Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations (2024)
이전 Semantic IDs, Generative Retrieval (TIGER)의 접근을 ranking에 확장
Semantic ID Generation
- 우선 아이템의 콘텐츠 임베딩이 밑재료가 됨
- 아이템에 대한 텍스트 설명(e.g. 이름, 가격, 브랜드, 카테고리 등)을 sentence-T5나 BERT 같은 범용 사전훈련된 텍스트 인코더를 사용해 dense semantic embedding을 얻음
- Residual Quantization(RQ-VAE) : 이 임베딩들을 각 크기를 가지는 개의 코드북을 사용해 길이 의 코드워드의 튜플로 바꾸면 이게 바로 semantic ID가 됨
/rq-vae.png)
- 구성
- 인코더: 입력 dense embedding 를 잠재 표현 로 바꾼다.
- RQ: 번의 quantization을 반복한다.
- 첫번째 코드북에는 와 같이 개의 벡터가 존재하며, 이중에서 와 가장 가까운 을 찾는다. 그림에서는 → 이게 첫번째 코드워드가 됨.
- 이때 완전히 동일하진 않을 것이므로 잔차(의 절대값)가 발생하는데, 이를 이라고 하고 다음 코드북으로 넘기자.
- 두번째 코드북 에서 개의 벡터 중 과 가장 가까운 을 찾는다. 그림에서는 = 1 → 두번째 코드워드.
- 여기서 또 잔차가 발생하므로 다시 를 다음 코드북으로 넘기자.
- 이를 코드북 개수 만큼 반복하면 개의 코드워드(가장 가까웠던 벡터의 인덱스)와 함께 각 단계에서 선택되었던 벡터 를 얻게 됨
- 첫번째 코드북에는 와 같이 개의 벡터가 존재하며, 이중에서 와 가장 가까운 을 찾는다. 그림에서는 → 이게 첫번째 코드워드가 됨.
- 디코더: 선택되었던 벡터들의 합이 의 quantized representation 가 되고 이를 decoder가 인풋으로 가져감. 최종적으로 디코더의 출력
- 기본적으로 auto encoder구조이므로 인코더-디코더를 거쳐 원래의 embedding이 잘 복원되도록 해야 하고 동시에 quantization 과정에서 정보 손실이 적어야 함 → 이 2가지 목적을 손실함수로 두고 인코더, 코드북, 디코더의 파라미터를 학습하게 됨
- Reconstruction Loss : 입력 과 디코더의 출력 간의 차이
- Quantization Loss:
- 는 stop-gradient operation (역전파할 때 안에 있는 값을 무시하고 상수 취급)
- 첫번째 항은 잔차와 선택되는 벡터를 가깝게 하되 잔차에 대해서는 학습하지 않고 코드북 내의 벡터들을 잔차에 가깝게 조정
