A Semi-Personalized System for User Cold Start Recommendation on Music Streaming Apps (2021)
Note
신규 유저의 등록 당일 데이터(인구통계 + 상호작용 + 온보딩 결과)를 사용해서 임베딩을 예측하고, warm user 클러스터에 배정해 세미 개인화 추천을 제공하는 프로덕션 시스템
- 임베딩 예측을 그대로 사용한 완전 개인화 NN보다 세그먼트 기반 세미 개인화가 일관되게 더 높은 성능을 보임
Background
- Deezer 규모: 14M 활성 유저, 73M 트랙, 180개국
- User Cold Start 문제: 신규 유저는 user-item 인터랙션이 없거나 매우 적어 collaborative filtering 모델에 포함시키기 어려움
- warm user 기준: 내부적으로 정의한 충분한 인터랙션 횟수 충족 유저
- cold user: 등록 당일, 인터랙션이 적거나 없는 신규 유저
- 기존 접근법 분류
- 인구통계 메타데이터 기반 클러스터링 (age, country)
- 온보딩 인터뷰(Netflix, Spotify 방식)로 초기 선호 수집
- Bandit 알고리즘으로 cold user를 warm user 세그먼트에 배정
- 소셜 미디어 데이터 활용
- DropoutNet: dropout으로 cold start 시뮬레이션하며 학습하는 강력한 baseline
- MeLU: meta-learning 기반 유저 선호 추정, 인터랙션 누적 시 local parameter 업데이트
Method
전체 파이프라인
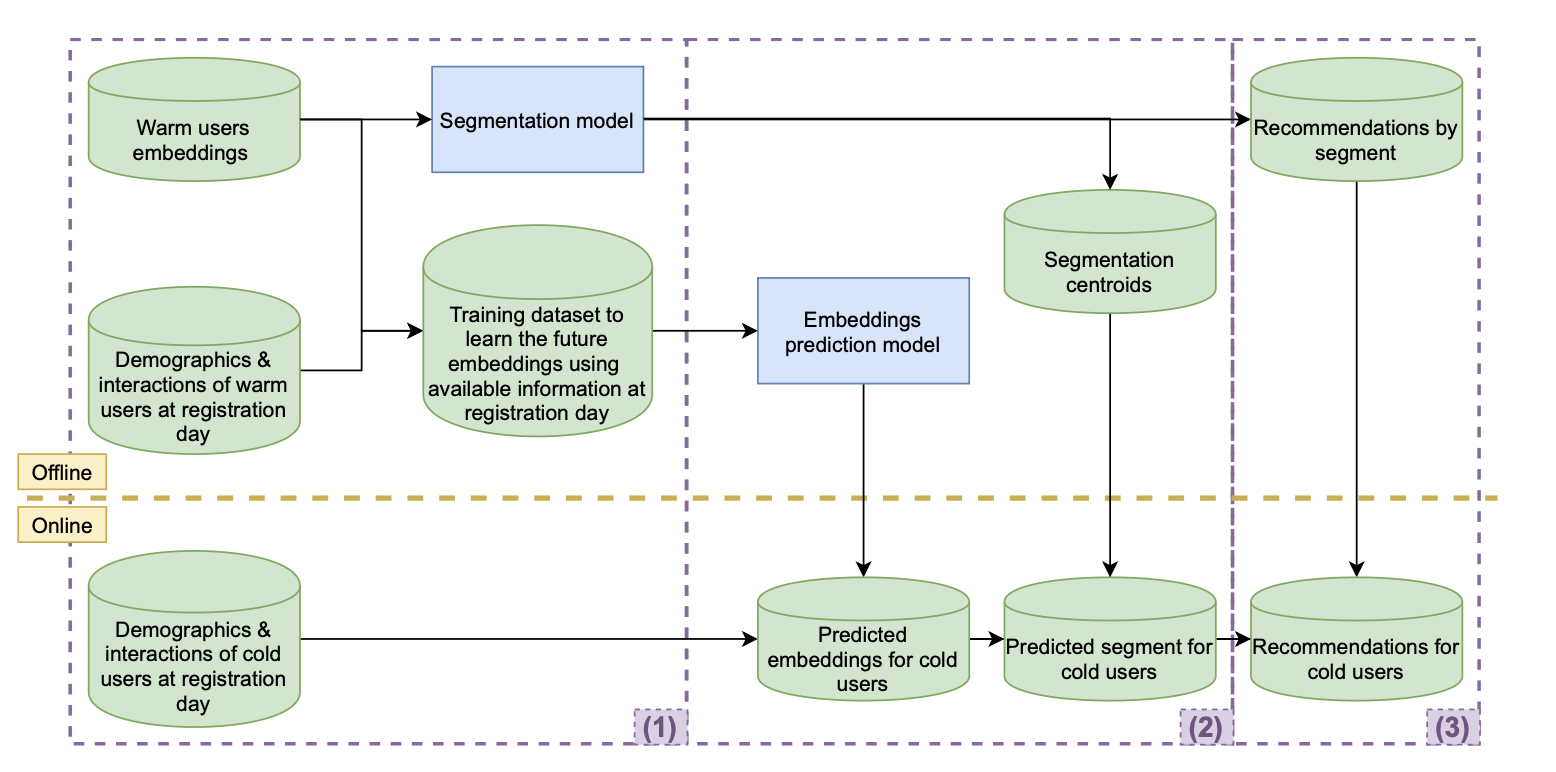
