LLM-I2I: Boost Your Small Item2Item Recommendation Model with Large Language Model (2025)
배경
- I2I(Item-to-Item) 추천은 대규모 실서비스에서 여전히 핵심적인 역할을 담당
- 경량 모델, 실시간 응답, 낮은 inference 비용이라는 실용적 장점
- 오프라인 학습 후 inverted index 구성 → 온라인 실시간 조회 구조
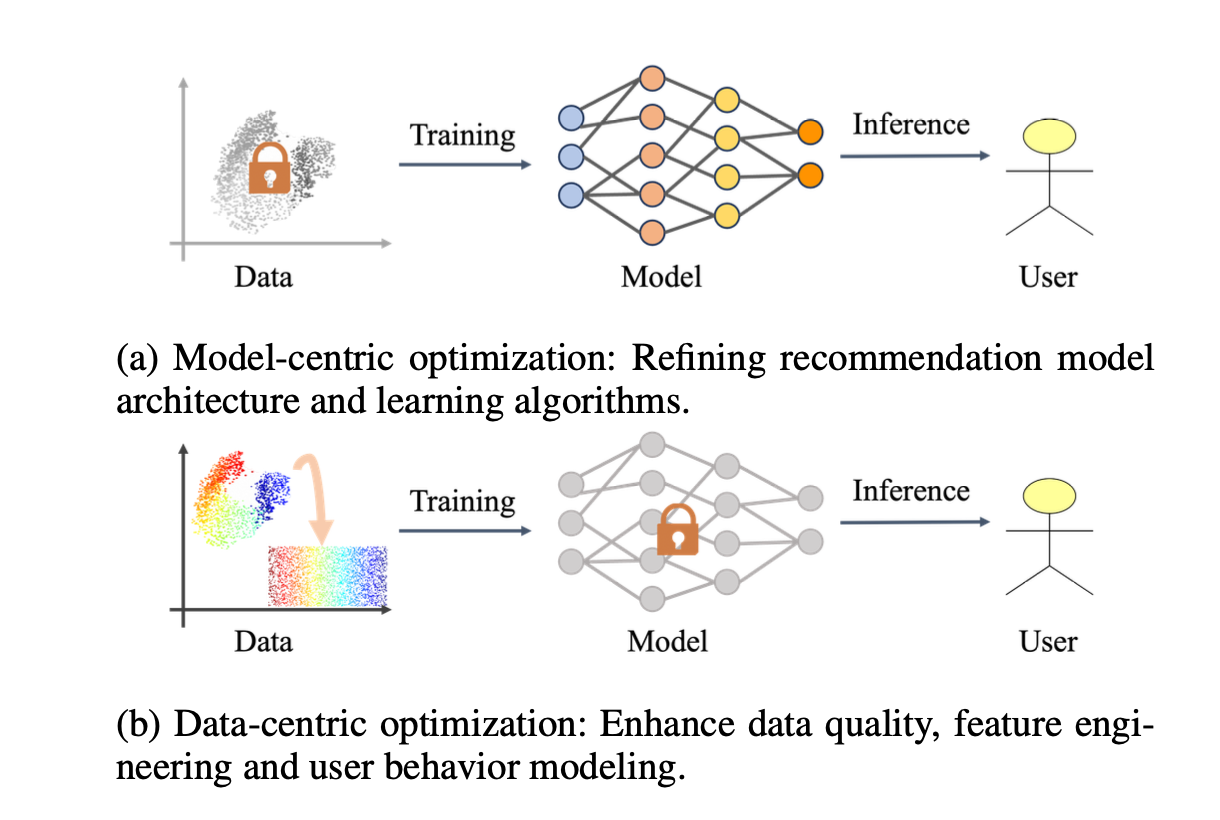
- 개선 방향은 크게 두 가지로 분류됨
- Model-centric: 모델 구조 자체를 깊게 만드는 방식 → 온라인 latency 증가 위험
- Data-centric: 모델을 건드리지 않고 학습 데이터 품질/다양성을 개선 → 배포 비용 절감
- I2I 학습 데이터의 두 가지 핵심 문제
- Sparsity Problem: e-commerce에서 long-tail item은 user-item 상호작용 기록이 희소해 I2I 알고리즘이 유사도 계산 자체를 못함
- Noise Problem: 실수 클릭, 우발적 구매 등 노이즈 데이터가 모델 품질을 저하시킴
- 기존 LLM 기반 데이터 증강은 generation 또는 selection 중 하나에만 집중하여 두 문제를 동시에 해결하지 못함
- → LLM-I2I는 Generator + Discriminator를 통합하여 두 문제를 함께 해결
방법론: LLM-I2I
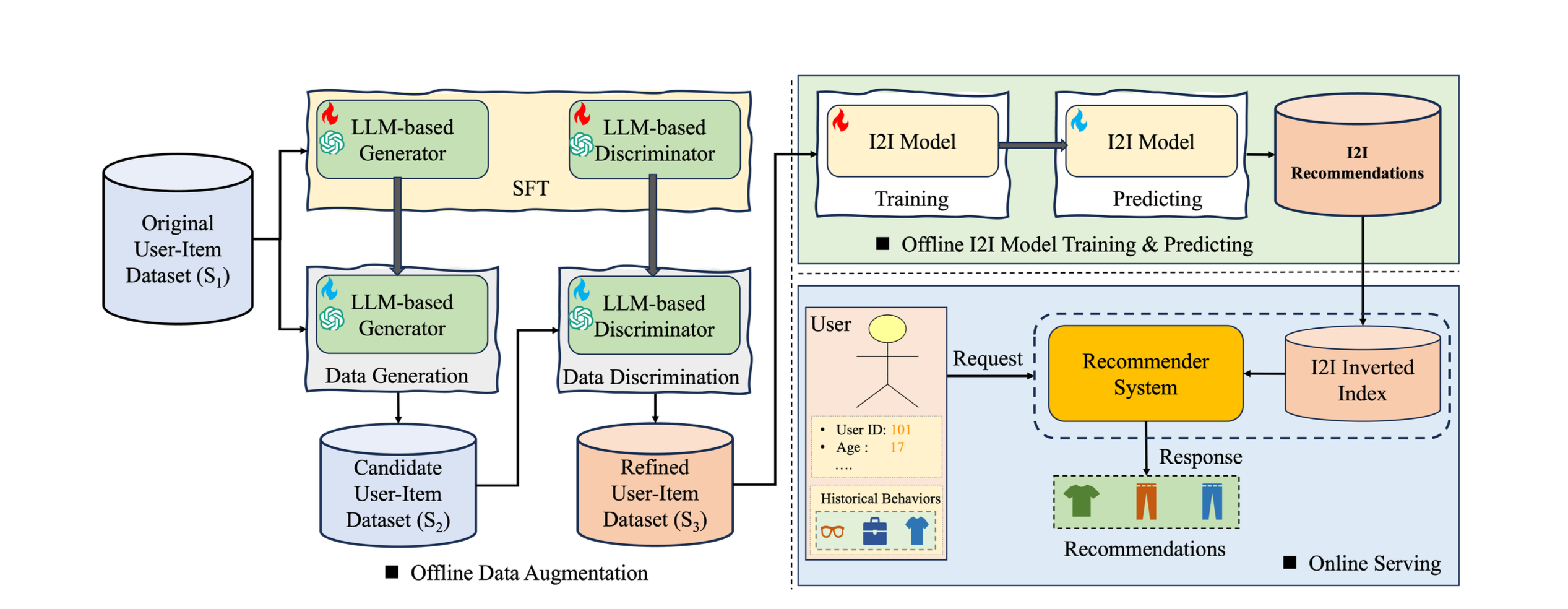
- 전체 파이프라인: LLM-based Generator → 합성 데이터 생성 → LLM-based Discriminator → 품질 필터링 → 원본 데이터와 융합 → I2I 모델 학습
LLM-based Data Generator