- 두번째 항은 인코더의 출력이 선택된 코드북 벡터에 더 가까워지도록 하되 코드북 벡터는 냅두고 인코더가 코드북 벡터로 잘 표현될 수 있는 값을 내보내도록 유도
- 충돌 처리
- 여러 아이템이 동일한 semantic ID를 가지게 되는 것을 방지하기 위해 맨 마지막에 추가 토큰을 하나 더 붙여줌 e.g. 두 아이템이 Semantic ID (12, 24, 52)를 공유하는 경우(12, 24, 52, 0) 및 (12, 24, 52, 1)로 나타내어 구별
Semantic ID representation in Ranking
- SID는 코드워드의 튜플이므로 이를 랭킹 모델에서 피쳐로 사용하려면 학습 가능한 continuous 임베딩으로 변환해야 하는데 2가지 방법이 존재
- N-gram-based: SID 코드를 길이 N의 subword로 그룹화
- 각 서브워드에는 학습 가능한 임베딩이 연결되어 N-gram 내의 의미론적 관계를 포착
- 아이템 표현은 아이템 내 모든 N-gram 서브워드 임베딩의 합으로 구성됨
- 예를 들어, Unigram (N=1)이면 개의 개별 코드 를 가지며, Bigram (N=2)은 L/2개의 연속된 코드 를 가짐
- 각 N-gram 그룹에 대해 별도의 임베딩 테이블이 학습됨 - 각 코드의 카디널리티가 K이므로, N-gram 그룹의 임베딩 테이블은 개의 행을 가지고 이 커질수록 메모리 부담 증가
- SPM-based (SentencePiece Model): impressed items의 분포를 기반으로 Semantic ID 서브워드를 동적으로 학습하여 가변 길이의 서브워드를 생성함
- 자주 함께 발생하는(co-occurring) 코드를 단일 서브그룹으로 자동 결합하고, 드물게 발생하는 코드는 그냥 Unigram으로 둠
- 각 행이 특정 가변 길이 서브피스에 해당하는 단일 임베딩 테이블을 학습하는데 이 테이블 크기는 고정(e.g. 딱 50K 서브워드만 쓰겠다)
- N-gram-based: SID 코드를 길이 N의 subword로 그룹화
Experiment
- setup
- Youtube 다음에 시청할 비디오 추천에 사용되는 production ranking model
- 조건: 임베딩 테이블 크기의 메모리 제한(그래서 n-gram은 n⇐2까지밖에 못함), 사용자 요청에 대한 즉각적인 응답
- SID의 재료가 되는 dense embedding은 비디오 인코더 사용 (Video-BERT를 백본으로 사용하고 오디오/비주얼 피쳐를 인풋으로 사용하여 2048차원 임베딩을 출력하는 트랜스포머 모델)
- SID 생성시 8개 코드북, 각 코드북은 2048개 크기
- 주 비교대상
- SID (sementic id)
- Dense Input (원래 dense embedding 그대로 사용)
