about
음악 소비 시 반복 청취 성향을 Sequential Recommendation에 이용한 논문 2개 / 둘다 RecSys’24 / 음악은 원래 꽂히면 무한반복재생이지!
Enhancing Sequential Music Recommendation with Personalized Popularity Awareness (2024)
💻 code: https://github.com/sisinflab/personalized-popularity-awareness
-
Transformer 기반 sequential recommendation 모델들(BERT4Rec, SASRec)은 음악 소비의 동적인 특성과 사용자들의 반복적인 음악 청취 습관 을 효과적으로 포착하는 데 어려움을 겪음
- 반복적으로 듣는 패턴을 여기서는 personalized popularity라고 표현
-
이 연구는 유저-아이템 인기 점수를 모델의 생성 점수와 결합해서 학습 시 인기 분포로부터의 편차를 학습하도록 함
- Softmax 함수를 사용하는 모델(BERT4Rec) : 개인화된 인기 점수를 모델의 점수에 합산
- Sigmoid 함수를 사용하는 모델(SASRec, gSASRec) : 개인화된 인기 점수를 모델의 점수 행렬에 합산하되, 미래 데이터로부터의 시간적 누출을 방지 (BERT와 달리 단방향이므로)
개인화된 인기도 (PPS)
- c는 그냥 이 유저가 그 아이템을 얼마나 들었는지 count여서 사실 개념적으로 인기도는 c_j / sum(c) 여야 하지만 수치적 안정성을 위해 max(C)가 들어가고 으로 smoothing한 것임
- 0.01을 사용했는데, 이 가 작을수록 원래의 인기도에 더 가까워져서 인기도의 영향이 커지고, 가 커질수록 (실제 pp랑 상관 없이 아이템이 선택될 확률이 균등해져) 인기도의 영향이 없어짐
Softmax 사용시,
모델이 생산하는 점수는
PPS는
softmax 함수의 형태에 맞춰 Personalized Popularity 확률을 재구성하기 위한 변형 중간 단계라고 생각하면 됨..
결론적으로 위 점수가 각 에 대한 PPS 점수라고 할 수 있고 이를 모델이 생성하는 점수에 더해서 최종 예측 확률이 나오게 됨!
Sigmoid 사용시,
모델이 생산하는 점수는
비슷하게 계산하면
이 통합된 점수를 다음과 같이 최종 예측 확률에 사용
Result
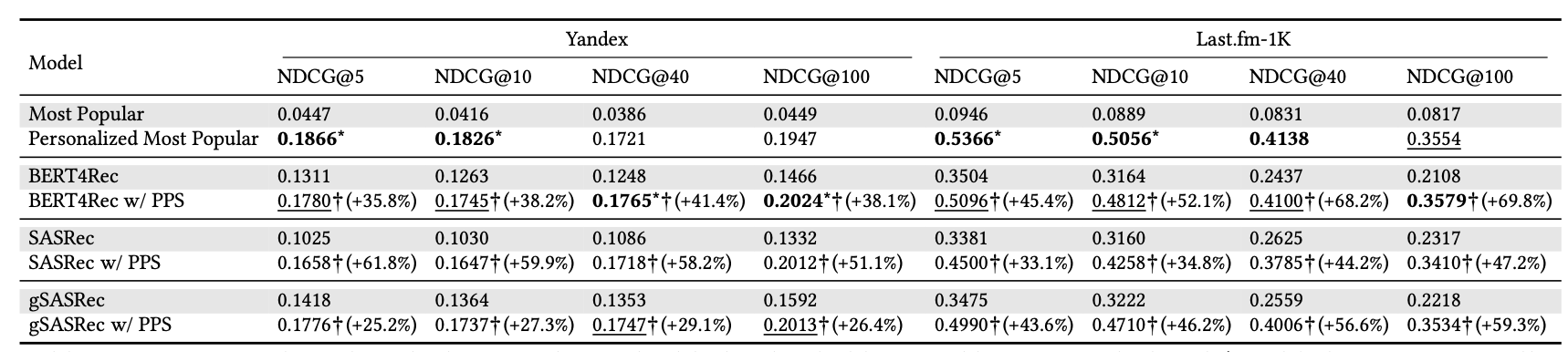
- Most Popular
- 개인화가 아닌 전체 유저의 인기도를 바탕으로 추천하는 것
- Personalized Most Popular → 대부분 Best Result
- 사용자별 인기도를 기반으로 아이템을 추천하는 것 = 자주 사용되는 베이스라인이며 반복성이 높은 도메인에서는 sota 모델급의 성능을 보여주기도 함
- (대충 생각해 봐도 정확도 성능에서만 보면 100%의 exploitation으로 좋은 결과를 낼 것 같음. 다만 실상황에서 / 장기적인 관점에서 선호되는 전략은 아니어서 그렇지)
- Sequential Recommendation(BERT4Rec, SASRec, gSASRec) + Personalized Popularity Score
-
PPS를 사용하지 않은 모델보다 25%~70% 사이의 성능 향상 (괄호 안 표기)
-
일부 지표에서는 best result
-
➡️ sequential recommendation에서 이런 개인화된 인기를 반영하는 것이 효과적이다!
