TalkPlay-Tools: Conversational Music Recommendation with LLM Tool Calling (2025)
배경
- 음악 추천은 오랫동안 boolean filtering (메타데이터) → 대규모 user/item 임베딩 기반 retrieval-reranking → 멀티모달 표현 학습 순으로 발전
- 최근 LLM 기반 추천 시스템은 Semantic ID를 통해 generative recommendation을 가능하게 하고 대화형 인터랙션을 지원
- 문제: 단일 retrieval 방식에는 한계가 있음 → 실제 프로덕션 추천 시스템은 multi-stage, routed retrieval-reranking 파이프라인을 사용하며 다양한 운영 조건(장르, 무드, 신곡 여부 등)을 동시에 만족해야 함
- LLM이 여러 종류의 retrieval 방식을 통합적으로 활용하게 하면 더 다양한 context를 반영할 수 있다는 아이디어
시스템 구조
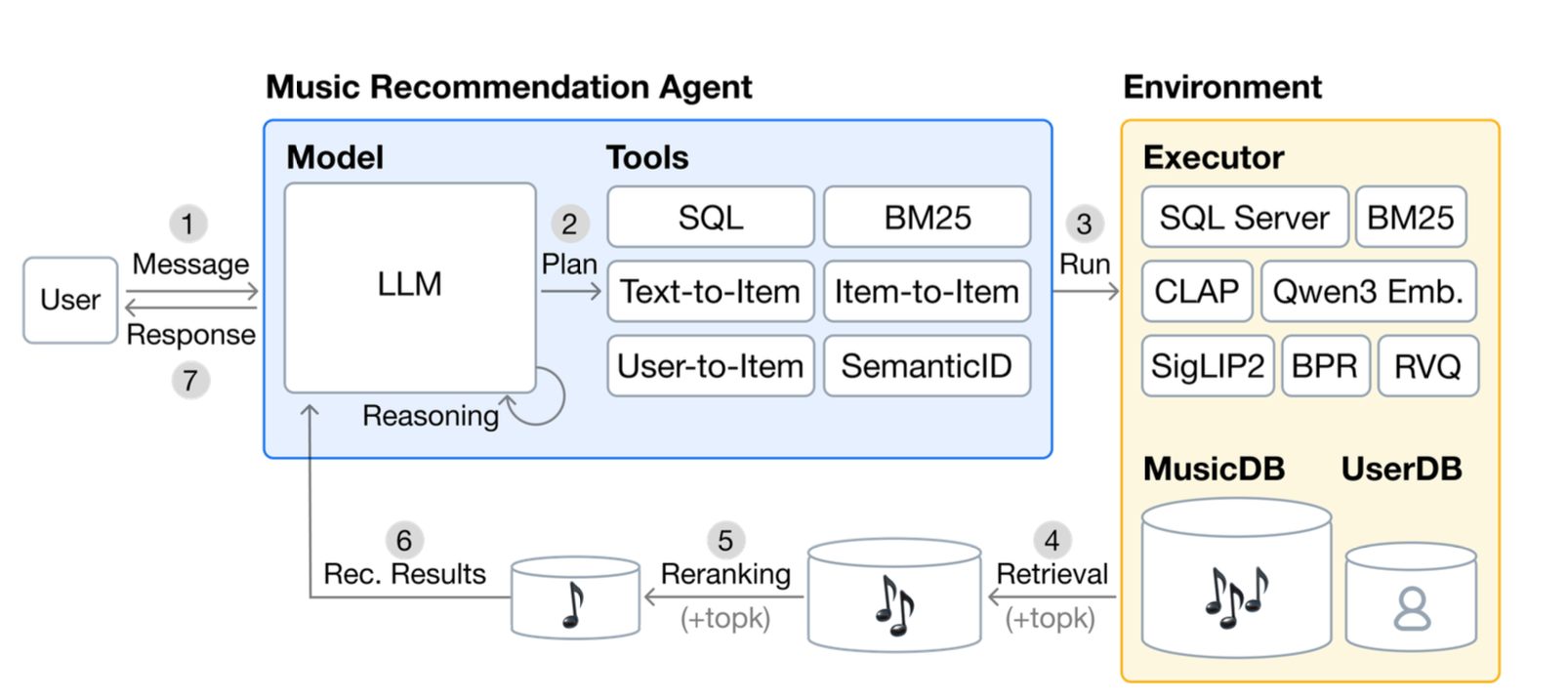
- 두 가지 주요 컴포넌트로 구성
- Music Recommendation Agent: LLM + Tools
- External Environment: 실제 tool을 실행하는 executor + DB (MusicDB, UserDB)
- 추론 흐름: User 메시지 → LLM이 tool call 계획 → executor가 도구 실행 (retrieval) → 결과를 바탕으로 reranking → LLM이 자연어 응답 생성
문제 정의
사용자 , 프로필 , 이전 대화 상태 , 현재 쿼리 가 주어졌을 때:
- : LLM이 예측한 tool call 시퀀스
- tool execution은 순차적 파이프라인 → 각 tool의 출력이 다음 tool의 입력 공간을 제한
- 따라서 tool 순서가 최종 추천 품질에 큰 영향을 미침
Tools 구성
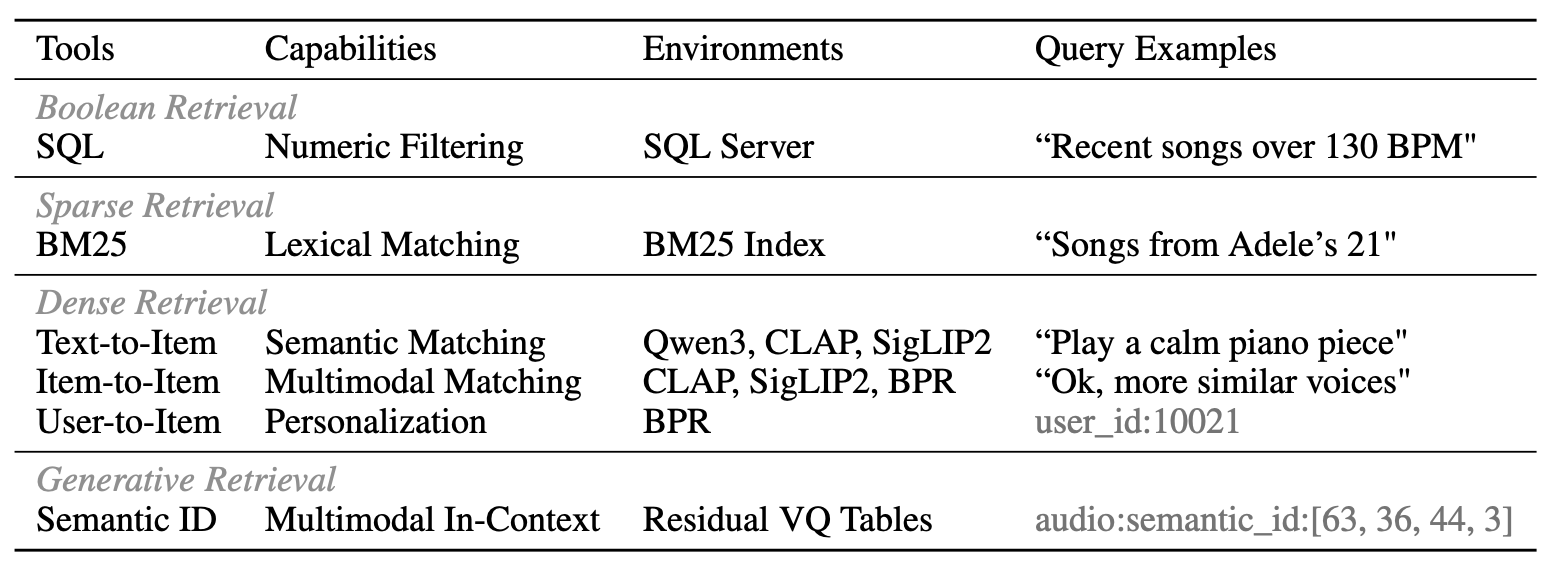
Boolean Retrieval
- SQL: 관계형 메타데이터에 대한 정확한 구조화된 쿼리
- schema:
track_id,title,artist,album,popularity,release_date,tempo,key - 예:
sql(query="SELECT * FROM tracks WHERE date>=2020 ORDER BY tempo", topk=100)