- 단 이렇게 하면 임베딩 테이블 파라미터는 없는 것이므로 모델 크기가 작게 됨. 공정한 비교를 위해 랭킹 모델 레이어를 1.5배/2배 늘려보기도 함
- Random Hashing (각 아이템에 랜덤 ID가 있고 그걸 embedding table로 lookup해서 학습되게 하는 전통적 CF 방식)
- N일 데이터에 대해 순차적 학습 후 N+1일차 CTR( 그리고 N+1일에 새로 생긴 콜드스타트 아이템에 대한 CTR은 CTR/1D) 대한 AUC로 평가
- CTR(all): memorization, CTR/1D(cold start): generalization
- Youtube 다음에 시청할 비디오 추천에 사용되는 production ranking model
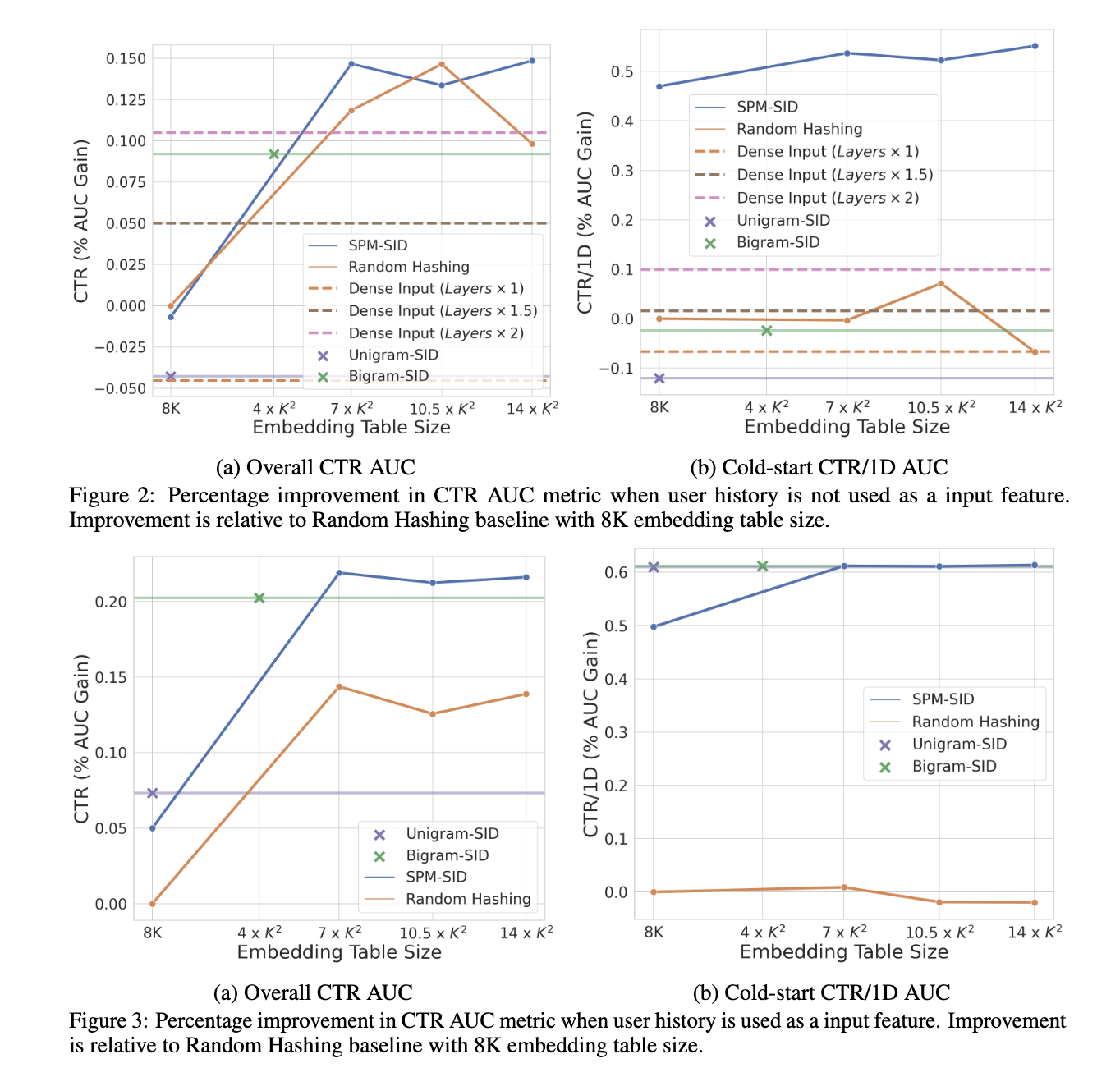
- figure3) 사용자 히스토리(유저 개인화)를 함께 사용
- figure2) 사용자 히스토리 없이 지금 비디오 + 후보 비디오만 입력(즉 비디오간 유사성만으로 CTR 예측)
- dense input 은 random hashing 대비 성능이 떨어짐 = 랭킹 모델은 ID기반 임베딩 테이블을 memorization하는 것에 크게 의존하고 있음
- dense input도 1.5x ~ 2.x로 레이어를 증가시킬 경우 성능이 비슷하게 올라가긴 함. 다만 서빙 비용도 함께 증가하여 실용성은 떨어짐.
- unigram SID, bigram SID 모두 random hashing 대비 성능이 떨어짐 = 학습 데이터의 컨텐츠의 등장 빈도 분포가 불균형해서, 임베딩 테이블 업데이트가 sparse하기 때문일 것으로 추정 (잘 안쓰이는 n-gram도 동일하게 임베딩 테이블을 차지하므로 거의 학습이 안된 n-gram이 많이 존재할 수 있음)
- SPM SID는 상대적으로 자주 등장하는 코드 조합을 묶어서 vocab으로 관리하고 vocabulary 크기를 제한하므로 미학습되는 slot이 거의 없게 dense하게 업데이트함
- figure3에서 사용자 히스토리를 함께 사용하면 n-gram sid도 random hashing보다 나아지는데 유저가 시청한 다양한 비디오 컨텐츠가 포함되어서
- SPM SID는 일정 사이즈 이상의 임베딩 테이블 사용시 N-gram보다 지속적으로 우수한 성능을 보이고 특히 cold-start CTR/1D에서 더 나은 일반화 능력을 보임
- 대부분의 production ranking model은 좋은 품질을 위해 큰 임베딩 테이블을 필요로 하므로 SPM SID가 유용하게 쓰일 수 있을 것으로 판단
