Warmer for Less: A Cost-Efficient Strategy for Cold-Start Recommendations at Pinterest (2025)
Note
Pinterest Related Pins cold-start 아이템 추천 개선을 위한 3가지 경량 기법 제안
- 파라미터 +5% 이내로 fresh Pin 참여도 ~10% 향상
- cold-start 문제를 feature underfit / score bias / label scarcity로 분리해 각각 독립 기법으로 해결함
- 세 기법 모두 plug-and-play. 기존 아키텍처 수정 없이 적용 가능
Background
- Pinterest: 5.7억 유저, 매주 15억 Pin 저장
- Ranking model은 historical user engagement 데이터로 학습 → warm(인기) 아이템에 편향
- CS 아이템 = 학습 데이터에 드물게 등장하는 신규 아이템 (여기서는 생성 후 28일 이내)
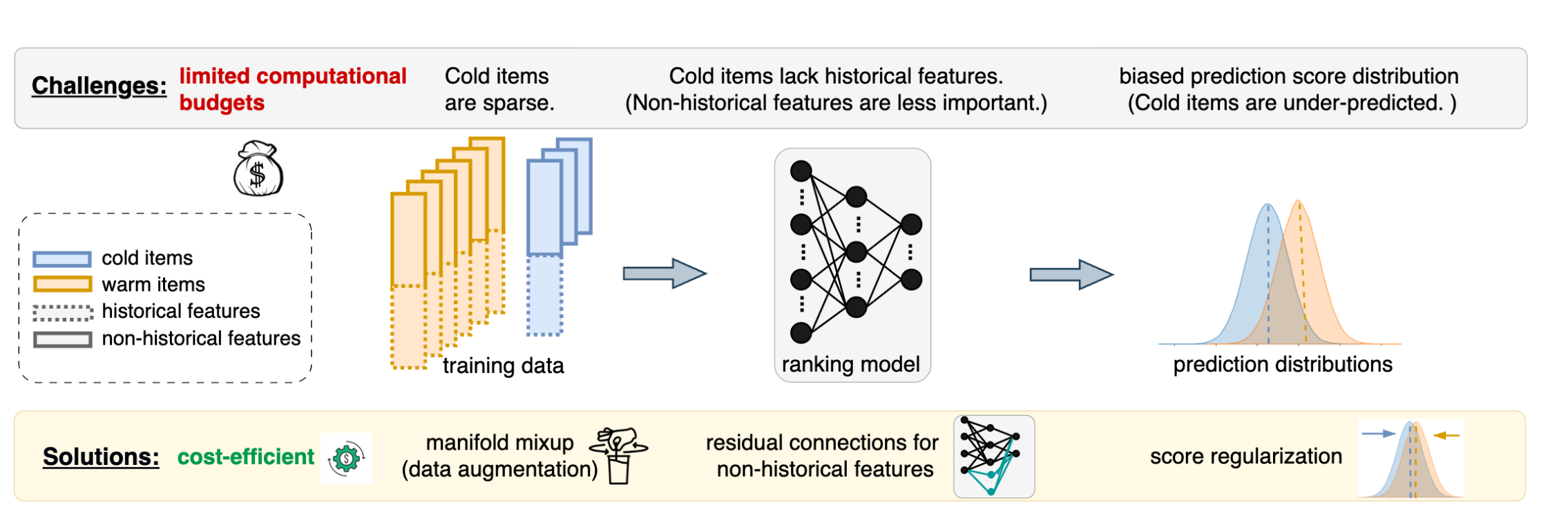
핵심 어려움:
- 컴퓨팅 제약: CS 아이템은 소수이므로, 개선 비용이 낮아야 함