- 전체 프레임워크 요약: Offline 단계(임베딩 학습, 세그먼테이션 사전 계산)와 Online 단계(cold user 임베딩 예측 → 세그먼트 배정 → 추천)
3단계 흐름:
- warm user 임베딩 + 등록 당일 데이터로 학습 데이터셋 구성
- 딥러닝 모델로 cold user 임베딩 예측
- 예측 임베딩을 warm user 세그먼트에 배정 → 세그먼트 top items 추천
Warm User 임베딩 모델 (2종)
-
UT-ALS Embeddings = CF 기반
- user-track 인터랙션 행렬: 스트리밍 횟수, 즐겨찾기 추가 등 다양한 시그널로 affinity score 계산
- Weighted Matrix Factorization + ALS로 분해
- 임베딩 차원:
- user, item이 같은 공간에 있어 inner product로 직접 user-track 유사도 계산 가능
-
TT-SVD Embeddings = co-occurrence 기반
- track-track PMI 행렬 구성: 플레이리스트 등 다양한 컬렉션에서의 공출현 기반
- Distributed SVD로 분해, 트랙 임베딩 차원
- user 임베딩은 트랙 임베딩에서 파생됨: user = 청취 히스토리 트랙 임베딩의 평균
-
Warm User Segmentation
- UT-ALS 또는 TT-SVD 공간에서 k-means 클러스터링, 세그먼트
- 각 세그먼트 = centroid + 사전 계산된 인기 트랙 top list
- offline에서 전부 계산 (Cassandra에 저장), weekly 갱신
Cold User 임베딩 예측
