Intro
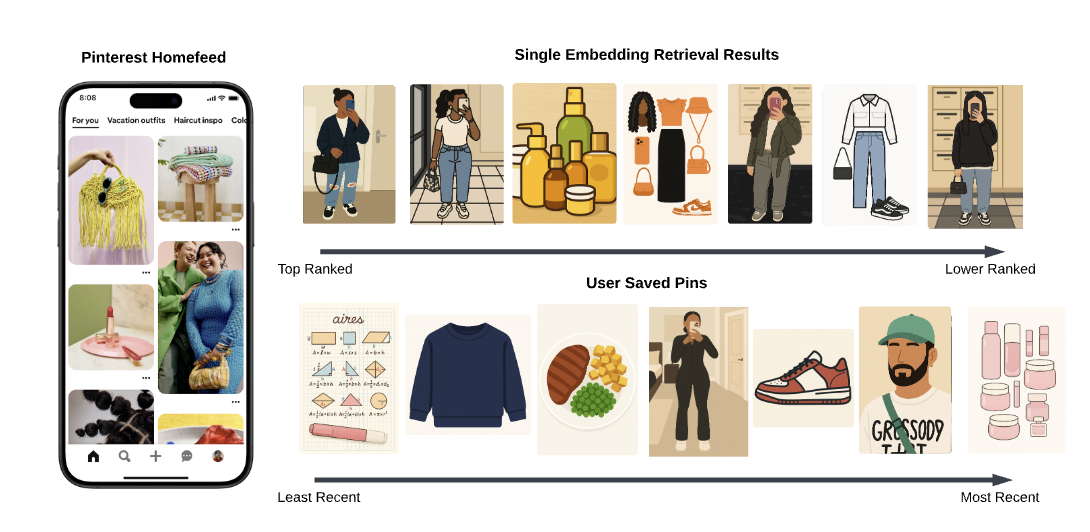
- 기존 모델의 failed case
- user의 saved pins(explicit feedback)을 보면 음식, 교육, 뷰티 등 다양한 관심사가 있지만 vanilla two-tower model 하나의 retrieval 결과만으로는 이를 커버하지 못함
- 왜 이런 현상이 발생하는가?
- 유저 임베딩에 head interest bias가 심함 (사용자가 가장 많이 관심을 보인 주제가 dominant하게 임베딩을 끌고감)
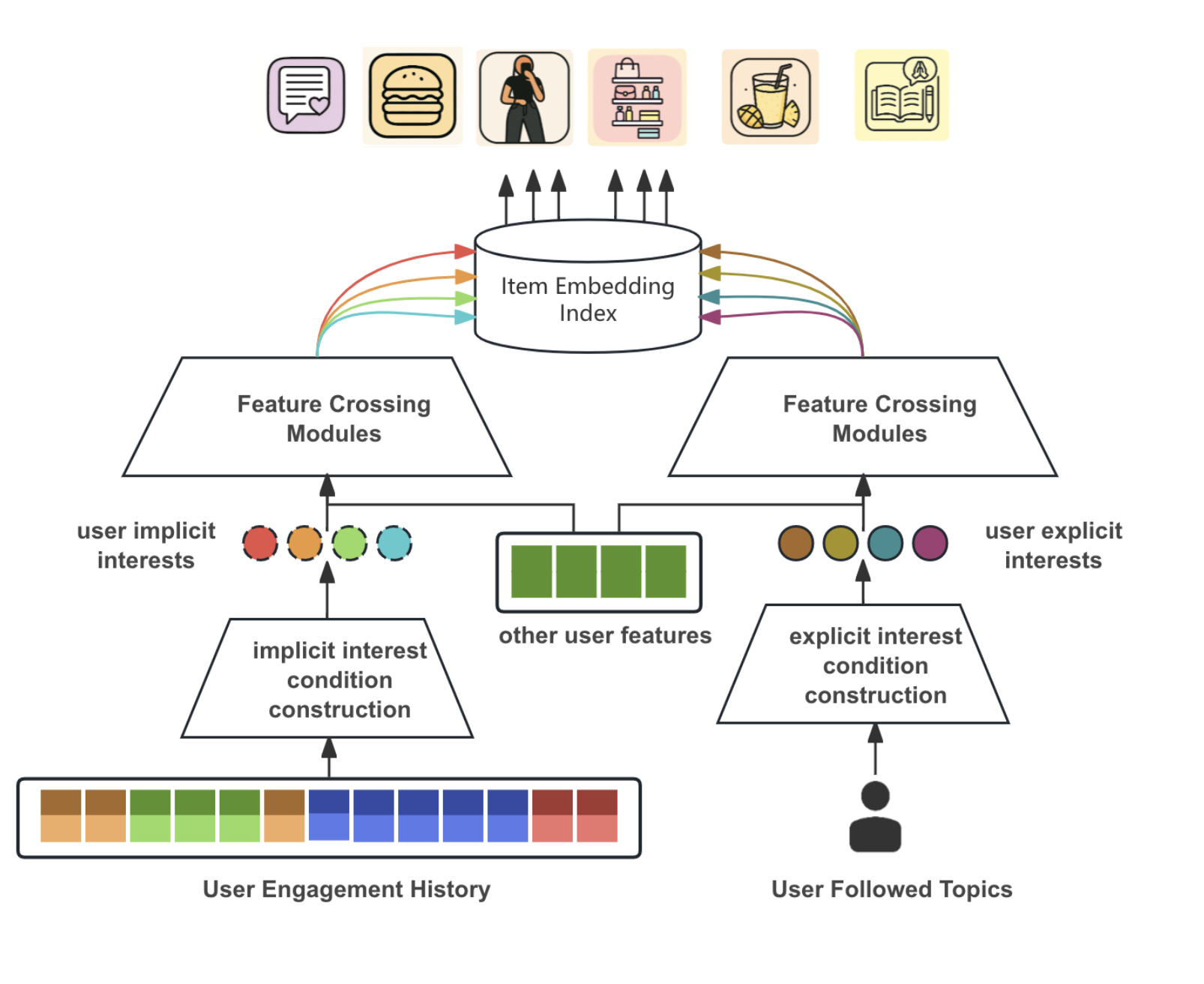
- 이런 문제를 해결하기 위해 multi-embedding retrieval framework를 제안
- 아이디어
- 일반적인 two-tower model에서는 유저를 하나의 유저 임베딩으로 인코딩하는데 이 유저 임베딩에는 사용자의 모든 관심사를 “평균적으로” 또는 “가장 지배적인” 형태로 하나의 벡터에 담게 됨
- 하지만 이 프레임워크에서는 유저 임베딩을 특정 condition에 기반하여 생성하고자 함
- condition = 사용자의 여러 잠재적/명시적 관심사 중 하나. pinterest 도메인에서는 핀의 토픽이라고 생각해도 좋을 듯 e.g. 요리, 여행, 교육,…
- 그래서 각 condition에 따라 같은 유저에 대해서도 다른 임베딩이 학습됨 → multi-embedding
