Self-Attentive Sequential Recommendation (2018)
Intro
- 이전의 sequential modeling
- MC(Markov Chain) : Sparse한 데이터에서 잘 작동
- RNN → Dense한 데이터
- SASRec: Transformer Encoder → Next Item Prediction
- self attention을 통해 데이터셋의 sparsity와 무관하게 (long term preference에 집중할 것인지 아니면 최근 패턴에 집중할 것인지 알아서!) 모두 잘 작동하는 sequntial recommendation이 가능
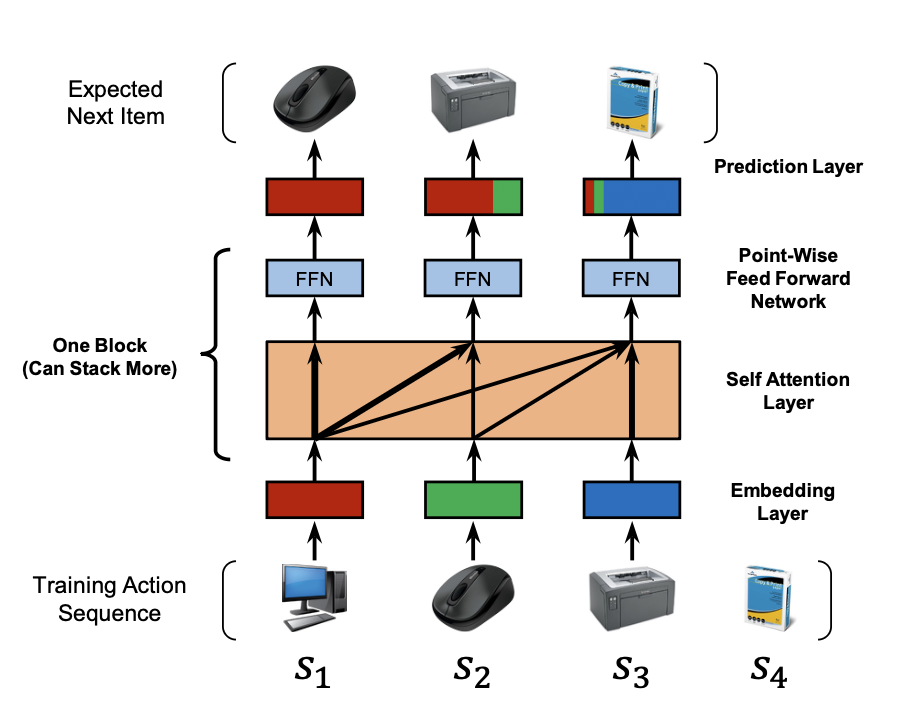
- User action sequence가 존재할 때 이를 하나씩 shifting하여 next item sequence를 만들어 모델이 이를 맞히도록 학습
Architecture
Embedding Layer
- 고정된 길이의 시퀀스로 padding 또는 crop
- position embedding은 learnable (고정하는 것보다 좋은 성능)
- leak 방지를 위해서 attention score를 계산할 때 query 아이템보다 뒷 순서에 있는 key 아이템과의 계산은 금지 (상삼각 마스킹)
- attention 후 일반적인 Transformer구조처럼 point-wise feed forward network가 붙어있음 (여기까지가 하나의 Block)
Prediction Layer
- shared된 item embedding이 있음
- transformer block의 마지막 아이템의 vector와 item embedding vector의 dot product를 통해서 positive sample과 negative sample에 대해 아이템별 score를 계산
Experiments
- 데이터
- Beauty, Games, Steam, ML-1M
- 지표
- MC 기반 모델들 + GRU4Rec 등 RNN기반 모델들과 비교했을 때 높은 성능, 학습 시 빠른 수렴, Scalability
- ablation 분석시
- position embedding 제외시(순서 정보 고려X), sparse한 beauty 데이터셋에서는 오히려 성능이 올라가지만 dense한 데이터에서는 낮은 성능
- shared item embedding, residual connection은 성능에 중요
- multi-head attention은 성능 향상에 도움이 되지 않음
- attention weights 분석시
- sparse한 데이터에서는 가장 최근의 아이템 정보에 집중하고 비교적 dense한 데이터에서는 최신이 더 중요하긴 하지만 전반적으로 고르게 집중한다는 것을 알 수 있었음