R2k is Theoretically Large Enough for Embedding-based Top-k Retrieval (2026)
배경
- Embedding-based retrieval: universe 의 m개 원소를 에 임베딩, 쿼리 도 벡터로 변환하여 scoring function 으로 top-k 결과를 반환 한다고 할 때,
- 핵심 질문: m개 원소와 모든 top-k 쿼리를 완벽히 답하기 위한 최소 차원 d는 얼마인가?
- 이 최소 차원을 Minimal Embeddable Dimension (MED) 으로 정의
- On the Theoretical Limitations of Embedding-Based Retrieval (2025) 에서는 시뮬레이션한 결과 최소 차원이 m에 대해 polynomial하게 성장한다고 주장
- (Equation 1)
- → 즉 m이 커질수록 필요한 d가 polynomial하게 증가 → 즉 아이템이 많아질수록 차원을 엄청나게 늘려야 하고, 이는 벡터 공간의 근본적 한계라는 결론
- 이 논문은 그 결론을 이론적으로 반박 - MED는 m과 무관하게 2k차원이면 충분하고, 실제 병목은 learnability 문제임을 주장함 (기하 공간은 충분히 넓은데 그냥 딱 맞는 벡터를 뽑아내는 모델을 학습하는 게 어려운 거임)
핵심 개념
k-shattering
- 가 k-shattered by 이면:
- : 의 원소는 보다 크고, 밖의 원소는 보다 작은 score를 가짐
- 즉, 모든 top-k 쿼리를 완벽히 분리할 수 있는 임베딩 구성이 존재함을 의미 Definition (MED): m개 원소를 k-shattered 할 수 있는 최소 차원
VC Dimension과의 관계
- (Lemma 2.7)
- → VC dimension의 역함수가 MED와 연결됨
Centroid Setting (MED-C)
- 기존 연구에서는 아이템 벡터 m개와 쿼리 벡터 개를 최적화했음 → 쿼리 벡터가 문제(m이 늘수록 변수가 폭발적으로 많아지므로 optimizer가 좋은 해를 못 찾음.
- 쿼리 임베딩을 자유롭게 최적화하는 대신, answer set의 centroid로 고정:
- 자유도가 줄어 더 어려운 세팅이지만 시뮬레이션이 훨씬 용이 (개 쿼리 임베딩 최적화 불필요, m개만 최적화)
- (MED가 MED-C의 lower bound)
이론적 결과: MED = Θ(k)
- 어떤 유사도 함수를 쓰든 MED는 m이 아닌 k에 의해 bound가 정해짐
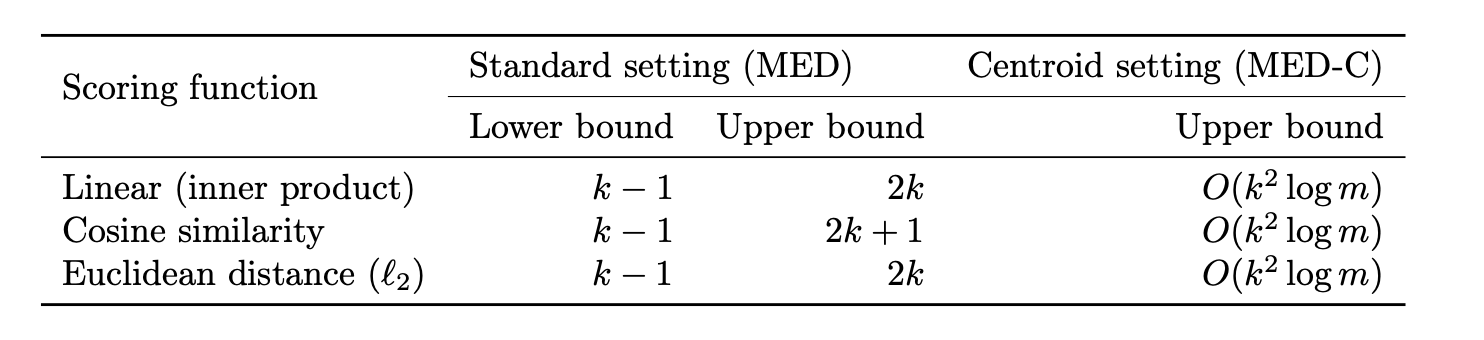
Inner product
- Upper bound: Cyclic polytope 구성을 이용
- Moment curve 위의 점들로 이루어진 cyclic polytope
- 의 cyclic polytope는 -neighborly polytope: 이면 모든 k개 꼭짓점이 face를 형성 → linear separability 보장