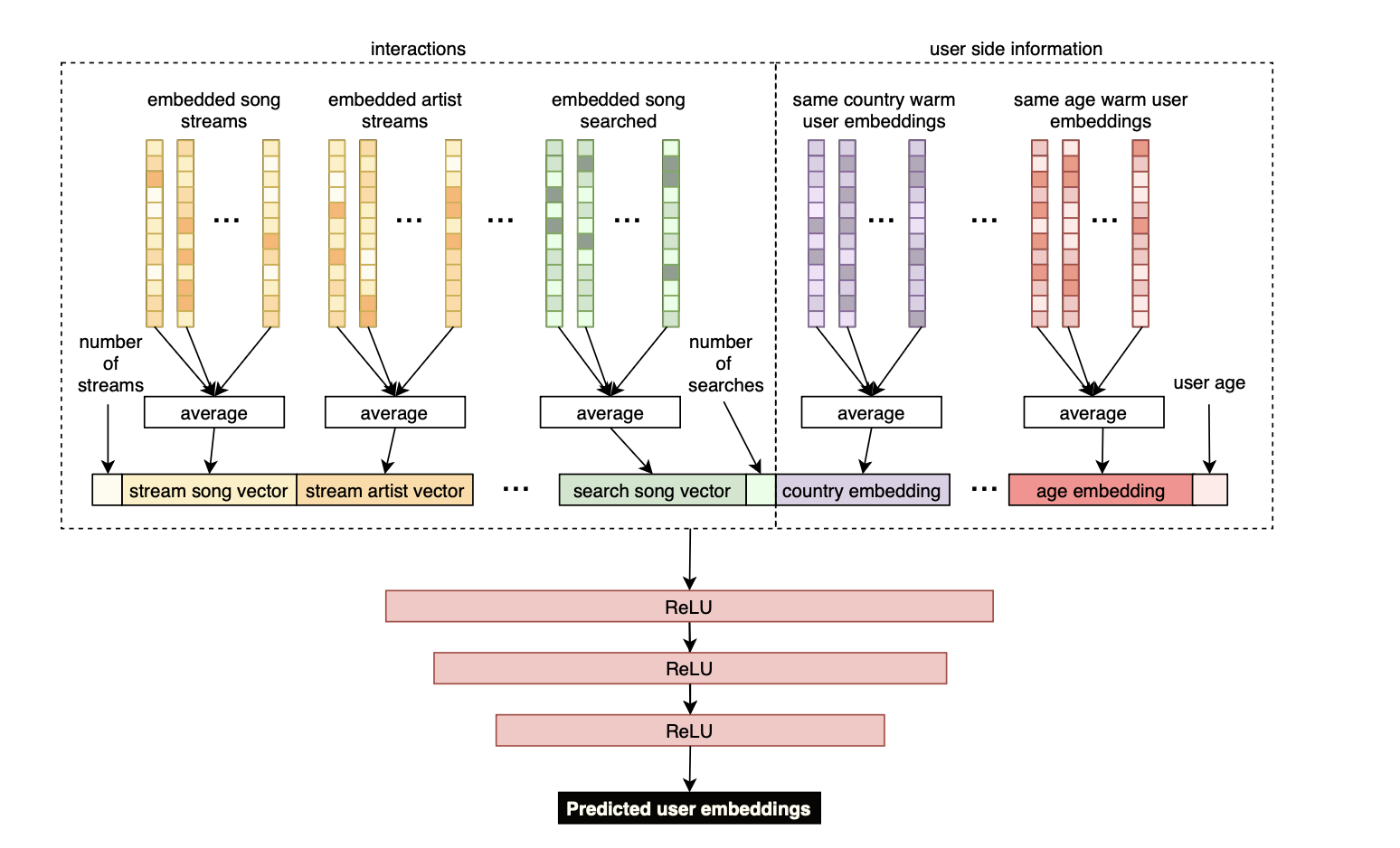
- 이종 데이터(상호작용 + 인구통계)를 통합한 임베딩 예측 딥러닝 모델 구조
Input Features
- 인구통계: age, country
- country embedding = 같은 국가 warm user 임베딩의 평균
- age embedding = 같은 연령대 warm user 임베딩의 평균
- 인터랙션 (등록 당일 한정)
- positive: stream, like / negative: skip, ban
- 트랙/앨범/아티스트/플레이리스트 수준 각각 집계
- 각 타입별로 해당 아이템 임베딩을 평균 → fixed-size 벡터
- 인터랙션 없는 경우: null vector로 대체
- 온보딩 세션: 신규 유저가 좋아하는 아티스트를 장르별로 선택 → 이것도 인터랙션 피처로 포함
모델 구조
- 입력 차원: 5139 (UT-ALS) / 2579 (TT-SVD)
- Feedforward NN: 400 → 300 → 200 → (256 or 128)
- 활성화: ReLU + Batch Normalization (출력층 제외)
- 학습: MSE loss (예측 임베딩 vs 실제 warm user 임베딩), SGD, lr=0.0001, batch=512
Semi-Personalization
- cold user를 fully-personalized(nearest neighbor)로 추천하면 데이터 희소성으로 노이즈 발생
- 대신, 예측 임베딩과 가장 가까운 warm user 세그먼트 centroid에 배정
- 해당 세그먼트의 사전 계산된 인기 트랙을 추천
