Note
RQ-VAE로 학습한 Semantic ID를 음악 추천에 적용해 파라미터를 최대 99% 줄이면서 추천 정확도를 유지하고, 10M Pandora 유저 A/B 테스트에서 트랙 다양성을 유의미하게 개선
- 파라미터 수 ~75%(Pandora), ~99%(Spotify) 절감하면서 baseline 성능 유지 또는 초과
- 절감된 파라미터 예산을 모델 복잡도(hidden dim h) 증가에 재투자 가능 → 정확도 추가 향상
- 저피드백 유저에서 정확도 및 다양성 향상 효과가 가장 크게 나타남
Background
- 음악 스트리밍 서비스는 수천만 곡 규모의 카탈로그를 보유
- 전통적인 item id based 임베딩 모델은 개의 파라미터가 필요 (N: 카탈로그 크기, h: hidden dim)
- 메모리 부족으로 인해 h가 제한되거나, 모델이 실시간 서빙에 비용이 너무 많이 드는 문제 발생
- 기존 파라미터 절감 접근법의 한계
- Hashing: 아이템 충돌 위험, 유사 아이템 간 구조 없음 (같은 아티스트 곡이 전혀 다른 hash를 가질 수 있음)
- Embedding factorization (학습 전): cold-start 불가 (피드백 없는 신규 아이템 일반화 불가)
- Embedding factorization (학습 후): 학습 시점의 모델 복잡도는 여전히 제한됨 → underpowered model
Method
Semantic ID 개요
- 아이템을 -tuple of codewords로 표현:
- 각 는 크기 의 codebook에서 선택
- 본 논문: , 는 하이퍼파라미터 (1024~32768)
- 예: 이면 아이템 인코딩 가능
- 비교 대상
- v0 (random): 각 아이템에 랜덤 ID 할당 → 콘텐츠 구조 없음, hashing trick과 유사
- v1 (trained): 콘텐츠 피처를 이용해 유사 아이템이 같은 codeword를 공유하도록 학습
RQ-VAE 기반 Semantic ID 학습
- RQ-VAE (Residual Quantized VAE) 사용 → 콘텐츠 임베딩을 이산적인 codeword tuple로 압축
- Tie-breaking 차원 추가: 번째 차원은 학습하지 않고, 앞 4개의 codeword가 동일한 아이템에 대해 순서대로 증가