- historical feature 부재: CS 아이템은 non-historical(content/attribute) feature만 존재하는데, 모델이 이를 덜 중요하게 학습함
- 예측 점수 편향: CS positive 아이템의 점수가 non-CS 대비 8-14% 낮게 예측됨
- 레이블 희소성: CS 아이템이 노출 자체가 적어 학습 신호도 부족
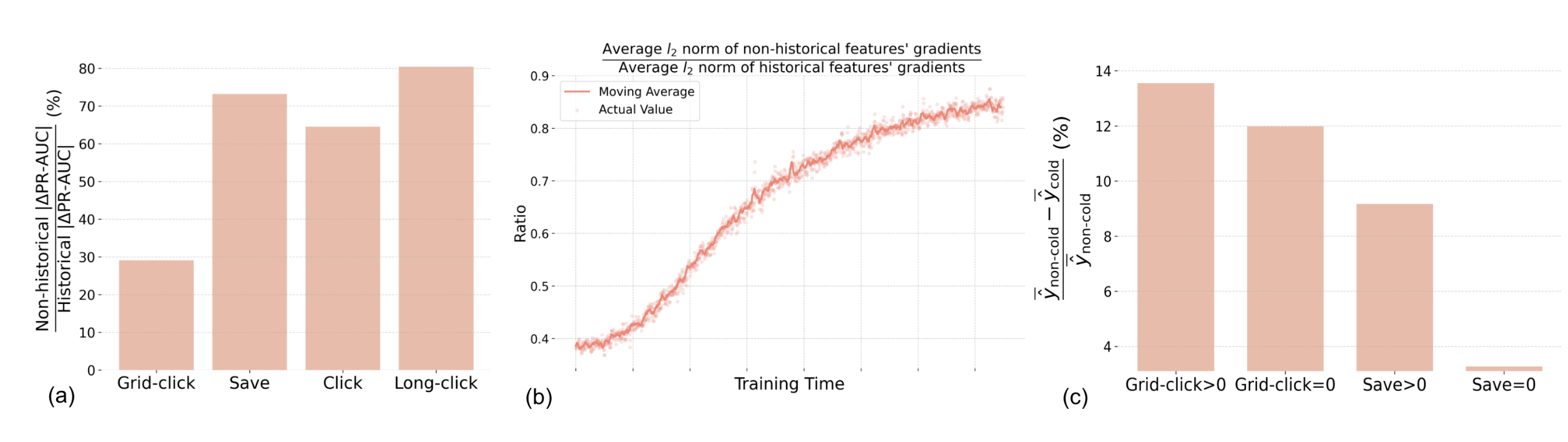
- (a) historical vs. non-historical feature를 제거했을 때 ΔPR-AUC 비율 → historical 기여가 압도적으로 큼
- (b) 학습 중 non-historical / historical gradient ℓ2-norm 비율이 1 미만 → 모델 업데이트가 historical signal에 지배됨
- (c) warm vs. cold 예측 점수 분포 비교 → cold positive 아이템이 일관적으로 낮게 예측됨
Method
아키텍처 개요
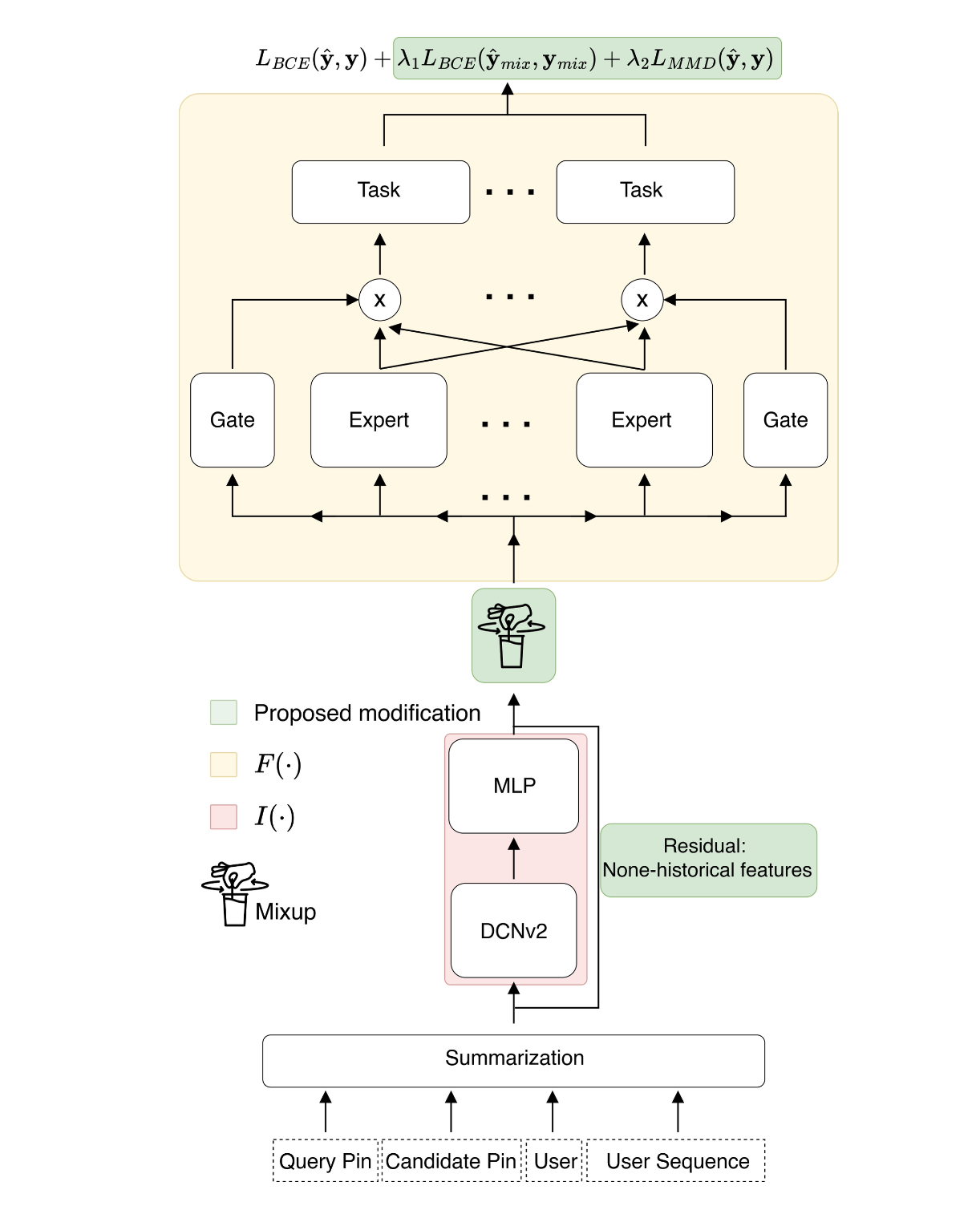
- 입력: Query Pin features, Candidate Pin features, User features, Transformer-based user sequence embedding
