Why Mean Pooling Works: Quantifying Second-Order Collapse in Text Embeddings (2026)
Note
Mean pooling은 1차 통계(평균)만 보존하여 2차 통계(공분산)를 버리는 구조적 한계가 있는데, 실제로 contrastive fine-tuned 모델은 이 collapse에 강건하다는 것을 이론/실험으로 입증
- SOCM(Second-Order Collapse by Mean pooling) 메트릭 제안: 평균 SOCM이 낮을수록 MTEB 성능이 높음 (Spearman ρ = -0.678)
- Fine-tuning 후 토큰 임베딩이 텍스트 내에서 concentrate되어 2차 통계 차이(dΣ)가 자연스럽게 줄어든다는 메커니즘 규명
Background
-
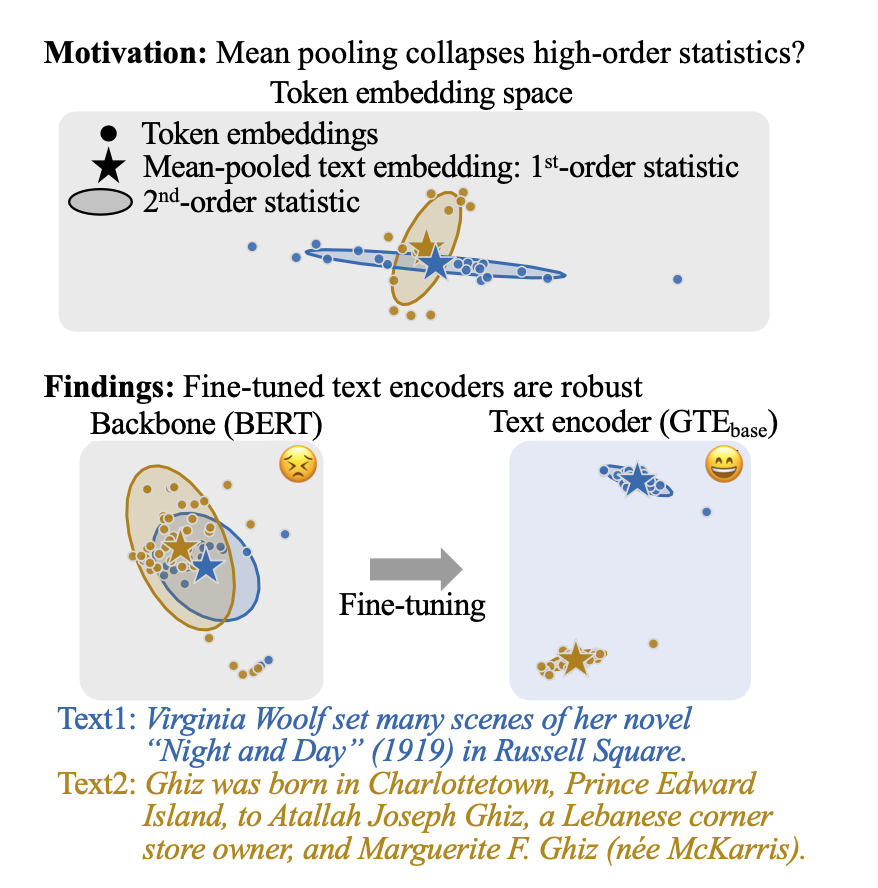
Mean pooling의 구조적 한계
- 토큰 임베딩 리스트 를 평균해 text embedding 생성
- 이 과정에서 1차 통계(평균)만 살아남고, 2차 통계(공분산 )는 버려짐
- 분포가 다른 두 텍스트가 비슷한 text embedding으로 collapse될 수 있음
- 그럼에도 실용적 관점에서 mean pooling은 계산 효율 + 경험적 성능으로 선호되어왔음 -> 왜 괜찮았던 걸까?
