Playlist Search Reinvented: LLMs Behind the Curtain (2024)
배경
- Amazon Music의 검색 시스템은 기존 lexical search(bag-of-words)에서 transformer 기반 bi-encoder semantic search으로 전환 중
- semantic search의 최종 목표: 유저가 “잔잔한 새벽 감성 음악”처럼 자연어로 검색해도 관련 playlist를 잘 찾아주는 retrieval 모델
- 플레이리스트는 두 종류로 구분됨
- EPL (Editorial Playlist): 전문가 큐레이션, 풍부한 메타데이터 보유
- CPL (Community Playlist): 유저 생성, 메타데이터 거의 없음
- CPL의 메타데이터 부재로 semantic search 모델 개발에 세 가지 병목 발생:
- 데이터 부족: 검색 로그 기반 query-clicked playlist 쌍이 lexical matching에 편향됨 → semantic search에 부적합
- 메타데이터 부재: CPL은 임베딩할 description이 없음
- 평가 비용: 카탈로그 전체를 뒤져야 하는 human annotation이 매우 비쌈
접근 방법
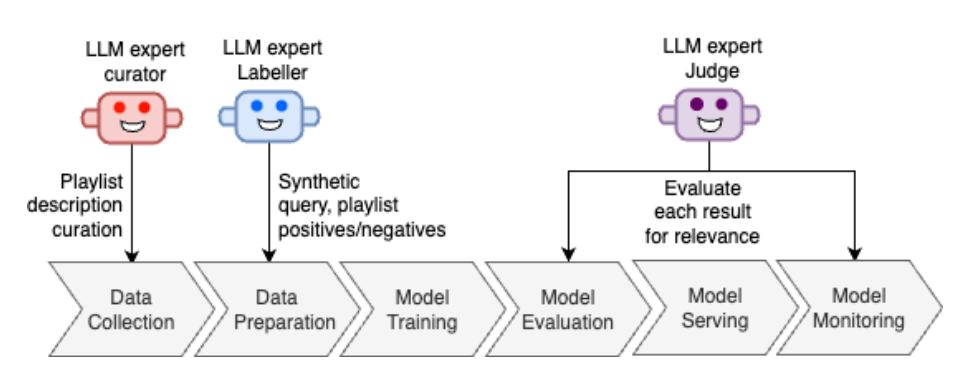
- LLM을 ML 파이프라인의 세 단계에 통합: 메타데이터 enrichment → 학습 데이터 생성 → 평가
1. 메타데이터 Enrichment (CPL)
- CPL의 처음 15개 트랙을 LLM에 제공하여 상세 description 자동 생성
- 캡처 대상: themes, genres, activities, eras, artists
- 사용 모델:
- Off-the-shelf 100B+ 파라미터 모델
- Fine-tuned Flan-T5-XL (3B) — CPL/EPL 트랙+description 데이터로 fine-tuning
- 작은 fine-tuned 모델이 예상보다 뛰어난 성능을 보임
- → 즉, 대형 모델 없이도 도메인 특화 fine-tuning으로 충분한 description 품질 달성 가능
2. 학습 데이터 생성
- 학습 데이터 소스 3가지를 혼합:
- 검색 로그 기반
<query, clicked-playlist> 쌍 — 다양하나 품질 불균일
- 메타데이터 기반 synthetic 쌍 — EPL/CPL의 title/description으로 생성, 품질 통제 가능
- 생성 모델 기반 synthetic 쌍 — LLM이 플레이리스트 전체 메타데이터에서 query 합성
- Amazon Titan text embedding을 활용해 synthetic/저성능 query에서
<query, playlist> 쌍 생성
- LLM expert labeller로 각 쌍의 관련도 scoring → positive/negative example 구분
3. Semantic Model Fine-Tuning
- PEFT (Parameter-Efficient Fine-Tuning) 기법 활용
- LoRA (Low-Rank Adaptation): transformer layer에 학습 가능한 저랭크 행렬 추가
- full fine-tuning 대비 파라미터 수 대폭 감소
- 원본 pre-trained weight 보존 → catastrophic forgetting 방지
- 빠른 실험 사이클 가능
4. 평가: LLM-as-Judge
- 기존 평가의 한계: 새로운 트래픽 패턴/쿼리 구조 등장 시 정적 데이터셋으로 부족
- LLM expert judge를 소량의 human annotation으로 bootstrapping
- human judgment를 근사하는 평가 자동화
- 모델 반복 개발 가속화 + 프로덕션 모델 일별 모니터링에도 활용
실험 결과
- 평가 데이터셋 3종 모두에서 Recall@K 대폭 개선
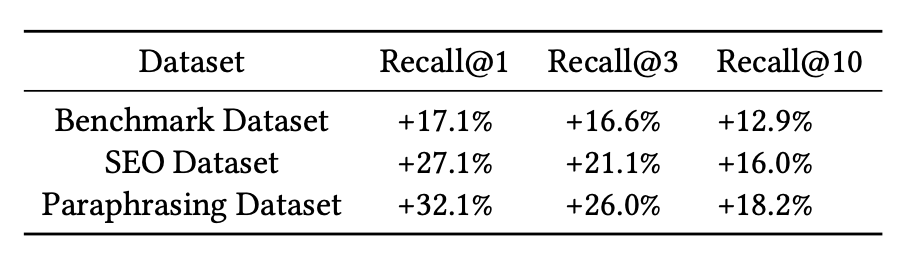
- Paraphrasing Dataset에서 가장 큰 개선 → LLM이 생성한 synthetic paraphrase 데이터가 bi-encoder 일반화에 특히 효과적
남은 과제
- 데이터 품질: CPL enrichment는 customer-facing은 아니지만, 여전히 human oversight 필요
- 확장성: 대규모 데이터셋에 LLM 적용 시 인프라/최적화 전략 요구
- 해석 가능성: LLM-as-judge의 판단 근거 해석 및 신뢰할 수 있는 평가 프레임워크 부재