- Summarization module → feature crossing 학습
- DCNv2 → high-order feature interaction 학습
- MLP → 차원 축소 후 단일 임베딩으로 통합
- MMoE → multi-task(grid-click, save, click) 예측 헤드
기본 forward pass:
최종 랭킹 점수:
- : 비즈니스 목적에 따른 task별 utility weight vector
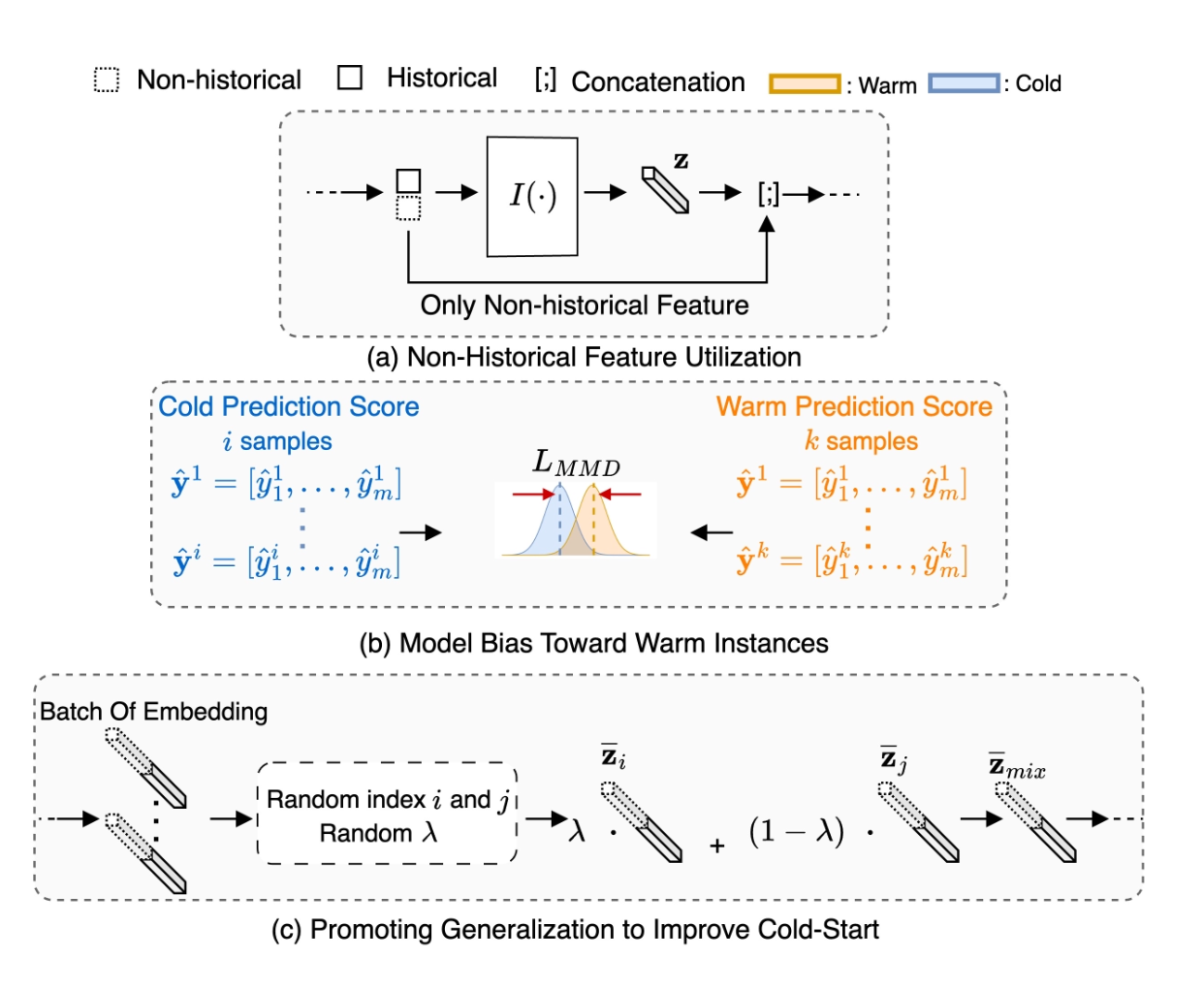
1. Residual Connection for Non-Historical Features
- 왜: gradient 분석 결과 non-historical feature 업데이트가 historical에 비해 일관되게 작음. extra embedding tower로 해결하는 기존 방법(ALDI 등)은 파라미터 28% 이상 증가.
- 방법: non-historical feature를 interaction module을 건너뛰어 prediction module F에 직접 연결하는 residual path 추가.
- 파라미터 증가: < 5% (non-historical feature 차원 축소용 MLP 레이어 하나 추가)
- auxiliary prediction head나 복잡한 hyperparameter tuning 불필요
2. Score Regularization (ScoreReg) via MMD
- 왜: 모델이 warm 아이템에 높은 점수를 부여하도록 편향됨. post-processing이나 sample re-weighting은 추가 데이터나 전체 성능 희생이 필요.
- 방법: warm/cold 예측 점수 분포 간 Maximum Mean Discrepancy(MMD)를 penalty로 추가.
- 추가 파라미터 없음, serving cost/latency 변화 없음
- 특정 sampling 기법 불필요 (mini-batch 내 warm/cold를 그대로 사용)
3. Manifold Mixup
- 왜: CS 아이템이 warm 아이템과 다른 분포를 따른다는 domain generalization 관점으로 접근. 데이터 증강 설계는 비용이 크고 trade-off가 있음.
- 방법: interaction module 출력 embedding에 linear interpolation을 적용해 새로운 학습 인스턴스 생성.