- → 즉, 콘텐츠가 거의 동일한 아이템들 사이에서의 충돌을 해결하기 위한 장치
- 입력 피처
- Spotify: 8-dim audio vector + content attributes (speechiness, danceability, energy 등, popularity 제외)
- Pandora: proprietary audio embedding + metadata embedding (genre, release year 등)
베이스 모델
- SASRec 기반 transformer (self-attentive sequential recommendation)
- Baseline: Track embedding = song embedding + artist embedding + genre embedding (Pandora 기본 설정 = song decomposition )
- Spotify는 artist/genre 정보 없어 song embedding만 사용 = song only
- Semantic: song embedding 부분만 n-dim semantic ID로 교체, 나머지는 동일
Experiments
데이터셋
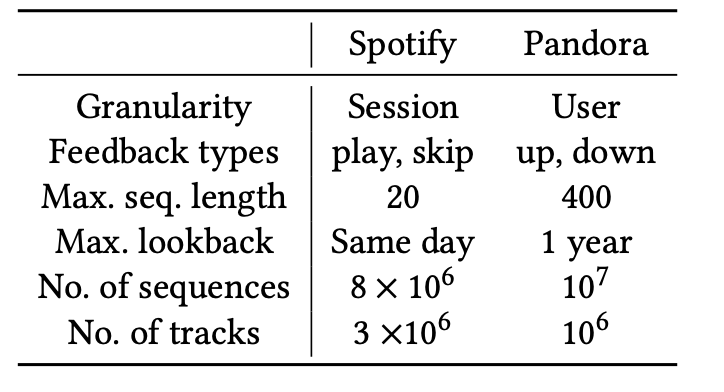
-
두 데이터셋의 규모와 피드백 유형이 크게 다름 → 결과 해석 시 맥락 고려 필요
-
평가 지표: stratified AUC (positive/negative pair ranking accuracy)
-
학습/검증과 시간적으로 분리된 테스트셋 사용 (이후 2주 피드백)
오프라인 평가 결과
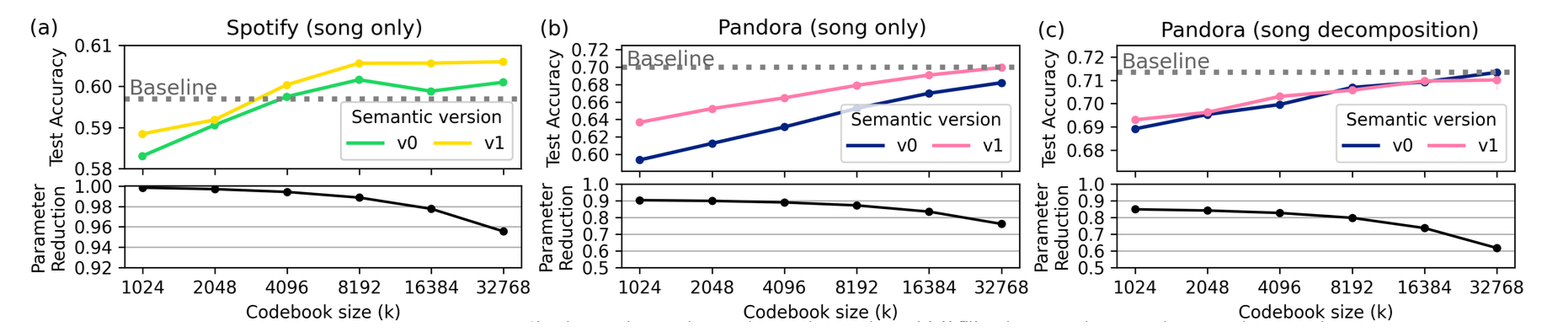
-
v1 semantic ID가 v0보다 song-only case(a, b)에서 일관되게 높은 정확도; song-decomposition case(c)에서는 v0 ≈ v1
-
Spotify: k=4096에서 baseline 일치, k=8192에서 baseline 초과 (v0, v1 모두)
-
Pandora song-only: v1 k=32768에서 baseline 일치 (~75% 파라미터 절감)
-
Song decomposition (artist+genre embedding 추가)