- dense input 은 random hashing 대비 성능이 떨어짐 = 랭킹 모델은 ID기반 임베딩 테이블을 memorization하는 것에 크게 의존하고 있음
한줄요약하면 Random Hashing 기반 item embedding은 memorize는 잘하지만, generalize는 못하고 (Dense embedding은 풍부한 피쳐일지라도 memorize를 못해서 성능이 떨어지고) Semantic ID는 반대로 의미적 표현은 담으면서 ID로 기능하면서 적당한 memorization + generalization을 한다.
- N-gram SID v.s. SPM SID
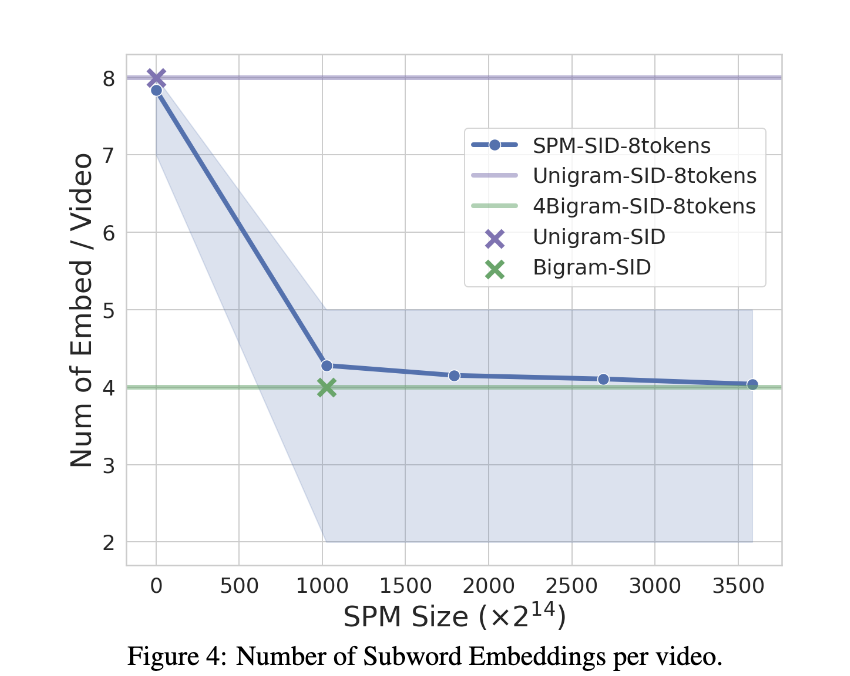
- N-gram SID는 N에 따라 임베딩 테이블 크기가 정해지지만 SPM-SID는 주어진 임베딩 테이블 크기에 맞춰서 동적으로 서브워드를 생성함
- 물론 위 figure2,3에서처럼 임베딩 테이블 크기가 어느정도 되어야 좋은 성능을 보이는데 7K^2 이상부터는 성능향상이 별로 없음
- bigram SID는 L=8일때 4K^2이고 (N을 더 늘리면 현실적으로 불가능함) 따라서 SPM SID는 bigram SID와 유사한 수준의 임베딩 테이블로 더 좋은 성능을 얻을 수 있다고 보면 됨
- 임베딩 테이블 조회 비용에서도 SPM이 더 최적인데 N-gram은 L=8, N=2일 때 4개의 bigram 그룹이 생기므로 그만큼 임베딩 룩업이 필요하고 이는 모든 아이템에 동일하게 고정적으로 해당됨. 반면 SPM은 head item은 자주 등장하는 서브워드로 하나로 묶여있으므로 동적으로 룩업 수가 감소.
- N-gram SID는 N에 따라 임베딩 테이블 크기가 정해지지만 SPM-SID는 주어진 임베딩 테이블 크기에 맞춰서 동적으로 서브워드를 생성함
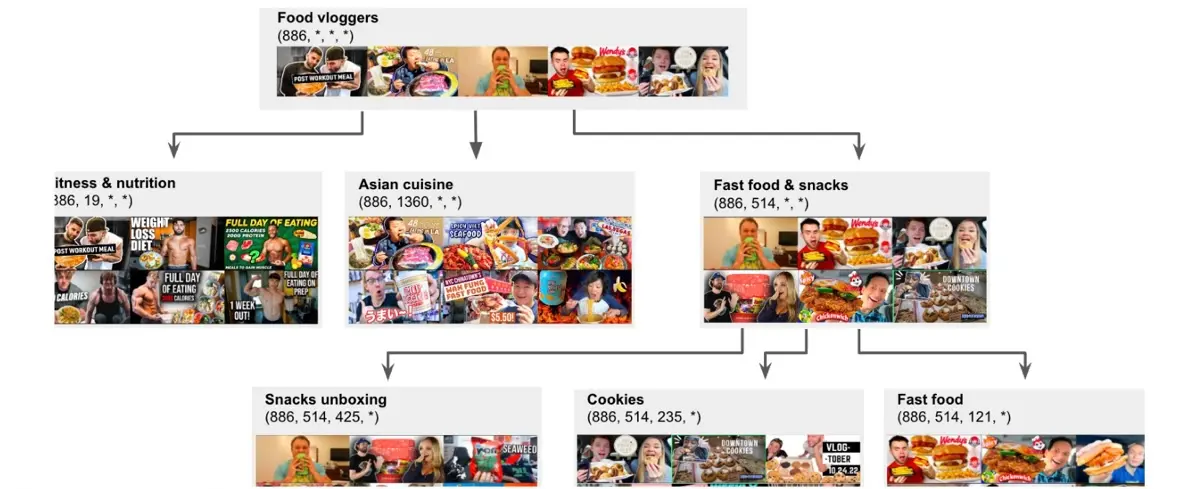
Semantic IDs as hierarchy of concepts
RQ-VAE가 만든 SID는 사실 의미적인 계층구조를 나타내고 있음
(1)
├── (1,2)
│ ├── (1,2,3)
│ └── (1,2,6)
└── (1,4)
├── (1,4,1)
└── (1,4,9)
이런 식으로 trie구조를 만들면 첫번째 코드워드는 상대적으로 상위 개념, 뒤로 갈수록 하위(fine-grained) 개념
- 두 비디오를 비교할 때 앞부분 코드가 얼마나 동일한지를 (shared prefix length)로 봄
- e.g. (1,2,3,4) ←> (1,2,6,7) 은 2

- 즉 뒤까지 같을수록 consine similarity가 높아지고(비디오가 비슷해지고) 같은 trie안에 속하는 비디오들은 적어진다(의미적으로 점점 세분화된 그룹이 된다)
- 먹방 > 패스트푸드/간식 > 쿠키…