배포
- 실시간 추론: Golang 웹서버, Kubernetes 클러스터
- 모델 형식: PyTorch로 학습 후 ONNX 변환, Hadoop 저장
- 트랙/아티스트/앨범 임베딩 + warm segment centroid: Cassandra 클러스터에 주 단위 갱신
- 추론 엔진: onnxruntime
Experiments
오프라인 평가
데이터셋
- warm user 70,000명 (2020년 11월 1일 기준 프로덕션 임베딩)
- cold user 30,000명 (2020년 11월 첫 주 신규 가입, 첫 달 50트랙 이상 청취)
- validation 20,000 / test 10,000
- 평가 아이템: 50,000개 익명화 트랙
- 77% cold user = 등록 당일 스트리밍 경험, 95% = 최소 1회 인터랙션, 5% = 인구통계만 존재
평가 지표: Precision@50, Recall@50, NDCG@50 (등록 당일 추천 vs 이후 30일 실제 청취 비교)
비교 모델
- Popularity baseline
- Registration Day Streams (등록 당일 스트리밍 트랙 임베딩 평균)
- Input Features Clustering (NN 없이 입력 피처 직접 k-means)
- DropoutNet (positive 인터랙션만 사용)
- MeLU
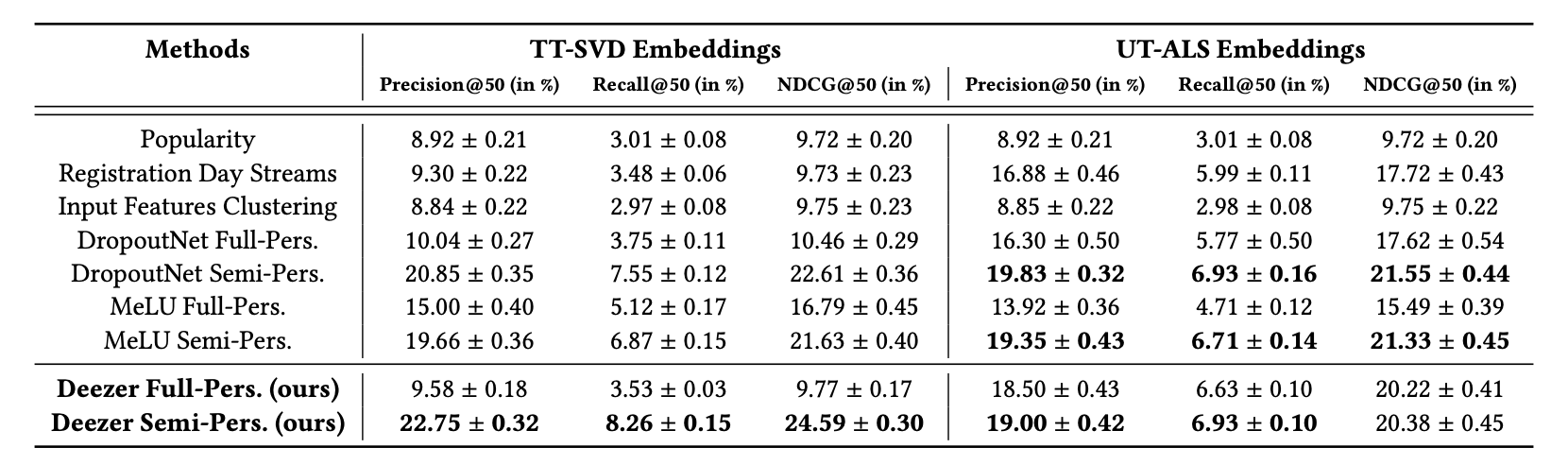
- 전체 모델 오프라인 성능 비교 (TT-SVD / UT-ALS 두 임베딩 공간)
주요 결과
- TT-SVD 기준 Deezer Semi-Pers가 Precision@50 22.75%로 전체 최고 성능
