Leveraging Negative Signals with Self-Attention for Sequential Music Recommendation (MuRS ‘23)
-
한줄요약: sequential music recommendation /w contrastive learning + 음악 스킵이라는 negative feedback 정보를 활용
-
Data
- Spotify Music Streaming Sessions Dataset 사용
- user 식별 안 되므로 session-based system (장기적인 유저 히스토리를 고려하지 않고 개별 세션을 모두 새로운 유저로 가정)
- 딱 이 세션 데이터에 존재하는 아이템, 행동유형 구분, 타임스탬프 정도만 사용
- 유형: positive(건너뛰지 않고 들음), negtative(건너뛰기 함)
- 즉 일반적인 sequntial 추천에서는 모든 아이템이 등장순서대로 시퀀스로 만들어져서 현재 time에서 들은 아이템까지 기반으로 다음 time의 아이템을 예측하는 과제이지만 여기서는 가장 다음에 발생하는 positive 아이템을 예측하는 과제임
- 스킵의 정의
- 원래 데이터셋에서 스킵 강도가 1~3으로 설정됨
- 매우 짧게 재생됨 / 짧게 재생됨 / 대부분 재생됨(완전히 재생된 건 아님)
- 1~2만 스킵으로 사용
- 원래 데이터셋에서 스킵 강도가 1~3으로 설정됨
- volume
- 각 세션은 10~20개의 시퀀스로 구성(청취 간격 < 60s)되었고 1억 6천만개가 존재하나 이 중 약 450K만 샘플링
- 약 200만개의 interaction, 100만개의 unqiue item, 스킵의 비중은 약 15%
- 각 세션은 10~20개의 시퀀스로 구성(청취 간격 < 60s)되었고 1억 6천만개가 존재하나 이 중 약 450K만 샘플링
- Spotify Music Streaming Sessions Dataset 사용
-
Model
- SASRec, BERT4Rec에서 영감을 받아 기본적인 Transformer 아키텍쳐 사용
- item(track) 임베딩: 학습된 트랙 임베딩을 룩업 테이블에 저장
- positional 임베딩: 학습 가능한 위치 임베딩
- 인코더: 표준적인 트랜스포머 인코더 (multi-head self attention layers, position-wise feedforwards layer)
- Prediction layer: 인코더의 hidden + fully connected layer(GELU activation) = prediction vector
- 임베딩 테이블과 내적 계산해서 각 트랙에 대한 확률분포 얻음 + sampled softmax (각 미니배치당 대상 트랙들과 unseen sample 1000개 섞기, 이때 1000개는 각 에폭 마다 새로 샘플링)
- SASRec, BERT4Rec에서 영감을 받아 기본적인 Transformer 아키텍쳐 사용
-
Task
- (main) sequential recommendation task
- NLL (negative log likelihood)
- unidirectional인 경우(~SASRec) : auto-regressive next item prediction, causal mask (미래의 트랙은 마스킹)
- bidirectional인 경우(~BERT4Rec) : masked language modeling, 마지막에 mask token 추가
- NLL (negative log likelihood)
- (sub) skip-informed contrastive task
- InfoNCE
- 주어진 컨텍스트 에 대해 positive 샘플 (시퀀스 다음에 오는 첫번째 non-skip track) 를 negative 샘플들 (시퀀스 내의 모든 스킵된 track) 과 구별하도록 학습
- 여기서 context는 트랜스포머 인코더 출력 벡터 또는 각 원본 트랙 임베딩을 둘다 실험했음
- 부정 샘플들과 를 포함하는 집합 에 대해 infoNCE를 평균내는 방식
- 는 유사도 scoring function으로 cosine similarity 사용
- 주어진 컨텍스트 에 대해 positive 샘플 (시퀀스 다음에 오는 첫번째 non-skip track) 를 negative 샘플들 (시퀀스 내의 모든 스킵된 track) 과 구별하도록 학습
- InfoNCE