- 사용자가 하나의 종합적인 관심사만 가지고 있는 것이 아니라, 여러 개의 독립적이거나 부분적으로 겹치는 관심사를 가지고 있으며, 이들 각각의 관심사에 따라 아이템에 대한 선호가 달라질 수 있다는 가정을 반영
- retrieval 시에도 이 유저별 여러 조건부 임베딩을 다 사용하여 ANN을 수행
- 이 condition을 어떻게 만들 것이냐에 대해 2가지 방식
-
- Implicit UserInterest Modeling = Differentiable Clustering Module
-
- Explicit User Interest Modeling = Conditional Retrieval
-
Implicit User Interest Modeling
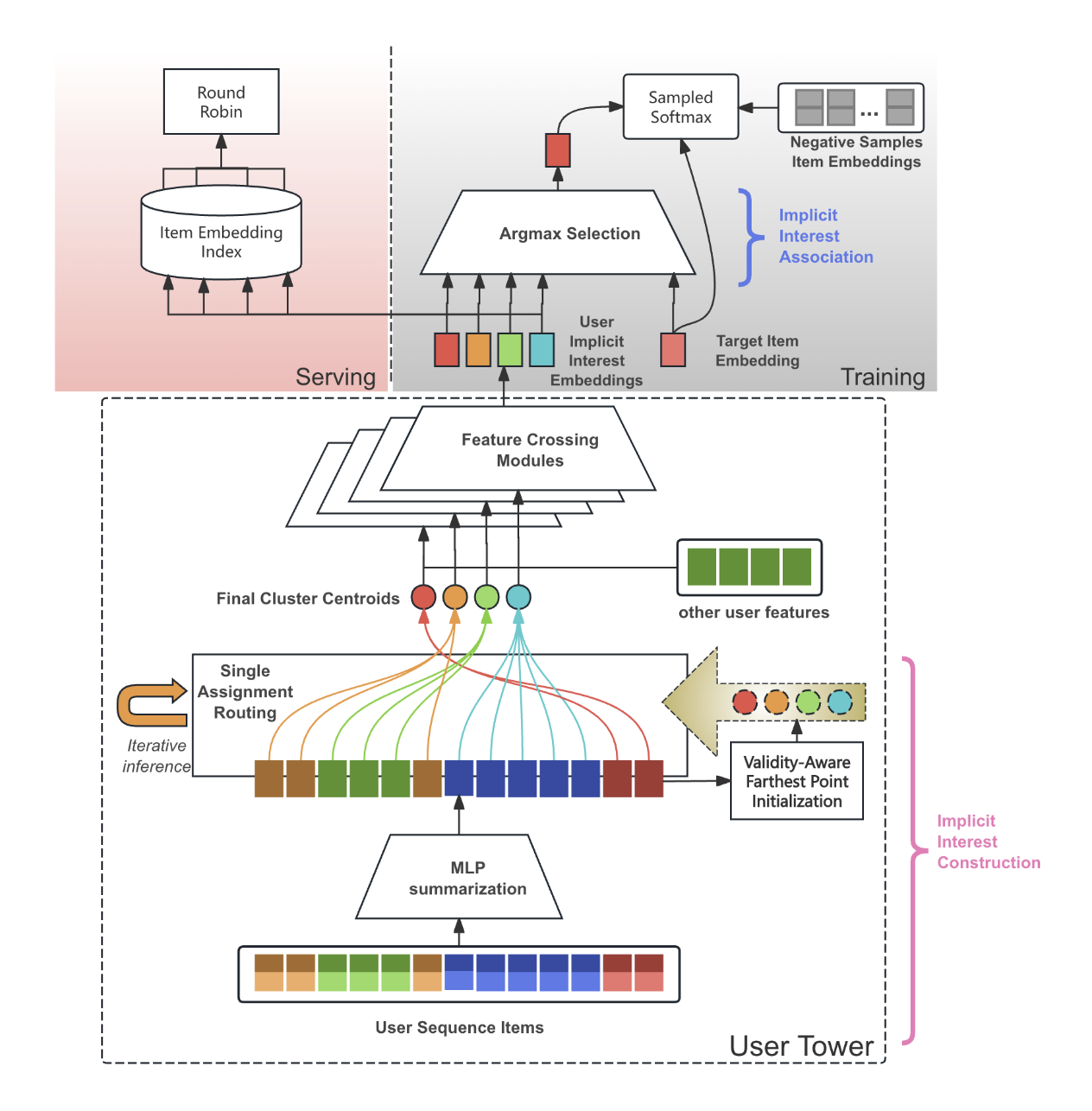 Differentiable Clustering Module
ref) MIND(Multi-Interest Network with Dynamic Routing for Recommendation at Tmal), Chao Li et al., 2019
Differentiable Clustering Module
ref) MIND(Multi-Interest Network with Dynamic Routing for Recommendation at Tmal), Chao Li et al., 2019
- Condition Construction
- 사용자의 행동 기록에 있는 개별 아이템들을 여러 개의 잠재적 관심사 클러스터로 묶어 사용자 임베딩을 생성