- 목적: user 히스토리를 기반으로 새로운 user-item 상호작용 데이터를 합성, 특히 long-tail item에 집중
- 학습 방식: SFT (Supervised Fine-Tuning)
- 입력: User feature (User ID, 구매 이력 등) + Prompt instruction
- 출력: 해당 user가 구매할 것 같은 Target Item ID
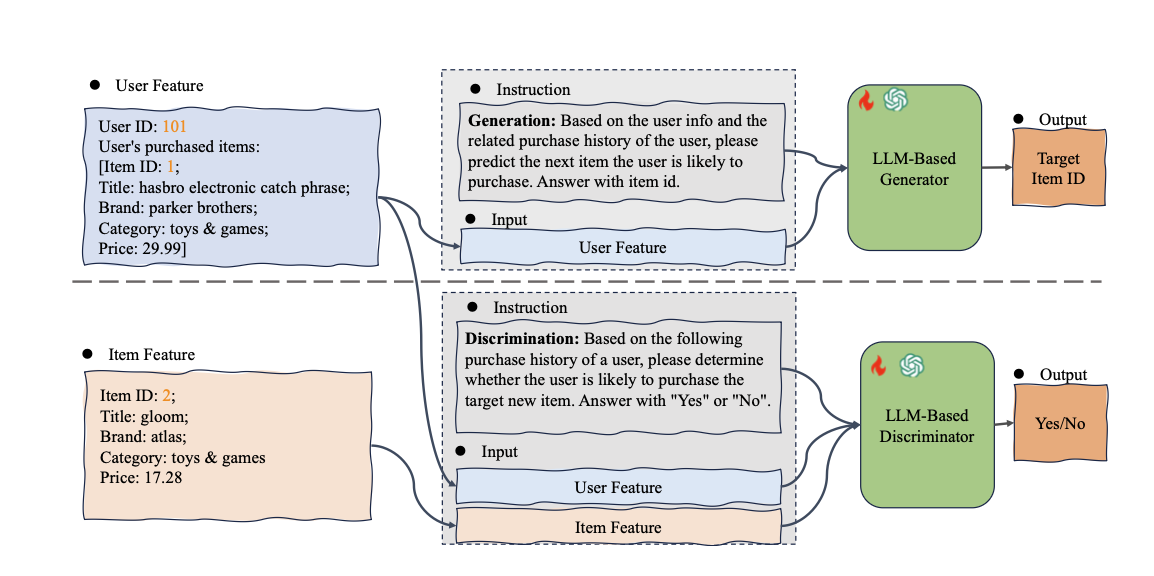
-
Generator와 Discriminator의 SFT 입출력 예시
-
SFT 목적 함수:
- : 정적 사용자 정보 (ID, 카테고리 등), : 동적 히스토리 행동 기록
- Long-tail loss: long-tail item 생성을 장려하는 가중치 적용
- , 으로 설정 → long-tail item 생성을 4배 가중
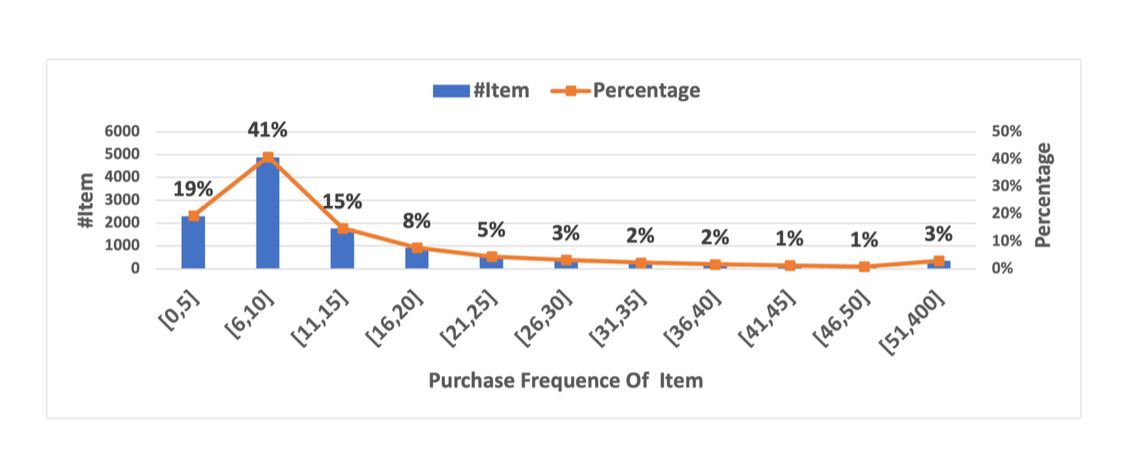
- ARD Toys and Games 데이터셋의 long-tail 분포: 약 20% 아이템이 5회 이하 구매 → 심각한 희소성
- 각 user의 최근 10개 상호작용을 생성 시 input으로 사용 (LLM input 길이 제약 대응)
LLM-based Data Discriminator
- 목적: Generator가 만든 합성 데이터 중 노이즈를 필터링, 고품질 데이터만 선별
- 직접 사용했을 때의 두 가지 문제:
- 합성 데이터 품질 불확실 → 노이즈 포함 시 학습 성능 저하
- 합성 데이터 분포가 실제 데이터와 달라 distribution drift 발생
- SFT 목적 함수: user의 positive/negative item에 대해 “Yes/No” 판별
- : 실제 상호작용 아이템 (positive), : 랜덤 샘플링한 negative 아이템
