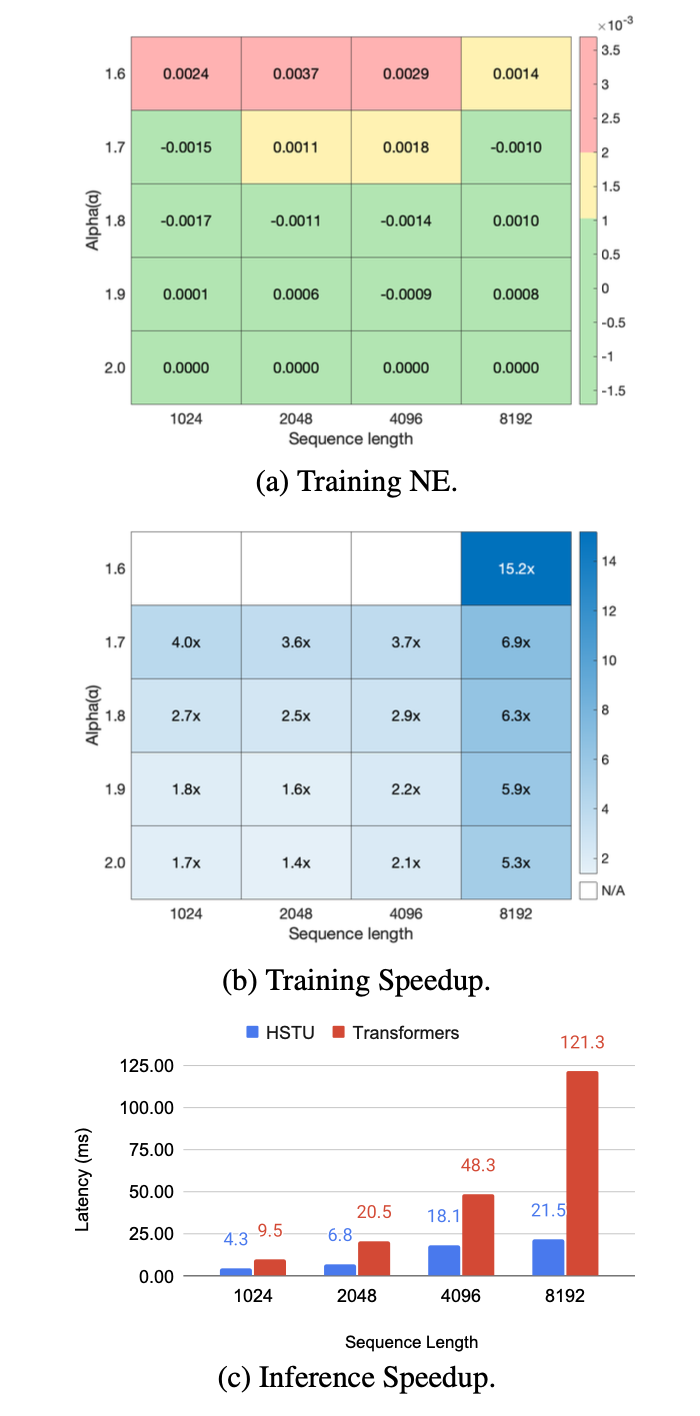
- sequence length 1024~8192 구간에서 HSTU와 FlashAttention2 Transformer의 training/inference latency 비교 시, raining 최대 15.2x, inference 최대 5.6x 빠름 → SL과 ragged attention의 효율 이득이 sequence가 길어질수록 더 커짐
실제 서비스에서 GR vs DLRM
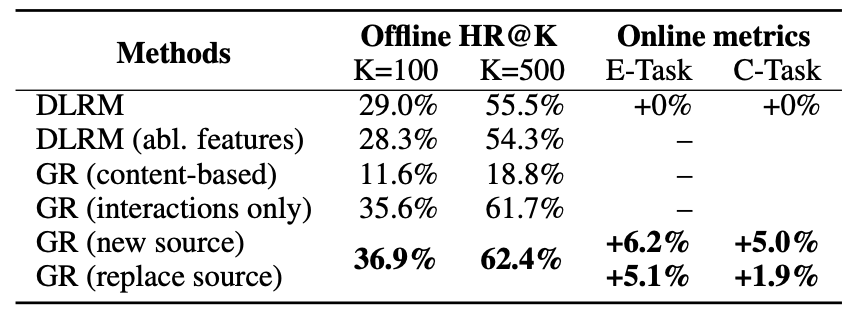
- Retrieval 단계에서 DLRM, GR 변형들의 offline HR@K와 online E/C-Task 지표 비교
- GR(new source)가 E-Task +6.2%, C-Task +5.0% 개선. GR(content-based)는 DLRM보다 크게 낮음 → user action(collaborative signal)이 content feature보다 훨씬 결정적임을 보여줌
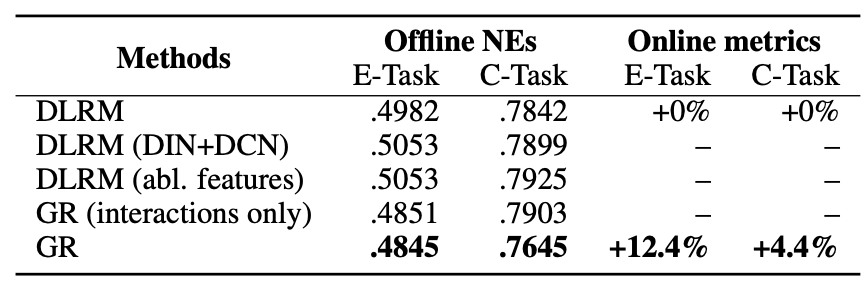
- Ranking 단계에서 DLRM 변형들과 GR의 offline NE 및 online 지표 비교
- GR이 E-Task +12.4%, C-Task +4.4% 달성. GR에 쓰인 feature만 남긴 DLRM은 성능이 크게 하락 → GR이 동일 feature를 sequential 구조로 더 잘 활용함을 보여줌
Scaling Law
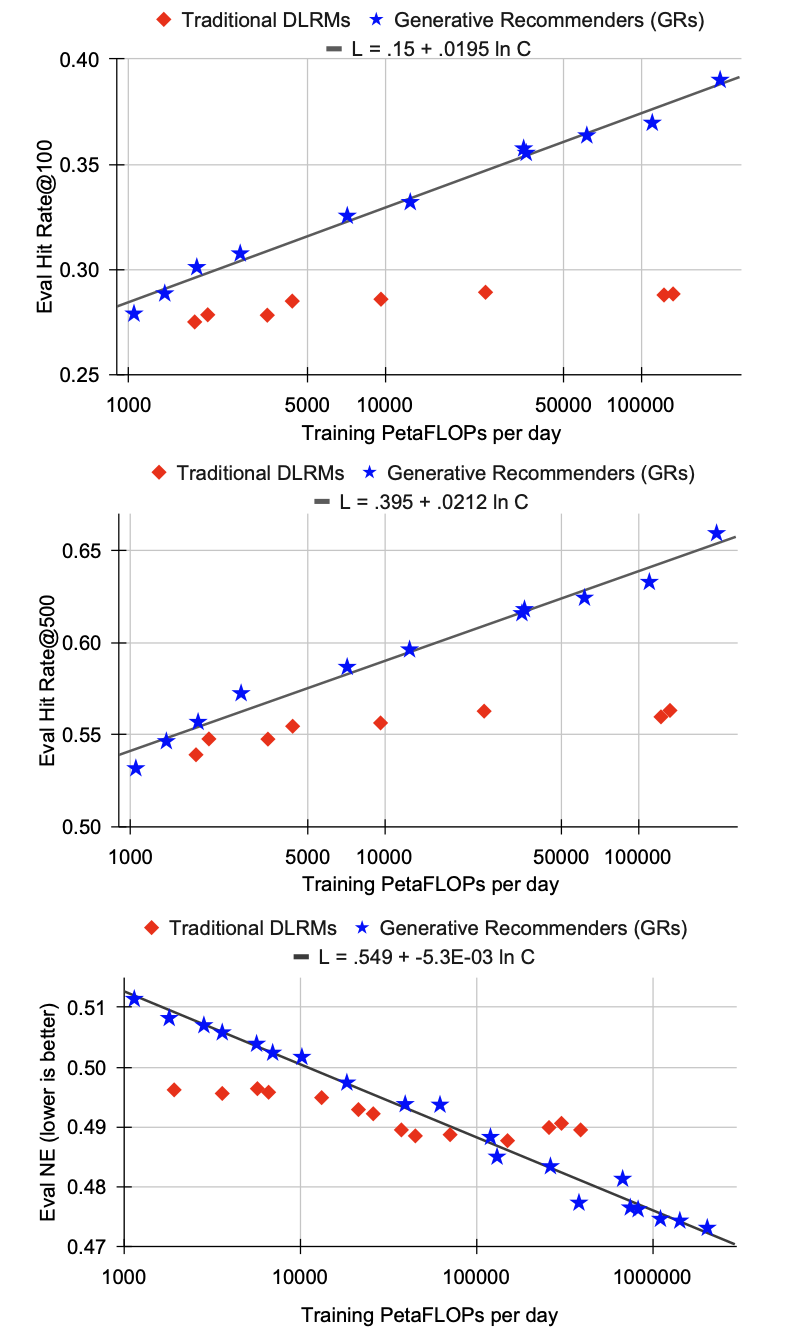
-
