Beyond Labels: Leveraging Deep Learning and LLMs for Content Metadata (2023)
✳ Tubi는 Fox 소유의 OTT서비스임
- OTT 콘텐츠의 장르 메타데이터
- challenges
- 보편적으로 인정되는 정의 부족, 다양한 소스의 장르 분류에 대한 합의가 부족함 → 라벨을 만들어도 노이즈가 많고 일관성이 떨어짐 (라벨러의 주관적 판단)
- 로맨틱 코미디처럼 특정 장르는 여러 장르의 조합에 가깝고 종종 여러 다른 장르에 속하는 영화들이 많음 → 단순 라벨로는 이런 혼합 케이스나 각 장르의 강도를 잘 표현하지 못함
- challenges
- 방법론
- 약 110만 편 영화의 텍스트 메타데이터(장르, 언어, 출시 연도, 줄거리 요약, 평점, 사용자 리뷰, 박스오프스 정보 등)를 수집 from IMDb, 로튼토마토, 그레이스노트
- 언어 모델링을 적용하여 영화의 텍스트 임베딩을 학습
- Doc2Vec, BERT, GPT-4 등
- 학습된 텍스트 임베딩을 input feature로 사용해 장르 레이블을 예측하는(각 장르 클래스의 확률을 출력으로 하는) 신경망을 학습
- data augmentation (메타데이터 품질이 낮은 비인기 영화의 임베딩 품질을 개선하기 위해 2개의 학습 샘플을 랜덤하게 선택해서 feature, label에 대한 random convex combination을 통해 synthetic data 생성)
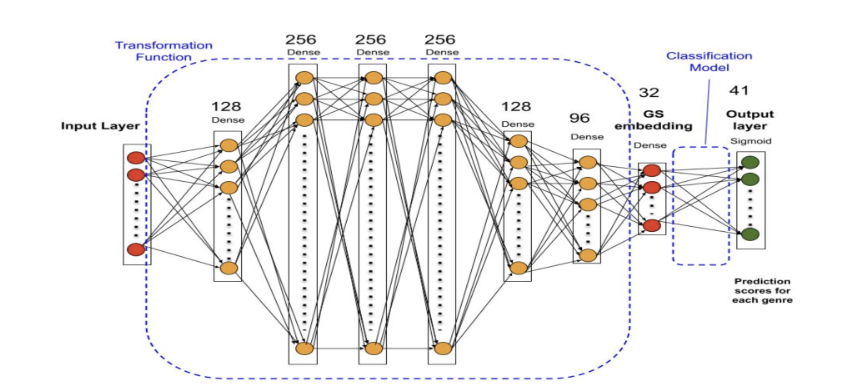
- 텍스트 임베딩 → 장르 스펙트럼 임베딩을 변환하는 컴포넌트와 장르를 분류하는 컴포넌트를 동시에 학습
- 마지막에서 두번째 레이어에서 출력되는 벡터가 장르 스펙트럼 임베딩임
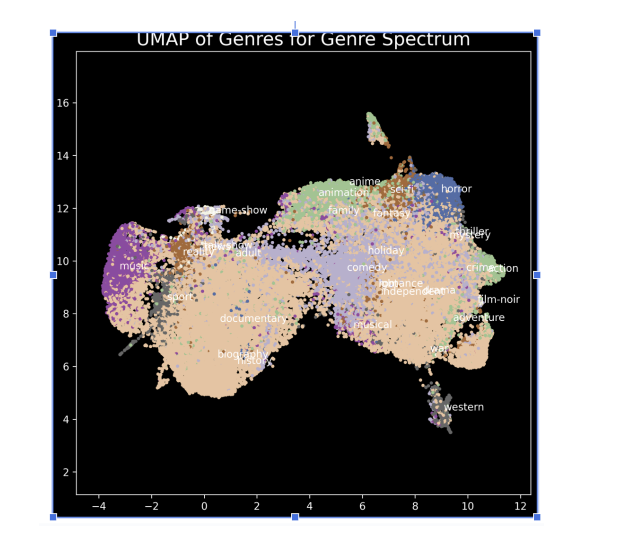
- 정성평가
- umap - 각 장르가 응집력 있게 표현
- 정량평가
- 각 영화의 top k NN에 대해 장르 유사도(해당 영화와 하나 이상의 주요 장르를 공유하는 NN의 비율)를 계산
- 텍스트 임베딩을 그냥 사용하는 것과 비교했을 때 장르 스펙트럼 임베딩이 모든 경우에 더 우수했고 특히 인기가 없는(메타가 부족한) 영화에서 개선폭이 컸음 (즉 장르 스펙트럼 임베딩이 텍스트 임베딩의 노이즈나 모호함을 줄이고 더 효과적으로 장르 유사도를 나타내고 있음을 알 수 있음)
- 각 영화의 top k NN에 대해 장르 유사도(해당 영화와 하나 이상의 주요 장르를 공유하는 NN의 비율)를 계산
- 온라인
- NN 리트리벌 모델로 프로덕션 도입했을 때 A/B 테스트 결과 view time 지표에서 0.6%의 개선