- (main) sequential recommendation task
➡️ 최종 Loss는 가 됨

- Results
- skip-informed contrastive task를 추가한 것이 지속적으로 우수한 성능
- K 값이 증가할수록 성능 향상 폭이 줄어들긴 함. 이를 contrastive task가 주로 관찰된 트랙(긍정/부정 샘플) 간의 관계를 학습하기 때문으로 해석. 추천 범위가 넓어질수록 비교 대상에 관찰되지 않은 트랙들이 더 많이 포함되어 contrastive task의 직접적인 효과가 희석 (즉, 부정적 피드백 학습은 주로 상위 랭킹 추천에 더 큰 영향을 미침)
- unidirectional이 bidrectional보다 우수하나 K값이 증가함에 따라 성능 격차가 감소
- 이 데이터셋의 상대적으로 높은 밀도와 짧은 시퀀스 길이(10-20개 트랙)가 BERT-like 아키텍처의 성능을 제한했을 수 있음 (BERT4Rec은 길고 희소한 시퀀스에서 더 잘할 수 있음)
- subtask의 context vector로는 아이템 임베딩을 그대로 사용하는 것이 hidden vector(세션 정보를 반영한) 사용한는 것보다 약간 우수함
- contrastive task에서는 세션 맥락보다 트랙 자체의 본질적인 매력/비매력 관계를 학습하는 것이 전반적인 성능에 더 유리할 수 있음
- skip-informed contrastive task를 추가한 것이 지속적으로 우수한 성능
Enhancing Sequential Music Recommendation with Negative Feedback-informed Contrastive Learning (Recsys ‘24)
- 위의 논문 후속연구
- 아이디어는 거의 똑같고 여러 모델 아키텍쳐/여러 데이터셋/평가지표에 대해 확장, skip item에 대한 down-ranking 확인
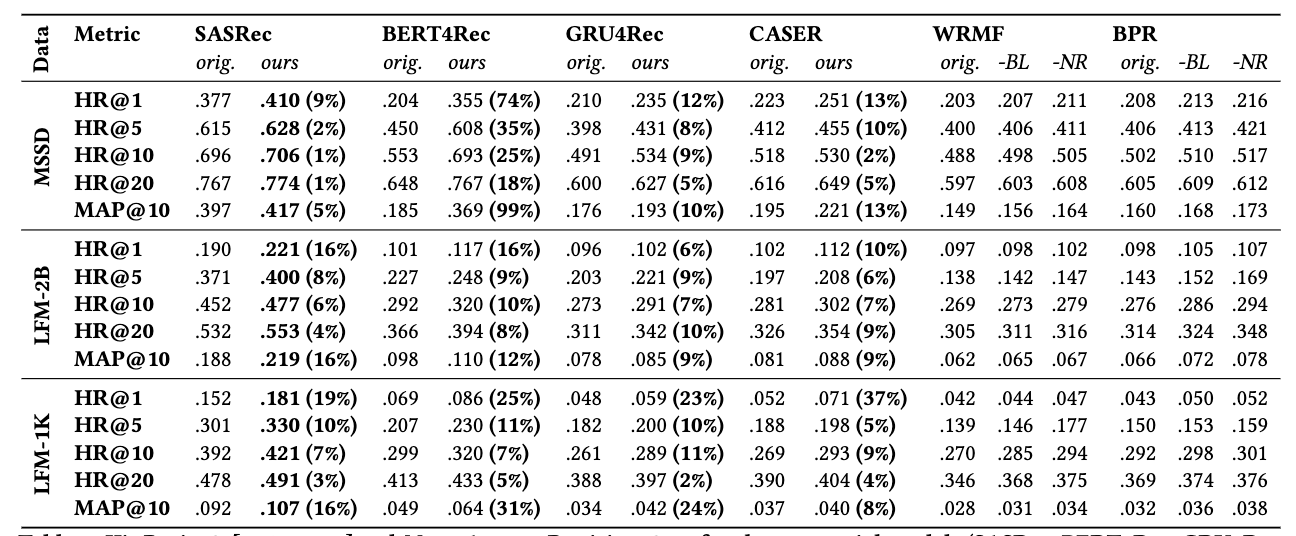
- 제안된 negative feedback-informed 손실 항이 모든 데이터셋과 모델에서 일관되게 성능을 향상시킴 → 해당 방법론의 범용성과 효과를 뒷받침
- 일반적으로 Self-Attentive 아키텍처(SASRec, BERT4Rec)가 다른 모델들보다 우수한 성능을 보였으며, 특히 SASRec은 모든 데이터셋에서 지속적으로 최고의 성능을 기록
- non-sequential baseline(WRMF, BPR)의 경우 유사한 성능 향상
- 전반적인 절대 성능은 MSSD에서 가장 높았고, 이어서 LFM-2B, LFM-1K 순서
- MSSD(2019)는 스트리밍 기반의 알고리즘 중심 콘텐츠 비중이 높고, LFM-1K (2009)는 사용자 큐레이션 중심이어서 가장 낮은 성능, LFM-2B (2020)는 둘의 혼합된 특성
- (당연히..) skip 비율이 높을수록 (negative feedback 샘플이 많을수록) 성능 향상에 크게 기여
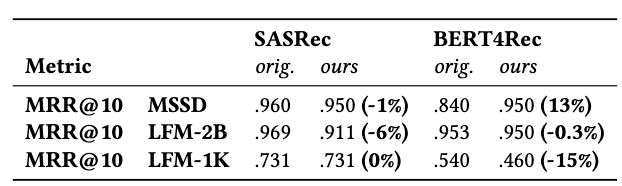
- skip downranking
- 제안된 방법론이 관찰되지 않은 skip 트랙의 랭킹을 낮추는 데 얼마나 효과적인지를 정량화
- 즉 MRR 점수가 감소한다는 것 = 모델이 건너뛴 트랙을 더 낮은 순위로 추천
- 흥미로운 점: BERT4Rec 모델이 MSSD 데이터셋에서 유일하게 MRR 점수가 증가하는(즉, 성능이 나빠지는)데, 이 조합(BERT4Rec on MSSD)이 핵심 추천 태스크에서는 가장 높은 성능 향상(Hit Rate 기준)을 보임
- 가설1) BERT4Rec은 유일한 bidrectional model임. 이 논문의 contrastive learning 방법론은 기본적으로 “다음 긍정 아이템”과 다른 아이템들의 관계를 모델링하는 forward direction인데 이게 상충할 수도 있음. 어쨌든 unidirectional한 SASrec이 절대적인 성능은 가장 높다는 걸 고려하면 forward direction이 sequential music recommendation에서는 중요하다고 해석.
- 가설2) MSSD 데이터셋은 알고리즘에 의해 생성된 콘텐츠와 사용자 피드백의 비중이 높으므로 완전히 사용자 의도가 아닌 spotify의 추천 알고리즘에 크게 좌우됨. 따라서 트랙 예측 성능이 높아질 수는 있지만 기존 알고리즘의 실수(skip track을 추천하는 실수)를 답습하고 있을 수도