- schema:
Sparse Retrieval
- BM25: 토큰 기반 lexical matching
- 5가지 corpus:
title,artist,album,lyrics,attributes - 오타가 많거나 exact string matching이 어려운 쿼리에 효과적
- 예:
bm25(query="taylor swift songs", corpus="artist", topk=100)
- 5가지 corpus:
Dense Retrieval
- Text-to-Item: 자연어 텍스트 → 음악 아이템 semantic 유사도 검색
- pretrained text encoder (Qwen3) 및 멀티모달 encoder (CLAP, SigLIP2) 사용
modality_type: text / audio / imagevector_db_type: metadata / lyrics / attributes / audio / image- 예: 앨범 커버 이미지 묘사로 음악을 찾는 것도 가능
- Item-to-Item: 기존 추천 트랙 또는 사용자가 제공한 예시 기반 유사 아이템 탐색
- LLM이 이전 대화에서 track_id를 생성하면 해당 임베딩을 vector DB에서 조회해 유사도 기반 검색
modality_type: audio / image / cf
- User-to-Item: BPR(Bayesian Personalized Ranking)로 학습된 user 임베딩을 사용한 개인화 추천
- 사용자 쿼리가 아닌 user profile의 user_id로 활성화됨 → cold start 유저에겐 사용 불가
- 예:
user_to_item(user_id=10021, topk=200)
Generative Retrieval
- Semantic ID: 아이템의 content feature를 Residual VQ(RVQ)로 양자화한 discrete 표현
- RVQ 구조: 4개의 residual quantization layer, layer당 64개의 codebook
- 6가지 modality에 대해 별도 RVQ 학습: listening history, metadata, semantic tags, lyrics, album art, audio
- 이후 결합하여 multimodal semantic identifier 생성