Data Augmentation 파이프라인
- Fine-tuned Generator로 각 user별 합성 user-item 상호작용 생성
- Discriminator가 “Yes” 판별 + confidence score = 1.0인 데이터만 선별
- 선별된 합성 데이터 + 원본 실제 데이터 → 최종 학습셋 구성
- 기존 I2I 모델 (BM25, BPR, YoutubeDNN, Swing 등)에 적용
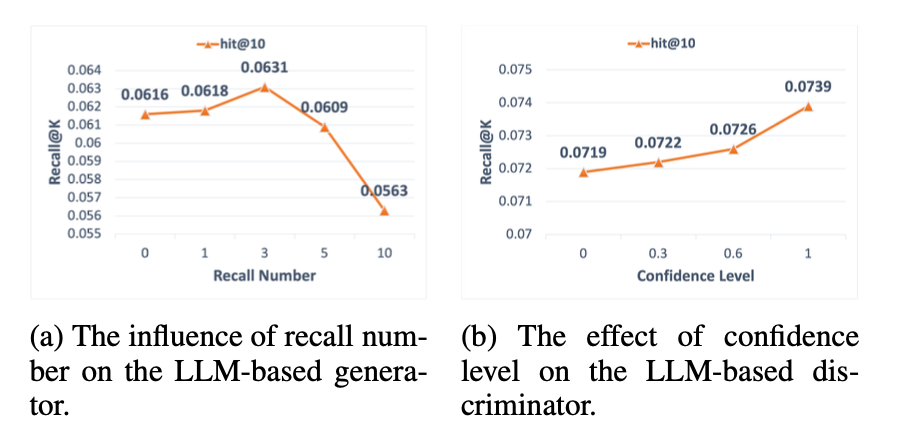
- (a)합성 데이터 양이 늘어날수록 성능이 처음엔 오르다가 다시 떨어짐 → 적절한 양+품질 균형이 중요
-
- 단순히 데이터를 많이 늘리는 것만으론 안 되고, Discriminator로 품질 관리가 필수
-
- (b) Discriminator의 confidence level이 높을수록 Recall@10 성능 향상 → 고신뢰 데이터 선별이 핵심
온라인 서빙 구조
- 오프라인에서 refined 학습 데이터로 I2I 모델 재학습 → I2I inverted index 업데이트
- 온라인 서빙 시:
- 사용자 최근 상호작용 top-M item ID 조회
- inverted index에서 M × K 추천 결과 집계
- ranking 파이프라인으로 최종 후보 전달
- 온라인 latency 증가 없음: LLM 추론은 오프라인에서만 발생
실험
데이터셋
- ARD(Amazon Review Dataset): 학술 벤치마크 - Beauty, Sports, Toy
- AEDS (AliExpress Dataset): 대규모 산업 데이터셋, 전체 아이템의 약 25%가 클릭 1회 이하인 long-tail item
Results
- ARD에서 Backbone 성능 비교
- 비교 대상: BM25, BPR, YoutubeDNN, Swing × {No augmentation, LLM-CF, LLM-I2I}