training compute(PetaFLOPs/day)에 따른 retrieval HR@100, HR@500, ranking NE 변화를 DLRM과 GR 각각 플롯
-
GR은 3 orders of magnitude에 걸쳐 power-law scaling을 따르는 반면 DLRM은 일정 compute 이후 포화 → GR만이 LLM 수준의 scaling law를 따름을 보여줌
-
power-law fit: Retrieval HR@100: , Retrieval HR@500: , Ranking NE:
-
낮은 compute 구간에서는 DLRM이 앞서기도 함 (handcrafted feature 덕분)
-
LLM과 달리 sequence length가 scaling에서 특히 중요 → embedding dim, layer 수와 함께 같이 늘려야 함
-
DLRM은 약 200B parameter에서 포화되나, GR은 1.5T parameter 모델까지 지속 향상
💭
- Generative training에서 sampling rate를 로 설정해 O(N) factor를 줄이는 아이디어 - user session 종료 시점에 example을 emit하면 이 sampling이 자연스럽게 달성된다는 구현 insight
- Stochastic Length가 80% 이상 토큰을 제거하면서도 NE가 0.2% 이하 하락한다는 결과가 놀라움. user history의 temporal repetitiveness 덕분이라고 설명하는데, cold-start 유저나 행동 패턴이 다양한 도메인에서도 같은 효과가 나올지는 확인이 필요함
- 동일한 feature set을 DLRM에 줬을 때의 fair comparison이 더 명확한 ablation이었을 것