-
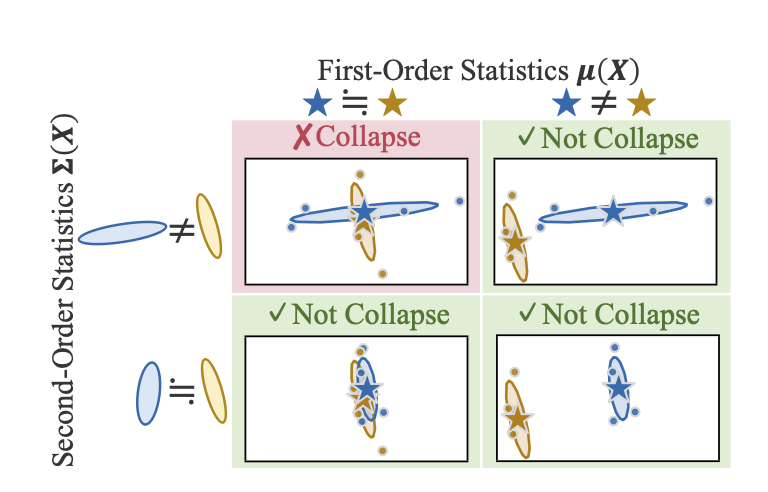
Collapse 발생 조건
- Collapse 발생: AND
- = 평균은 같은데 퍼짐이 다른 경우, mean pooling 시 구분 안 됨.
- Collapse 미발생 케이스:
- (1차 통계 자체가 다름)
- AND (둘 다 유사 → 실제로 비슷한 텍스트)
- Collapse 발생: AND
Method
SOCM (Second-Order Collapse by Mean pooling) 메트릭
- 정의:
- : 1차 통계 거리 (scaled squared Euclidean distance, )
- “mean-pool했을 때 얼마나 비슷해지는가”
- : 2차 통계 거리 (scaled Bures-Wasserstein distance, )
- “얼마나 다른 텍스트인가”
-
두 가지는 곱해지므로, 둘 다 클 때만 SOCM이 커지는 구조(즉 둘이 매우 다른 텍스트인데 평균내면 비슷해질수록)
-
Wasserstein distance 분해 기반:
- 토큰 임베딩 분포를 Gaussian 로 근사
- (L2-Wasserstein 거리의 1차+2차 분해)
- Gaussian 근사 선택 이유: 고차원 Wasserstein 계산의 tractability, FID 등 기존 사례
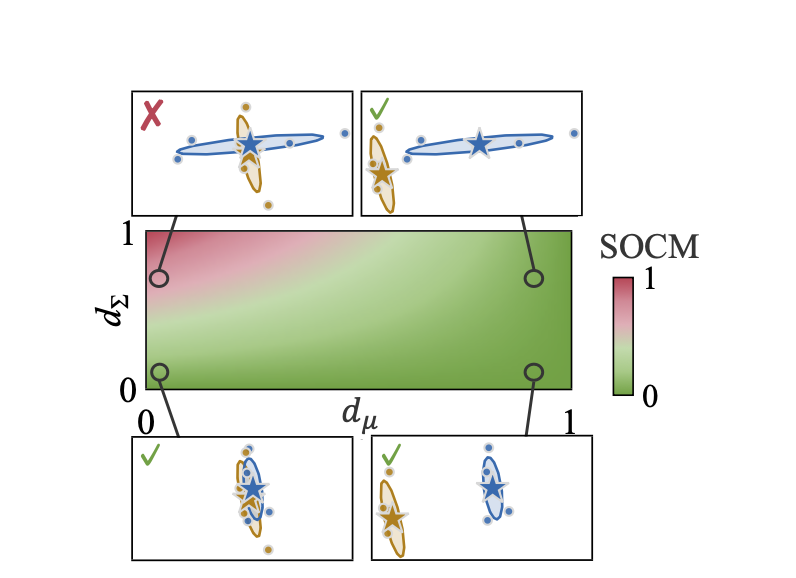
- - 2D 공간에서 SOCM 값 시각화
- 좌상단(1차 유사, 2차 상이) → SOCM 높음 / 나머지 세 코너 → SOCM 낮음 (위에서 정의된 collapse의 발생/미발생 케이스를 정확히 반영하고 있으므로 적절한 메트릭이다 라는 논리)
Concentration Theory
-
Attention은 기본적으로 각 토큰이 다른 토큰들의 정보를 가져와 평균내는 연산으로 이 자체가 토큰들을 뭉치게 하는 경향 있음
-
특히 Contrastive learning은 mean-pooled text embedding을 supervise하므로 이게 잘 작동하려면 토큰들이 mean 주변에 모여있어야(mean이 토큰들을 잘 대표해야) 하므로, 학습 과정에서 자연히 토큰들이 mean 주변으로 집중화된다는 것
- 사실 기본적으로는 contrastive learning은 negative pair끼리 멀어져야 하므로 를 늘리는 방향으로도 SOCM을 줄이기는 할 것인데, 아래 정리들은 를 줄이는 경로에 관한 것.