- Semi-personalized > Fully-personalized 일관되게 우월 (TT-SVD: +13.17 precision points)
- Registration Day Streams (가입 당일 들은 트랙을 평균내서 유저 임베딩으로 사용한 뒤 그걸 그대로 NN 검색)는 TT-SVD에서 Popularity 대비 거의 개선 없음 → sparse cold start의 한계 명확
- UT-ALS에서는 이 방식도 16.88%로 꽤 선방
- 가입 당일 소비는 인터랙션이 매우 적어 sparse하므로 특히 TT-SVD처럼 아이템 co-occur 기반 임베딩으로는 신뢰할 수 있는 유저 표현을 만들지 못함
- Input Features Clustering (신경망 없이 입력 피쳐 벡터 그대로 클러스터링) 도 Popularity 대비 큰 개선 없음 → 모델링 단계의 유효성 확인
- warm user 임베딩 공간으로 변환해줘야 한다는 건 당연한 듯
- UT-ALS에서는 fully-personalized 방법들이 TT-SVD 대비 더 강함
- user-item 행렬 기반이라 nearest neighbor 검색에 적합한 임베딩 구조이기 때문
- 그러면 CF 임베딩 쓸 거면 semi-pers는 필요없냐? -> UT-ALS에서 semi pers가 (19%) full-pers (18.5%)보다 근소하게 높긴 함.
- 가입 당일 인터랙션이 매우 적은 유저들에 대해서는 full-pers로 하면 임베딩 무관하게 성능이 불안정하기 때문일듯?(세그먼트 나눠서 봤으면 좋았을 텐데)