- v0와 v1 간 차이 거의 없음
- artist/genre embedding이 semantic ID와 유사한 역할(유사 아이템 간 파라미터 공유)을 이미 수행하기 때문
- 단, artist/genre embedding만 사용하면 정확도 ~10% 하락 → semantic ID(v0 포함)가 여전히 기여
- 이러한 기여는 콘텐츠 구조가 아닌 모델 regularization 효과일 가능성
- ALBERT) 임베딩을 여러 레이어가 공유하도록 강제하면 일반화 성능이 올라감
- 여기서도 N개의 곡이 k^n 개의 codeword 조합을 공유해야 해서 특정 곡 id에 과적합하지 않는 regularization 효과가 발생
- 이러한 기여는 콘텐츠 구조가 아닌 모델 regularization 효과일 가능성
k vs h 트레이드오프
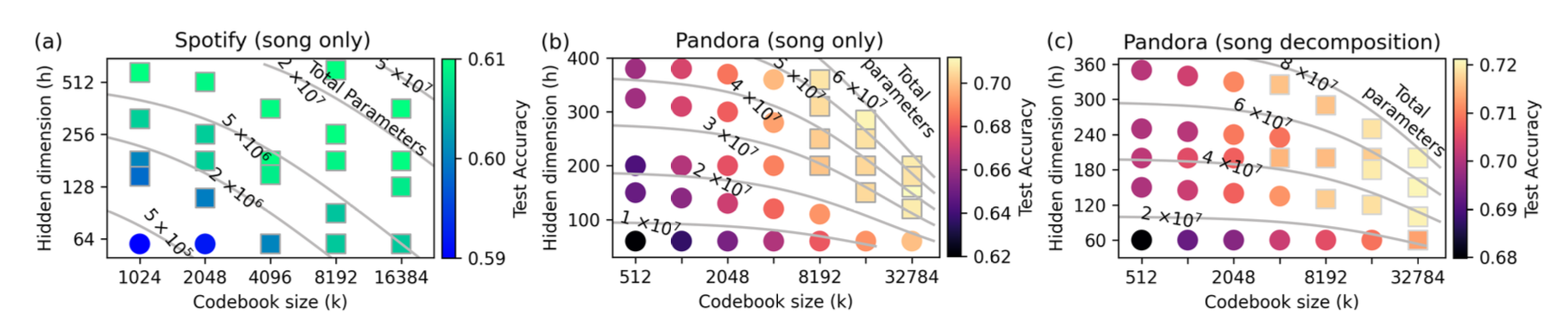
-
k(codebook size)와 h(hidden dim)를 동일 파라미터 예산 내에서 조절했을 때의 test accuracy 비교
-
Spotify는 k와 h 증가 모두 효과적; Pandora는 h 증가보다 k 증가가 명확히 더 유리
-
Spotify: 파라미터가 많을수록 정확도 향상 (k, h 어느 쪽이든)
-
Pandora: 동일 파라미터 예산에서 k 증가가 h 증가보다 효과적
-
- 왜 이런 차이가 나는가? implicit feedback(play/skip) vs explicit feedback(up/down) 차이가 원인일 수 있음. implicit은 노이지하므로 일단 모델 크기를 키워서 표현력을 높이는 게 효과 (그냥 가설임)
-
-
Semantic ID의 계층 구조 특성상 초기 layer에 더 작은 codebook을 사용하는 전략도 탐색 가치 있음
- RQ-VAE는 순차적으로 quantize (1차 근사 → 남은 residual 근사 → 반복 …)하기 때문에 앞의 codeword일수록 더 많은 정보(큰 분류), 뒤로 갈수록 더 세밀한 차이를 담음. 즉 앞쪽 layer는 k가 작아도 충분히 대표할 수 있어서 모든 n=4차원에 동일한 k를 가져갈 필요는 없지 않을까 하는 아이디어