- Validity-Aware Farthest Point Initialization (VA-FPI) → cluster centroids : 클러스터 중심을 초기화할 때, 기존 중심들과 가장 먼 아이템을 선택하며, 이 과정에서 유효하지 않은(invalid) 아이템은 필터링함 (클러스터들이 서로 충분히 다양하게 퍼져있도록 하여 사용자 관심사의 다양한 스펙트럼을 포착)
- Single-Assignment Routing (SAR):
- 각 아이템 임베딩이 각 클러스터 중심에 얼마나 강하게 연결되어야 하는지를 나타내는 라우팅 가중치를 계산(내적을 통해)하고 클러스터 중심을 업데이트하는 것을 반복
- 클러스터 centroid는 자신과 강하게 연결된 모든 아이템 임베딩의 가중평균 + squash 함수(비선형 활성화 함수)
- 각 아이템이 여러 클러스터에 기여할 수 있는 기존 방식과 달리, 가장 유사한 하나의 클러스터 중심에만 할당되도록 함 (클러스터 중심들이 서로 수렴하여 붕괴하는 것을 방지하고, 각 클러스터가 고유한 관심사를 나타내도록)
- 각 아이템 임베딩이 각 클러스터 중심에 얼마나 강하게 연결되어야 하는지를 나타내는 라우팅 가중치를 계산(내적을 통해)하고 클러스터 중심을 업데이트하는 것을 반복
- 수렴하여 최종적으로 얻은 centroid가 바로 조건부 사용자 임베딩이 됨
- 사용자의 행동 기록에 있는 개별 아이템들을 여러 개의 잠재적 관심사 클러스터로 묶어 사용자 임베딩을 생성