- 는 mini-batch에서 무작위 선택 (warm-cold 강제 mixing 안 함 → cold 부족으로 diversity 저하 방지)
- 원본 샘플 + mixed 샘플을 함께 학습 (mixed만 사용 시 성능 저하)
4. 전체 학습 목표
- , (경험적 튜닝)
- 학습 데이터: 27일, 1 epoch
효과
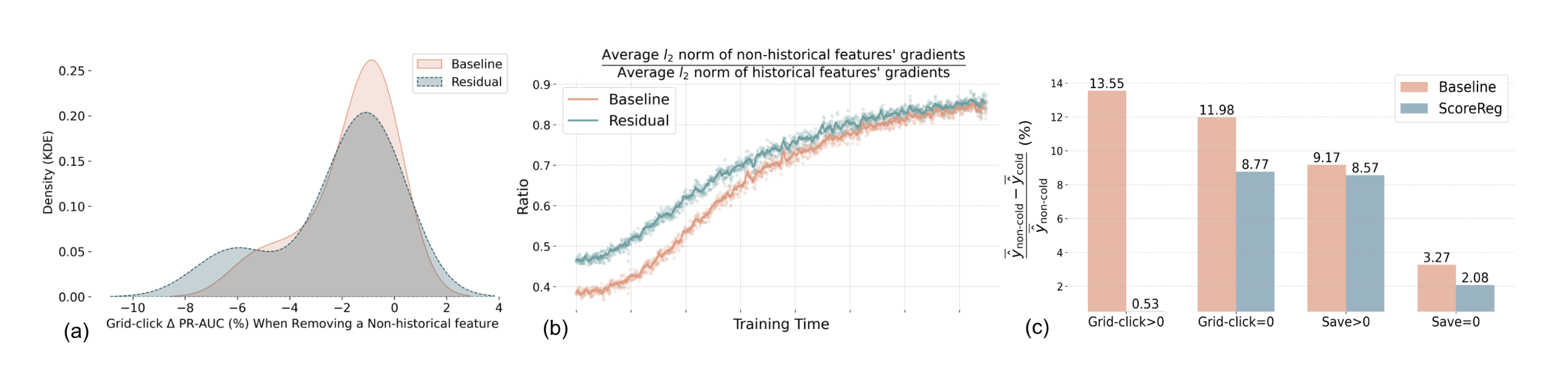
- (a),(b) Residual Connection for Non-Historical Features
- non-historical feature 제거 시 ΔPR-AUC 분포가 왼쪽으로 이동 → feature importance 증가
- 학습 중 non-historical gradient 비율이 일관되게 증가
- (c) Score Regularization
- positive grid-click 예측 갭: 13.65% → 0.53%
- positive/negative 모두에서 편향 완화