- 따라서 이면 모든 top-k 쿼리를 분리 가능
- Lower bound: 의 VC dimension이 임을 이용 (Proposition 2.8)
- 핵심: MED는 m에 의존하지 않는다. 오직 k에 의존함
Euclidean distance
- (Proposition 3.3)
- Linear으로 k-shattered되는 구성이 있으면, 분리 hyperplane에 접하는 ball로 동일한 분리 가능
Cosine similarity
-
- Cosine의 decision boundary = 구(sphere)와 hyperplane의 교선
- Linear → Cosine: inverse stereographic projection으로
- 차원이 최대 1 증가
Centroid Setting: MED-C = O(k² log m)
이론적 upper bound
- Probabilistic method 사용: 을 랜덤 샘플링
- 두 벡터의 inner product 및 norm 집중 부등식:
- Union bound 적용 시, 이면 양의 확률로 k-centroid shattering 구성이 존재
- → 즉
실험 결과
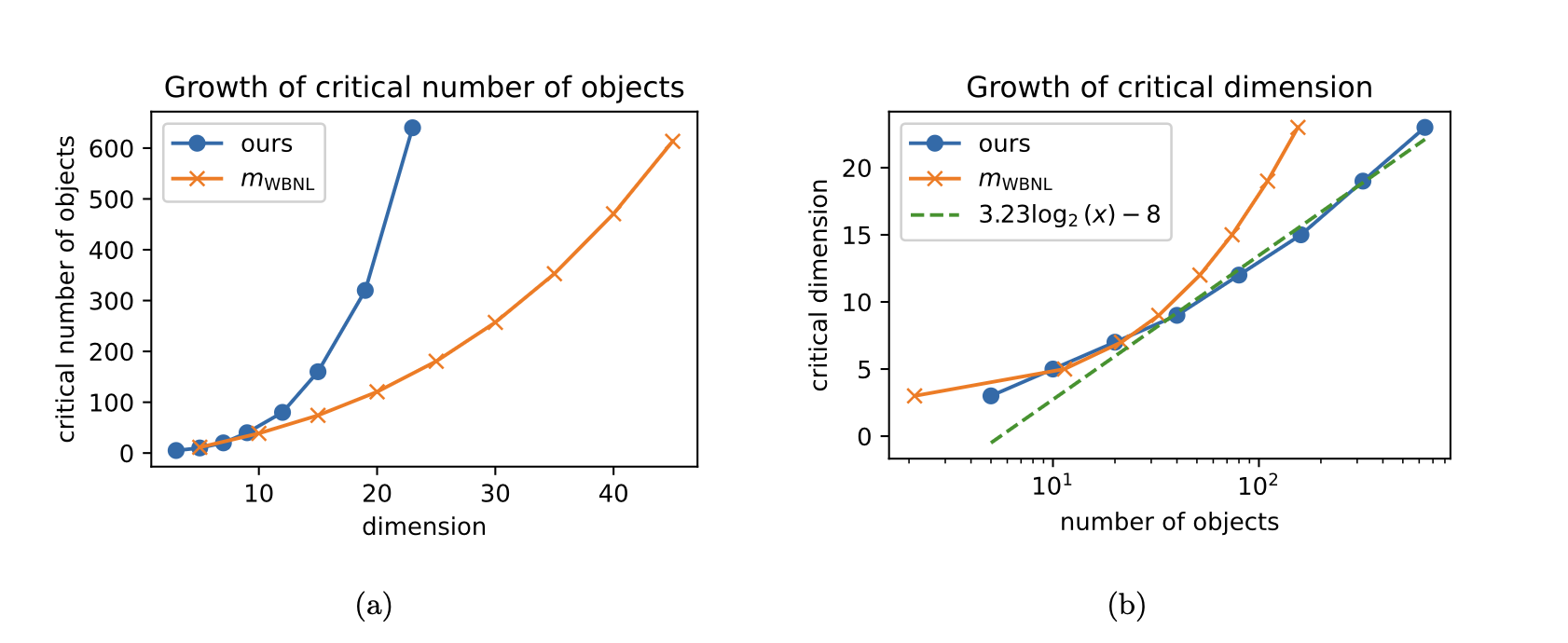
- k=2, centroid setting에서 m을 늘려가며 최소 차원을 측정
- 결과: MED-C는 log-linear 성장 (empirically )
- 기존 연구의 cubic 성장 곡선을 쉽게 초과 → 훨씬 많은 원소를 같은 차원에 수용 가능
Free Embedding Optimization vs. Centroid Setting
- 역설적으로 자유도가 더 많은 free embedding optimization이 더 나쁜 결과를 냄
- 이유: free optimization에서 개의 쿼리 임베딩을 동시에 최적화해야 하는데, 이 landscape가 훨씬 어렵다 (local optima 등 최적화 문제)
- Centroid setting은 m개만 최적화 → 더 효과적으로 좋은 구성 탐색 가능
- → 즉 기존 연구의 polynomial 성장 주장은 최적화 실패의 artifact이지, 기하학적 근본 한계가 아님
결론
- MED = Θ(k): 이론적으로 이면 m에 무관하게 모든 top-k 쿼리를 완벽히 표현 가능
- 임베딩 기반 검색의 실제 병목은 learnability: 올바른 쿼리 임베딩을 학습하는 방법
- 기하학적 공간의 근본 한계가 아님 → 더 나은 학습 알고리즘으로 개선 가능
- Future work:
- 쌍곡 공간, Wasserstein 공간 등 advanced embedding space 분석
- Answer set cardinality가 power-law를 따르는 더 현실적인 세팅
- Float32/Float4 등 fixed-point 수치 정밀도 제약 하의 분석