- Condition Association
- 모델 학습 시, 특정 타겟 아이템과 여러 사용자 관심사 임베딩 중 어떤 것이 가장 관련 있는지 연결
- 타겟 아이템과 유사도가 가장 높은 사용자 관심사 임베딩 하나를 선택 (argmax selection) 해서 손실 함수(sampled softmax loss)를 계산
- 즉, 하나의 긍정적인 행동을 가장 잘 설명하는 사용자 관심사 임베딩에만 집중하여 학습
- 모델 학습 시, 특정 타겟 아이템과 여러 사용자 관심사 임베딩 중 어떤 것이 가장 관련 있는지 연결
Explicit User Interest Modeling
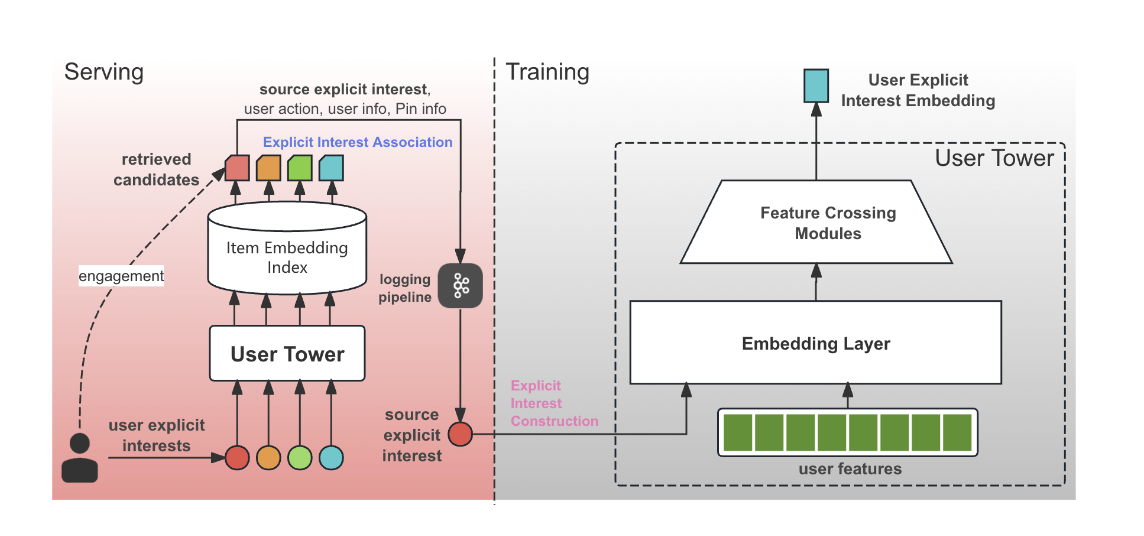 Conditional Retrieval
Conditional Retrieval
- Condition Construction
- 사용자가 명시적으로 팔로우하는 토픽과 같은 신호(explicit signals)를 직접 임베딩으로 변환
- 이 조건 임베딩은 사용자 타워(user tower) 내의 피처 교차(feature crossing) 레이어를 거쳐, 사용자와 조건 간의 고차원 상호작용을 학습 → 조건부 사용자 임베딩
- item tower는 일반적인 Two-Tower Model과 동일
- 사용자가 명시적으로 팔로우하는 토픽과 같은 신호(explicit signals)를 직접 임베딩으로 변환
- Condition Association
- 데이터 로깅(data logging) 시점에 이루어짐!
