Modeling Users According to Their Slow and Fast-Moving Interests (2022)
배경
- 대부분의 음악 스트리밍 유저는 장기적인 취향과 일시적 변화/상황적 맥락의 영향을 동시에 받음
- Slow Features : 특정 장르, 아티스트, 혹은 스타일에 대한 장기적이고 지속적인 선호도
- Fast Features: 순간적인 관심과 맥락, 특정한 시간/기분/외부 환경에 의해 단기적으로 변화하는 소비 패턴
- FS-VAE : 이를 고려한 유저 모델링 방식을 소개 (Spotify)

구조
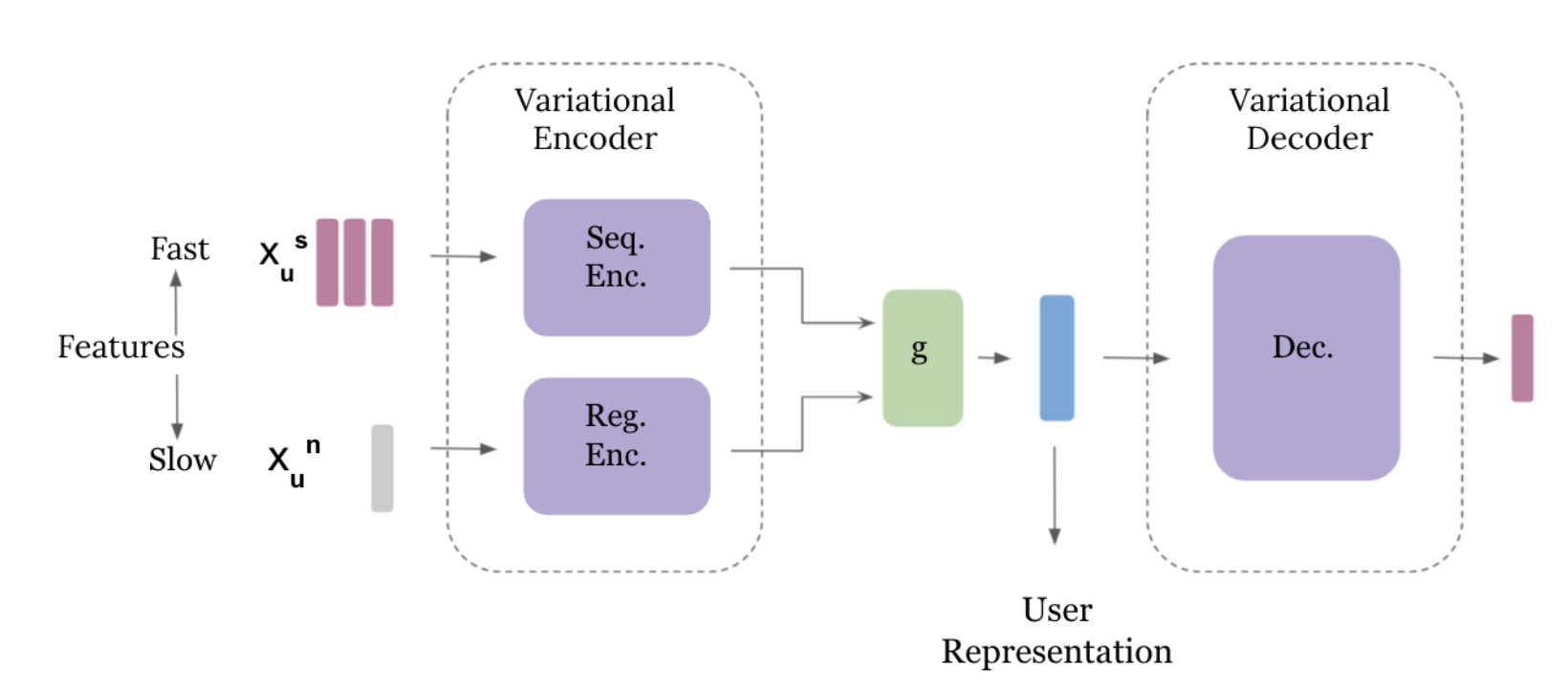
- 2가지 입력 데이터 사용
- Slow Features
- 사용자의 일반적인 음악 선호도를 반영하는 장기적인 특성 (Non-Sequential한 입력)
- 특정 시점에서 변하지 않는 누적된 청취 기록을 포함
- 예) 총 청취 횟수, 좋아요 누른 횟수, 스킵한 곡 수, 다시 들은 곡 수, 재생목록에 추가한 곡 수, 시간대별 청취 패턴 등
- Fast Features
- 사용자의 최근 행동 및 순간적인 관심을 반영하는 특성 (Sequential한 입력)
- 최근 들은 곡들의 시퀀스(그 곡들의 특징 벡터)
- 사용자의 최근 행동 및 순간적인 관심을 반영하는 특성 (Sequential한 입력)
- Slow Features
- 전체적인 구조는 일반적인 Variational Autoencoder 인코더 + 디코더
- Slow Features와 Fast Features를 각각 두 개의 다른 인코더로 나눠서 처리하고 그 두 개의 인코더에서 얻은 latent vector를 결합(concat)해서 최종적인 유저 representation을 얻음
- 디코더는 MLP 층으로 인코더가 얻은 임베딩을 사용하여 사용자가 다음에 들을 곡을 예측
- 일반 VAE랑 다른 점
- 손실함수에 라는 하이퍼파라미터를 넣어 KL Divergence의 가중치를 조절
(KLD term은 잠재 변수 z의 분포와 변분 추론으로 가정한 정규분포의 차이가 적도록 하는 regularization term이므로, 이 를 기본 VAE처럼 1로 하지 않고 0.5 정도의 낮은 값으로 설정하게 되면 모델이 더 약한 제약으로 (자유롭게) 잠재 표현을 학습할 수 있게 되어 새로운 취향을 학습할 확률이 높아짐)
평가
- 약 15만 명의 사용자의 28일 간의 청취 기록을 사용해서 학습과 실험을 진행
- 유저 임베딩에 집중하기 위해서 곡에 대한 임베딩 벡터는 이미 만들어진 벡터를 사용 (같은 플레이리스트에 얼마나 등장하느냐에 따라서 임베딩이 학습되도록)
- 과제: next item prediction (각 사용자의 임베딩 기반으로 다음에 들을 곡을 예측)
- 지표: 예측된 곡과 실제 사용자가 들은 곡의 임베딩 간의 거리(L2 Distance, Cosine Distance)
- ablation
- Fast Features를 뺐을 때 / Fast Features의 시퀀스를 랜덤으로 섞었을 때 / Slow Features를 뺐을 때 / 변분추론(probablistic model)을 쓰지 않았을 때 (즉, 일반적인 오토인코더를 사용했을 때)
- 모두 유의하게 제안된 모델보다 낮은 성능이 확인되었지만, 가장 영향이 큰 건 Fast Features를 뺐을 때였음 (과제가 next item prediction이라서 더 그럴 듯)