- LLM-I2I가 모든 backbone에서 LLM-CF 대비 일관되게 우월
- LLM-CF는 user-based 증강, LLM-I2I는 item-based 증강 → item-based CF의 일반적 우위와 일치
- Swing + LLM-I2I 주요 성과:
- Beauty: Recall@10 +13.04%
- Sports: Recall@10 +15.15%
- Toys: Recall@10 +19.97%
- AEDS에서
- Swing + LLM-I2I:
- Recall@5 +18.57%, Recall@10 +18.22%
- NDCG@5 +16.34%, NDCG@10 +16.31%
- BPR + LLM-I2I: Recall@10 +93.88% (약한 baseline에서 극적 개선)
- Swing + LLM-I2I:
- Long-tail Item 성능
- AEDS에서 Recall@10 +60.75%, NDCG@10 +85.71%
- 소규모 ARD보다 대규모 AEDS에서 long-tail 개선 효과가 훨씬 큼 (데이터셋 규모가 클수록 long-tail 문제가 심각하고, LLM-I2I의 효과도 더 두드러짐)
- Ablation 결과
- Generator, long-tail loss, Discriminator 각 컴포넌트 모두 성능에 기여
w/o Swing(LLM만 사용): Recall@5가 높지만 Recall@10이 낮음 → LLM 단독으론 diversity 부족, collaborative filtering과의 결합이 중요
- Online A/B Test (AliExpress)
- RN(Recall Number) +6.02%, GMV +1.22% 유의미한 개선
- Latency는 거의 증가 없음 (오프라인 index 업데이트 방식이므로)