- 사용자가 특정 아이템에 상호작용했을 때, 그 아이템을 추천한 소스 관심사(source interest)(예: 사용자가 팔로우하는 어떤 토픽 때문에 이 아이템을 보게 되었는지)가 기록
- 이와 같이 기록된 “(조건, 사용자, 아이템)” 쌍이 학습 데이터로 사용
- 추가적으로, 아이템과 토픽 간의 신호(item-to-topics signals)를 기반으로 관련성 필터(Explicit Relevance Filter)를 적용
- 즉 검색된 아이템이 실제로 해당 조건과 의미론적으로 관련성이 높은지 (예: ‘Food’ 토픽으로 검색된 아이템이 정말 음식 관련 아이템인지)를 확인하고, 관련성이 떨어지는 아이템을 제거하는 후처리를 거쳤음
- 데이터 로깅(data logging) 시점에 이루어짐!
Deployment
- 각각의 모델에서 생성된 여러 개의 사용자 임베딩 각각을 독립적으로 사용해서 각 임베딩 별로 candidates를 ANN으로 가져옴
- implicit 관심사 임베딩들에서 후보군을 우선순위(클러스터 중요도)에 따라 일정 수 배정해 뽑기 (온라인 성능을 저하시키는 torso/tail 후보군을 과도하게 가져오는 것을 방지)
- explicit 관심사 임베딩들에서 (랜덤하게 개 선정) 일정 수씩 균등하게 후보를 뽑기
- 마지막으로 모든 후보들을 중복제거, round-robin 방식으로 균형 있게 섞어 최종 candidates를 만들기
- 150ms → 205ms의 p90 레이턴시 증가가 있지만 limit을 넘지는 않음