-
세팅: 단일 헤드 self-attention 블록 기반 simplified Transformer
- Attention 출력:
- Residual:
- Per-token transform:
- Spread 정의:
-
Theorem 1: 이면 final token embedding의 normalized spread는 (r, C → 0)
- : attention+projection의 spread 수축 지표
- : residual에서 input spread 영향 비율
- : per-token transform의 relative spread 증폭 비율
- = Attention이 토큰을 뭉치게 하고 residual이 그걸 방해하지 않으면, 최종 토큰들은 mean 주변에 집중된다.
-
Theorem 2: 이면
- 토큰이 concentrate되면 within-text 공분산 가 작아지고 → 가 작아지고 → SOCM이 작아짐
Experiments
실험 설정
- 데이터: Wikipedia 1M 문장에서 1,000개 샘플 → 499,500 쌍 생성 (추가로 MS MARCO도 검증)
- 모델: BERT/MiniLM/MPNet/nomic-bert-2048 backbone + 각각의 contrastive fine-tuned 버전
- E5base, GTEbase, Unsup-SimCSE (BERT 계열)
- E5small, GTEsmall, all-MiniLM-L12-v2 (MiniLM 계열)
- all-mpnet-base-v2 (MPNet 계열)
- nomic-embed-text-v1.5 (nomic-bert 계열)
Fine-tuned 모델의 SOCM 강건성
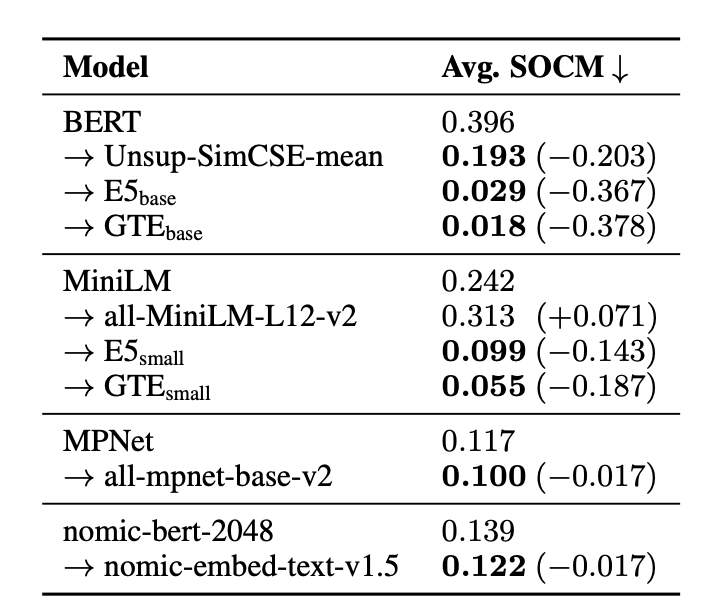
- Wikipedia 기준 평균 SOCM 비교
- Fine-tuned 모델이 backbone 대비 대부분 SOCM 크게 감소