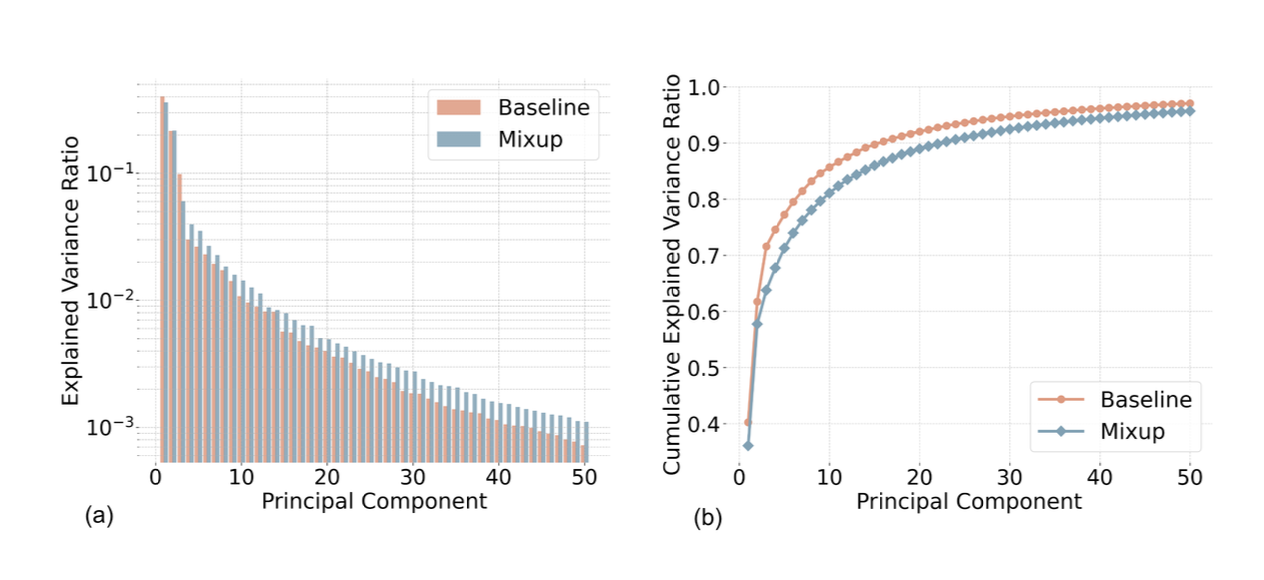
- PCA 분석: mixup 모델의 feature space가 더 high-rank → 더 분산된 표현, dominant item에 대한 암기를 억제함
- low-rank feature space에서는 trivial pattern을 암기해서 generalization을 방해한다는 기존 연구와 일치
- 하위 ranked Pins에서 효과 집중 → position bias 완화
Experiments
Online
fresh Pins (<28일내) 참여도:
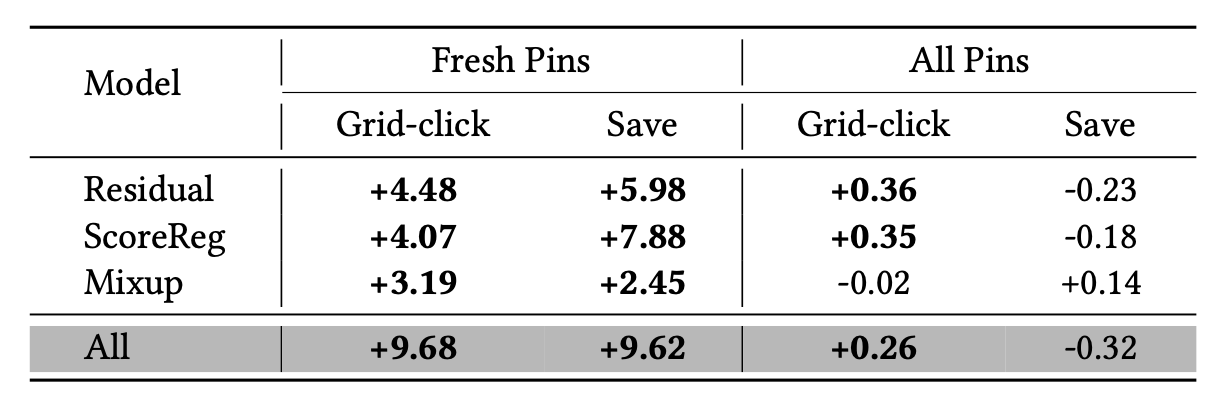
cold-start users:
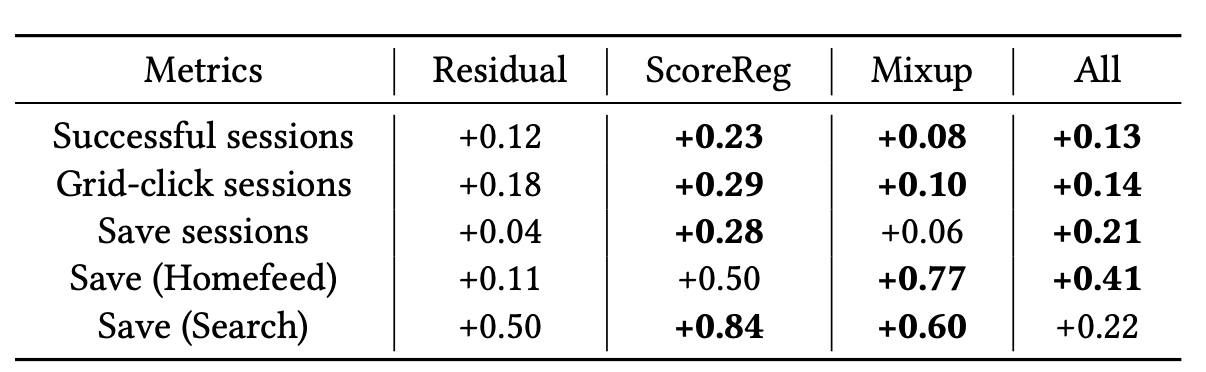
- Homefeed/Search save도 개선 → CS 유저의 활성화가 user sequence를 풍부하게 하는 positive feedback loop