- serving cost고려해서 임베딩할 후보 수를 줄여서 single embedding retrieval과 동일한 budget을 유지함
Results
- implicit interest 모델은 주로 단기 관심사를 포착, 활성 사용자에게 유용
- explicit interest 모델은 장기/롱테일 관심사를 보완, 신규/저신호 사용자에게 유용
- 두 모델이 생성한 후보 간 겹치는 정도는 3.2%에 불과하여 강력한 상호 보완성을 시사
Experiment
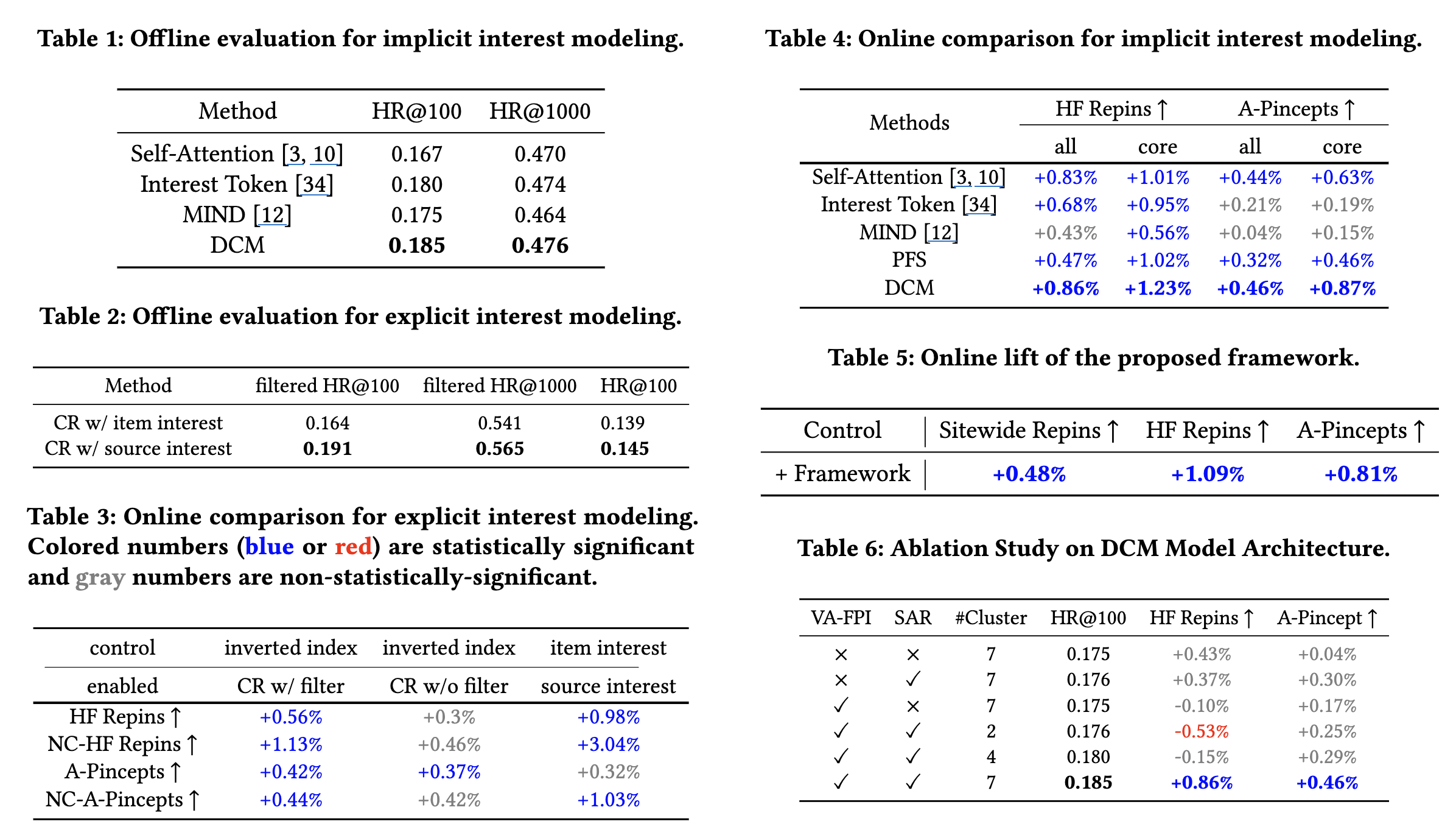
- 오프라인 평가
- DCM은 HR@100과 HR@1000에서 Self-Attention, Interest Token, MIND, PinnerFormer Subsequence (PFS) 기반 모델을 포함한 다른 암시적 관심사 모델들을 능가
- CR의 경우, 액션 로깅 시점의 소스 관심사를 사용하고 필터링을 적용한 모델이 가장 우수
- 온라인 A/B Test
- DCM은 HF Repins 및 Adopted Pincepts(온라인 참여 다양성 지표)에서 유의미한 개선을 보임
- CR은 비핵심 사용자(non-core users)의 HF Repins를 크게 향상시켜, 각 모델이 다른 사용자 세그먼트에서 강점을 가짐을 입증
- 전반적으로 Sitewide Repins, HF Repins, A-Pincepts에서 상당한 상승
- Ablation
- DCM의 VA-FPI와 SAR 구성 요소가 클러스터 중심의 다양성을 높이고 온라인 성능을 크게 향상시키는 데 필수적임
- 클러스터 수가 적으면 온라인 성능이 저하