-
Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation (2024)
💻 code: https://github.com/deezer/recsys24-pisa (tensorflow implementation + Deezer dataset)
- 문제제기는 위랑 똑같음
- PISA (Psychology-Informed Session embedding using ACT-R)
- ACT-R (Adaptive Control of Thought—Rational)이라는 인지 아키텍처 → 여기서 처음 쓰인 건 아니고 이전에도 반복 행동을 모델링하기 위해 쓰였음
- 이걸 Transformer(sequential recommendation)이랑 결합했다는 게 이 연구의 기여점
![]()
- Next Item이 아닌 Next Basket(함께 소비되는 item의 set) Recommendation
- 음악 도메인에서는 한번 듣는 session을 basket으로 생각할 수 있음
- CoSeRNN 등
- 이전 연구들은…
- basket representation은 주로 average pooling 사용해서 반복 패턴 정보가 손실되는 경향이 있었음
- 재청취가 빈번한 음악 도메인에서 basket recommendation 시 반복 행동을 무시한다는 것은 한계
- 이전에 ACT-R을 사용한 연구들은 협업 필터링 모델을 주로 사용해서 시퀀스를 통한 dynamic dimension을 포착하지 못함
Architecture
![]()
ACT-R 프레임워크 + Session Embedding
3가지 구성요소
-
Base-level (BL) 컴포넌트 : 특정 노래 를 사용자가 얼마나 자주, 그리고 최근에 들었는지 반영하여 기억 활성화를 모델링
- : 참조 시간
- : 사용자가 번째로 노래를 들은 시간
- : time decay parameter
-
Spreading (SPR) 컴포넌트 : 동일한 세션 내에서 노래들이 함께 나타나는 빈도(공동 발생 패턴)
- 는 노래의 co-occurence matrix 의 정규화된 상관 행렬
-
Partial Matching (P) 컴포넌트 : 노래 임베딩 벡터의 내적을 통해 계산되는 음악적 유사성 (SPR과 보완적인 정보를 제공)
최종적으로 세션 임베딩은 각 곡 임베딩의 가중합으로 계산되고,
가중치는 각 컴포넌트의 선형조합으로 계산됨. 이때 3종류의 가중치는 learnable global parameter
User Embedding
각 사용자는 장기 선호도와 단기 선호도의 조합으로 표현
장기 선호도: 사용자의 과거 청취 기록에서 BL값이 가장 높은 상위 20개 노래의 임베딩 벡터의 가중평균
단기 선호도: Transformer 아키텍쳐 사용
- 각 세션 임베딩 에 학습 가능한 위치 임베딩 을 더한 입력 행렬 이 개의 스택된 Self-Attention Block (SAB)을 통과하며, 최종 블록의 마지막 위치 출력 이 가 됨
- 이 과정에 세션 임베딩에 ACT-R 구성 요소가 반영되어 단기 선호도에 영향을 미침
Training
- 데이터 준비
- 주어진 훈련 세트 에 있는 각 사용자의 전체 청취 세션 시퀀스 사용
- 이 시퀀스로부터 첫 개 세션만 포함하는 부분 시퀀스를 생성
- 은 모델이 예측해야 할 “정답” 세션이 되고, 은 무작위로 샘플된 “부정” 세션이 됨(부정 세션은 사용자가 실제로 듣지 않은 곡들로 구성)
- 주어진 훈련 세트 에 있는 각 사용자의 전체 청취 세션 시퀀스 사용
- 손실 함수
- 는 하이퍼파라미터
- 첫번째 항: BPR Loss
- 사용자의 임베딩 벡터()와 정답 곡()의 임베딩 벡터 내적 값이 부정 샘플 곡()의 임베딩 벡터 내적 값보다 높아지도록 하는 것
- 두번째 항: session-level loss
- 번째 세션까지 처리한 사용자 임베딩 벡터가 그 다음 정답 세션의 임베딩 벡터와 높은 내적 값을 갖도록 하는 것
- 첫번째 항: BPR Loss
Result
![]()
- PISA는 12개의 NDCG 및 Recall 지표 중 10개에서 가장 높은 점수를 달성
- repeat-aware 모델들이 대부분의 정확도 지표에서 Non-repeat-aware 모델들을 능가
- PISA-U와 PISA-P는 반복되는 곡들을 효과적으로 예측할 뿐만 아니라, 사용자가 아직 듣지 않은 새로운 곡들을 추천하는 데 있어서도 베이스라인을 크게 능가
- 단순히 반복 패턴을 포착할 뿐만 아니라 사용자의 음악적 취향을 효과적으로 나타내는 곡에 집중하게 하여 탐색 능력을 향상시키는 것
- PISA-U와 PISA-P는 Negative sampling 을 uniform하게 하느냐 popularity에 따라 확률을 다르게 하느냐에 차이인데 popularity-based negative sampling을 사용했을 때 PISA의 효과성, 탐색 능력, 그리고 인기도 편향 감소가 개선됨