- 서빙관점에서도 semi pers가 유리하니 결국 UT-ALS 쓰더라도 semi pers가 나쁘진 않다는 결론이 됨 +그외에
- 클러스터링 세그먼트 1,000개는 어떤 기준으로 했는지 + ablation이 있었으면 더 좋았을 것
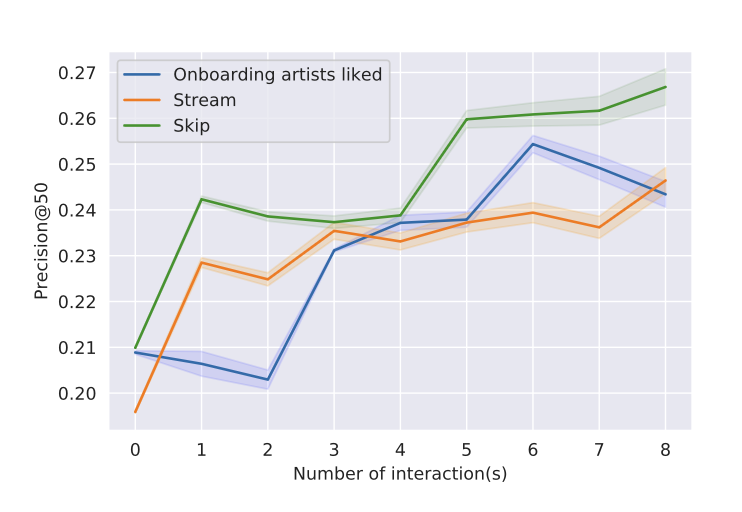
- 온보딩 아티스트 likes 수, 스트림 수, 스킵 수에 따른 Precision@50 변화
- 인터랙션이 많을수록 성능 향상, 온보딩 아티스트 3개 이상 시 유의미한 개선
- 인터랙션 전무 유저(5%): 평균 대비 5.01 points 낮은 17.74%
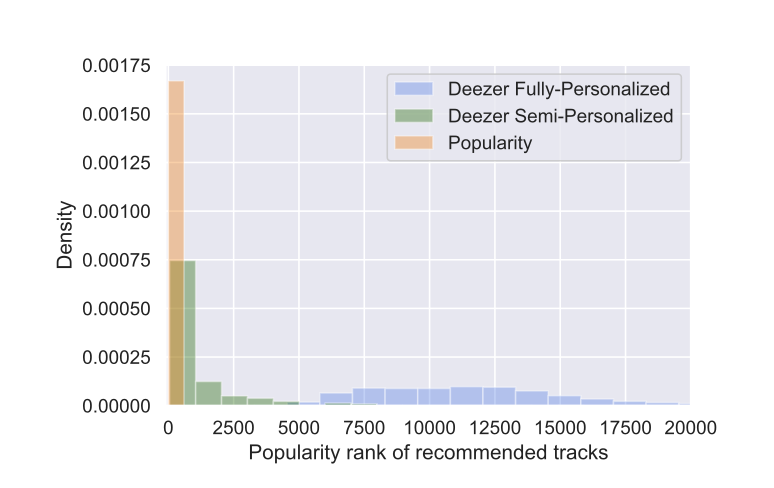
- cold user에게 추천된 트랙의 인기 순위 분포
- Semi-Pers: 상위 5,000위 트랙 중심 추천 (popularity bias 존재하나 popularity baseline과는 차별화)
- Fully-Pers: 더 롱테일 추천 가능하나 노이즈 증가
온라인 A/B 테스트
- 2020년 한 달간 신규 cold user 대상 실시
- 온라인 추천 단위: 플레이리스트 카루젤 12개 (트랙 직접 추천 아님)
- 플레이리스트 임베딩 = 포함 트랙들의 TT-SVD 임베딩 평균 + 내부 휴리스틱
- 기준선: Deezer Default (국가 + 내부 휴리스틱 기반 cold user 임베딩 추정)
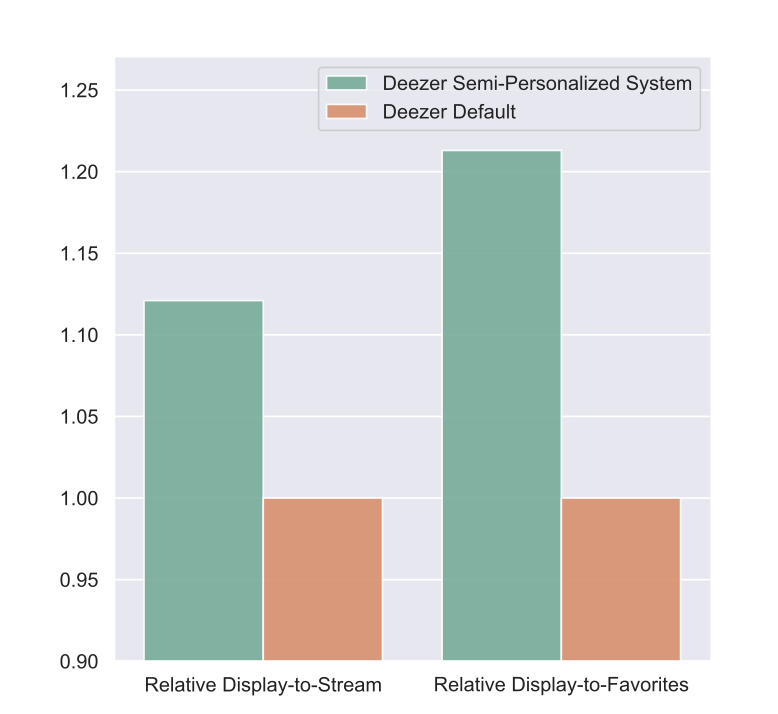
- 상대적 display-to-stream, display-to-favorites 지표 비교
- Semi-Pers가 두 지표 모두 기존 대비 유의미하게 향상 (p < 0.01)