- BERT: 0.396 → GTEbase: 0.018 (-0.378), E5base: 0.029 (-0.367)
- 예외: all-MiniLM-L12-v2는 MiniLM 대비 소폭 증가 (+0.071)
- GTEbase vs BERT 정성적 예시: BERT SOCM=0.618 vs GTEbase SOCM=0.024 (같은 텍스트 쌍)
Concentration 메커니즘 검증
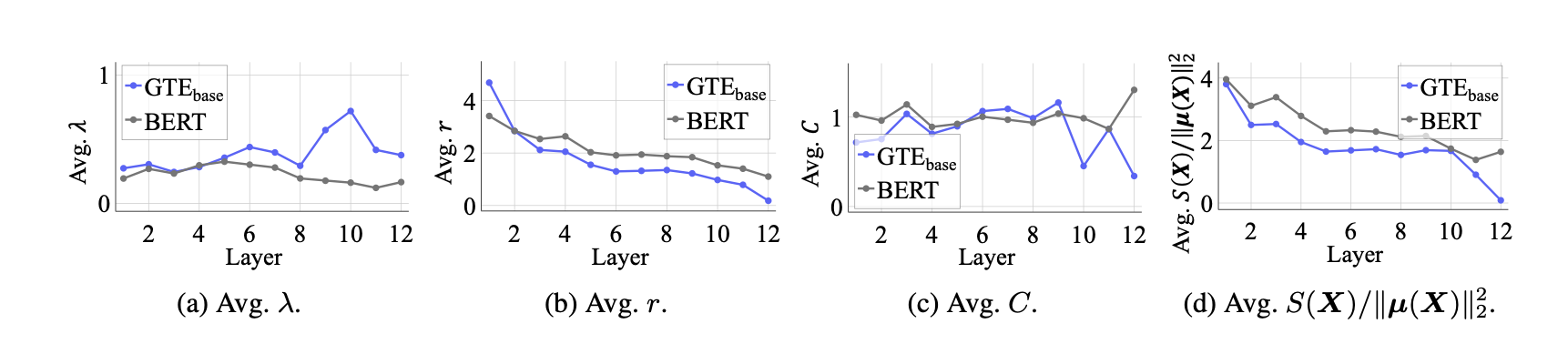
- λ (attention+projection 수축): BERT/GTEbase 모두 전 레이어에서 λ < 1 → fine-tuning 전후 모두 attention이 spread를 수축시킴
- r (residual에서 input spread 영향): GTEbase가 BERT보다 후반 레이어에서 낮음, 최종 레이어에서 0에 가까워짐
- C (per-token transform spread 증폭): 전반적 유사하나 GTEbase가 후반 레이어에서 소폭 낮음
- S(X)/||μ(X)||² (최종 concentration): GTEbase가 BERT보다 현저히 낮음, 특히 후반 레이어
- 해석: Attention은 fine-tuning 전후 모두 수축 역할 / Residual connection에서 input spread 영향이 fine-tuning 후 작아지는 것이 핵심 차이
SOCM과 Downstream 성능 상관관계
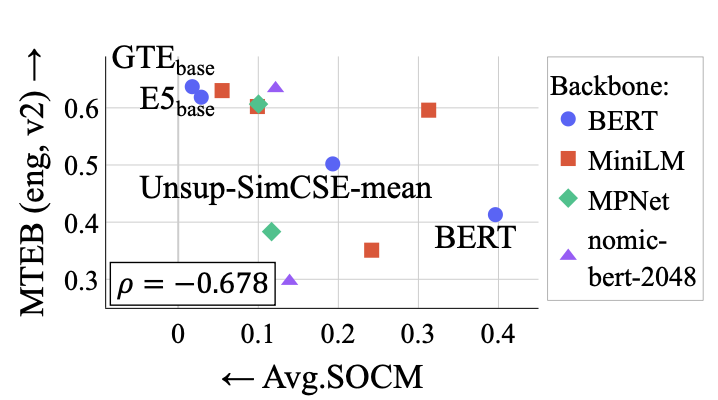
- 11개 모델에 대한 SOCM vs MTEB (eng, v2) 스코어 산점도
- Spearman ρ = -0.678 (p=0.015): SOCM 낮을수록 MTEB 높음
- S(X)/||μ(X)||² vs MTEB: ρ = -0.622 (더 낮음)
- SOCM이 더 나은 이유: inter-text separation(dμ)도 반영하기 때문 - contrastive learning이 음성 쌍 분리를 촉진하는 효과를 포착