- inverted index를 구축해 exact code match 또는 small edit distance로 빠른 조회
- LLM이 in-context 정보로 음악의 멀티모달 속성을 이해하게 돕는 용도
- 예:
semantic_id(item_modality="audio", indices=[52, 42, 5, 9], topk=20)
In-Context 정보 구성
추론 시 LLM에 제공되는 4가지 conditioning 정보:
- System Prompt: tool calling용과 response generation용 두 가지 별도 프롬프트
- Tool calling 프롬프트는 3단계 구조: Planning → Retrieval → Reranking
- Stage 1 (Planning): 어떤 retrieval/reranking tool을 쓸지 rationale과 함께 선택
- Stage 2 (Retrieval): 선택된 retrieval tool로 최소 topk개의 track_id 수집
- Stage 3 (Reranking): 선택된 reranking tool로 candidates 재정렬
- 엄격한 제약: retrieval → reranking 순서 고정, 도구 간 기능 중복 없음
- Tool calling 프롬프트는 3단계 구조: Planning → Retrieval → Reranking
- Tool Functions: JSON schema 형태의 tool 목록 (이름, 설명, 파라미터 타입)
- User Profiles: 인구통계(User ID, 나이대, 성별) + 최근 청취 5곡의 메타데이터/attributes/Semantic IDs
- Previous Conversation History: 이전 쿼리 + 추천 음악(메타데이터+Semantic IDs 포함) + LLM 응답
실험
데이터셋
- TalkPlayData 2: 멀티모달 대화형 음악 추천을 위한 synthetic 데이터셋
- LFM-2b에서 가져온 user profile (성별, 나이, 국가)
- 1000개의 테스트 대화, 각 대화는 8턴으로 구성
환경
- SQL/BM25: LFM-2b의 기본 메타데이터 + last.fm 장르/스타일 어노테이션
- Dense retrieval vector DB:
- Text: Qwen3-0.6 embedding
- Audio: CLAP
- Image: SigLIP2
- User/Item: BPR