유저 활동 수준별 lift
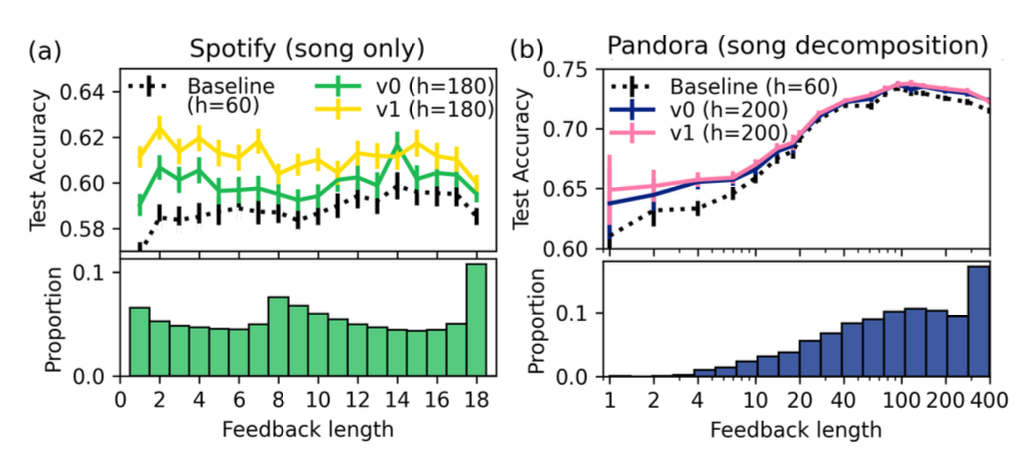
-
저피드백 유저에서 lift가 가장 크며, v1과 v0 간 차이도 song-only case에서 더 뚜렷함
-
Pandora, Spotify 모두 저피드백 유저에서 가장 큰 정확도 향상
-
Pandora는 매우 고피드백 유저에서도 약간의 lift 관찰
온라인 A/B 테스트
- 10M Pandora 청취자, 30일, 동일 비율 control/test 분할
- Semantic 모델: k=16384, h=120, ~50% 파라미터 절감, 학습 비용 ~20% 절감
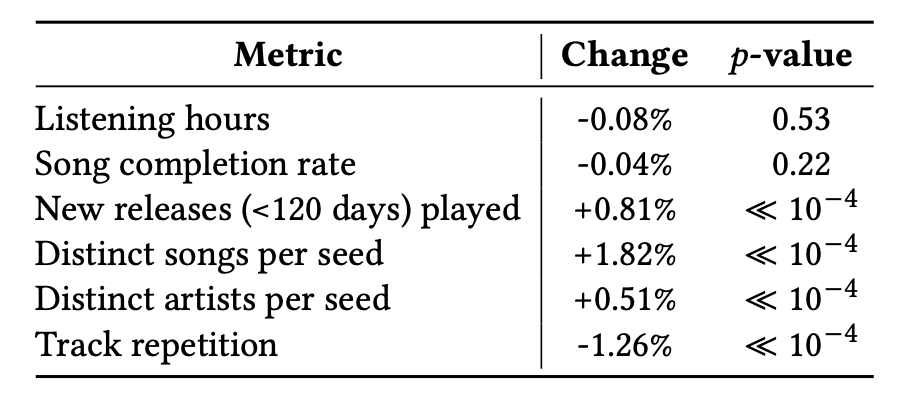
- 청취 시간(-0.08%, p=0.53), Song completion rate(-0.04%, p=0.22) 등 핵심 비즈니스 지표는 중립
- Distinct songs per seed +1.82%, Track repetition -1.26%, New releases +0.81% 등 다양성 지표는 통계적으로 유의미한 개선 (p≪10⁻⁴)
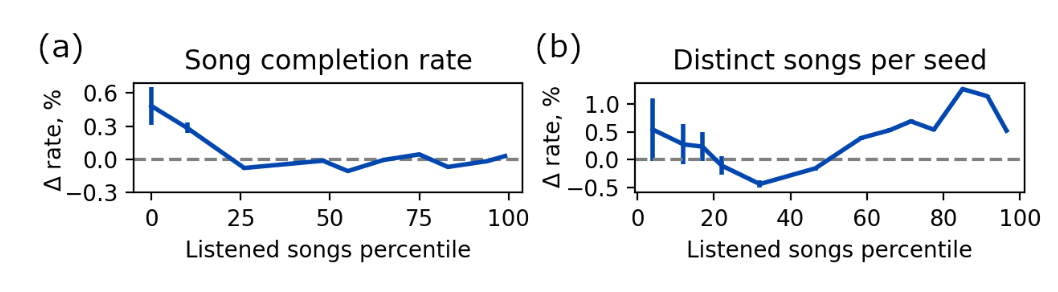
- 저활동 유저에서 song completion rate가 유의미하게 증가
- 고/저활동 유저 모두에서 다양성 증가가 두드러짐
- 전반적 청취 시간은 중립이지만, 저활동 유저 song completion rate 증가는 장기적으로 저활동 → 고활동 전환 가능성 시사
💭
- pandora에서 artist/genre embedding이 추가되면 v1(trained)과 v0(random) 성능 차이가 없어진다는 것
- spotify 데이터셋은 애초에 song 정보가 거의 순수 오디오 피쳐였던 것 같은데 pandora의 경우 오디오 피쳐 + 장르/연도 같은 메타를 섞었다고 함. song only에서는 v0,v1 차이가 있고 artist/genre 추가하면 v0,v1차이가 없다는 건 결국 장르 메타가 핵심적인 기여였던 거 아닌가. 근데 spotify에서는 v1 > v0 차이가 나기 때문에 이쪽에서는 오디오 피쳐가 유의했다는 건데, 이건 2가지 데이터셋의 오디오 피쳐 자체도 달랐을 거라 좀 애매한 결론이 되는 듯..