- Base LLM: Qwen3-LM-4B, temperature=0.6, top_p=0.95
- 모든 identifier(User ID, Track ID, Semantic ID)를 special token 확장 없이 자연어 문자열로 표현
결과

- Tool Calling 방식이 zero-shot 설정에서도 모든 baselines보다 우수
- Hit@1에서 Qwen3-LM+BM25 대비 +0.004 향상 → multiple tool integration을 통한 reranking 효과
Tool 사용 빈도 및 성공률 분석
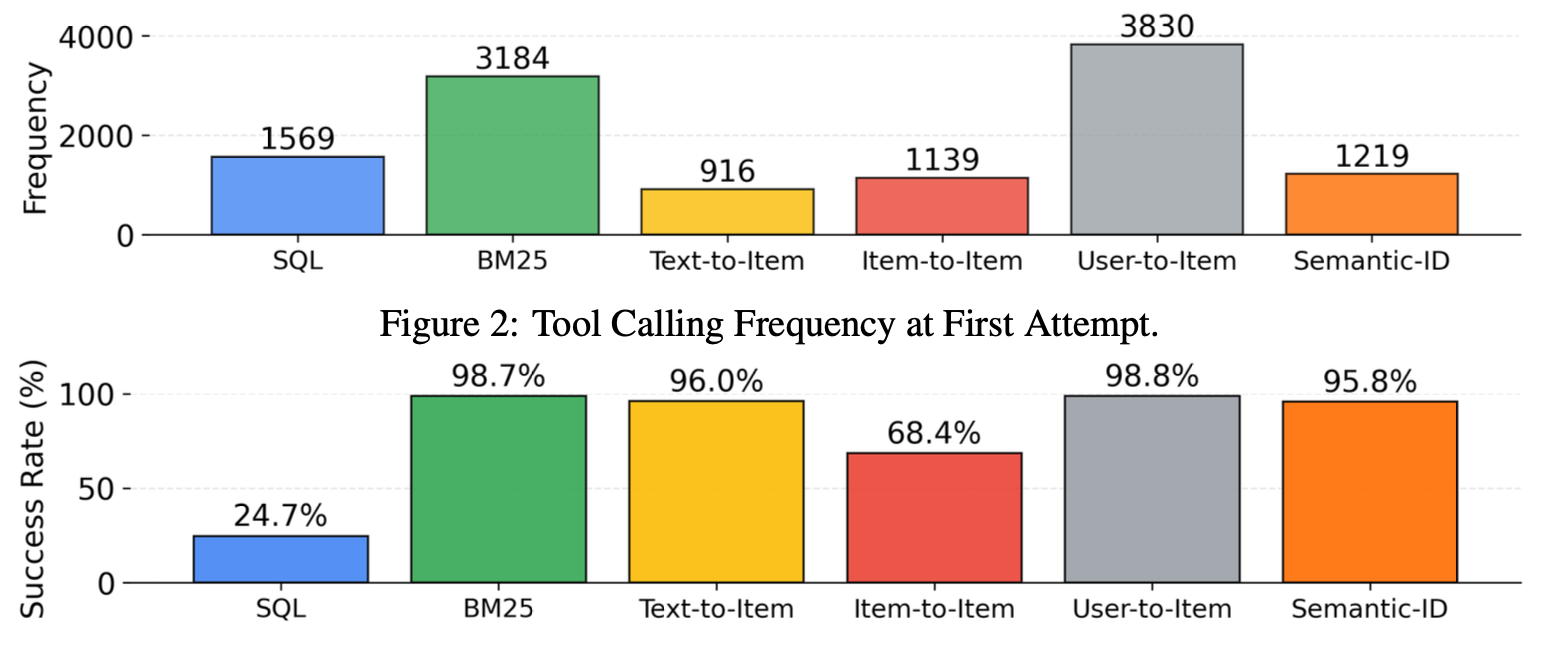
-
사용 빈도: BM25(3184) > User-to-Item(3830) > Semantic ID(1219) > Text-to-Item(916) > Item-to-Item(1139) > SQL(1569)
- SQL, BM25 같은 자연어 친화적 도구가 높은 사용 빈도 → pretrain 데이터에서 더 자주 등장하기 때문
- item-to-item, Semantic ID 같은 도메인 특화 tool은 낮은 빈도
-
성공률:
- SQL: 24.7% (매우 낮음) → SQL 문법 오류, 유효하지 않은 column명, 동의어/오타로 인한 메타데이터 불일치
- BM25: 96.0%
- Text-to-Item: 96.0%
- Item-to-Item: 68.4% → 22자리 track_id(private 정보) 예측의 어려움
- User-to-Item: 98.8% (예상외로 높음) → user profile에서 user_id가 in-context로 직접 제공되기 때문
- Semantic ID: 95.8% (예상외로 높음) → 이전 대화 context에 Semantic ID가 포함되어 있어 LLM이 패턴 학습 가능
-
- 흥미로운 점: LLM pretraining에서 전혀 본 적 없는 User ID, Semantic ID 같은 정보 유형임에도 in-context 정보 덕분에 높은 성공률 달성
향후 연구 방향
- Reinforcement Learning으로 tool calling 정밀도 향상 및 retry 의존도 감소
- track-centric을 넘어선 개인화된 tool calling 전략 설계 (더 세밀한 user preference/behavioral pattern 포착)
