Evaluating Performance and Bias of Negative Sampling in Large-Scale Sequential Recommendation Models
- 한줄요약: negative sampling에는 제너럴한 최적해는 없고 데이터 분포를 고려해야 함
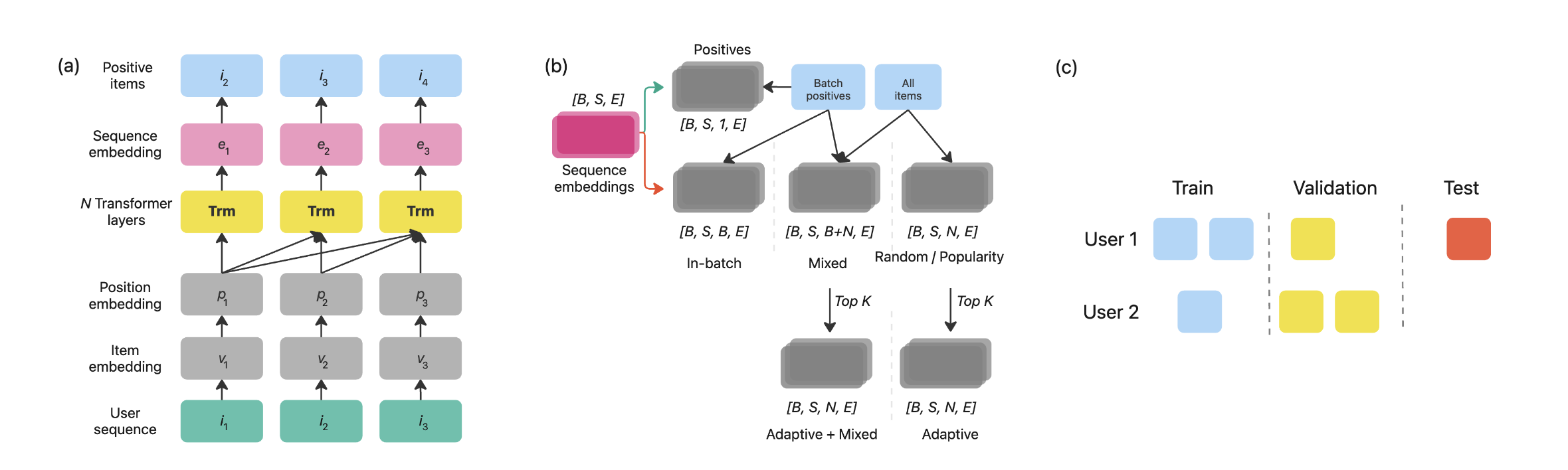
- SASRec을 백본으로 사용
- split: leakage방지를 위해 전통적인 leave-one-out 방식 대신 Global Temporal Splitting 전략을 사용
Negative Samping Methods
- Global Sampling (Random Negative Sampling, RNS; Popularity Negative Sampling, PNS):
- 사용자 시퀀스에 이미 존재하는 아이템을 제외하고 전체 아이템에서 선택(랜덤 또는 인기도에 따라) / tensor shape:
B, S, N -
- 사용자 임베딩 이나 positive item 와 무관하게 샘플링하고 단순히 아이템의 인기도(빈도)에만 의존함
- RNS의 경우 이어서 모든 아이템에 대해 샘플링 확률이 동일하고, PNS의 경우 일 때 인기도 에 따라 샘플링 (인기 있는 항목이 샘플링될 확률이 높게)
- 사용자 시퀀스에 이미 존재하는 아이템을 제외하고 전체 아이템에서 선택(랜덤 또는 인기도에 따라) / tensor shape:
- In-Batch Negative Sampling (BNS):
- 현재 학습 배치에 있는 모든 positive Item이 negative Item으로 간주하되 사용자 시퀀스에 있는 아이템은 제외 / tensor shape:
B, S, B
- 현재 학습 배치에 있는 모든 positive Item이 negative Item으로 간주하되 사용자 시퀀스에 있는 아이템은 제외 / tensor shape:
- Mixed Negative Sampling (MNS):
- in-batch negative sample과 random negative sample을 결합 / tensor shape:
B, S, B+N - 여기서는 배치 내 샘플과 무작위 샘플의 비율을 1:8로 설정
- in-batch negative sample과 random negative sample을 결합 / tensor shape:
- Adaptive Negative Sampling (ANS):
- RNS로 선택된 아이템 중에서 사용자의 시퀀스 내 각 아이템에 대해 가장 높은 점수를 받은 상위 K만 유지 / tensor shape:
B, S, N를 유지하지만, N-K개의 아이템 값은 0으로 줄어듦 - 샘플링 분포는 와 같이 사용자 임베딩에만 의존
- Hard Negative를 식별하여 모델이 학습하기 어려운 샘플에 집중하기 위함
- RNS로 선택된 아이템 중에서 사용자의 시퀀스 내 각 아이템에 대해 가장 높은 점수를 받은 상위 K만 유지 / tensor shape:
- Adaptive with Mixed Negative Sampling (AMNS):
- MNS로 선택된 아이템 중에서 위와 동일하게 선택
Evaluation
-
성능 = HitRate@k
- 일반적인 hit rate의 정의를 확장하여 인기도를 고려한 HitRate cohort를 사용
여기서 는 아이템의 인기도 코호트(Head, Mid, Tail)를 나타내고(학습 데이터셋에서 발생 빈도 기반), 는 추천 모델이 추천한 k개
- 일반적인 hit rate의 정의를 확장하여 인기도를 고려한 HitRate cohort를 사용
-
균형 (Balance)
- 인기도 코호트별 정확도(HR) 분포의 균형을 측정하는 새로운 지표
Balance 값이 높을수록 인기도 코호트 간 성능 편차가 적음을 의미
- 인기도 코호트별 정확도(HR) 분포의 균형을 측정하는 새로운 지표
Result
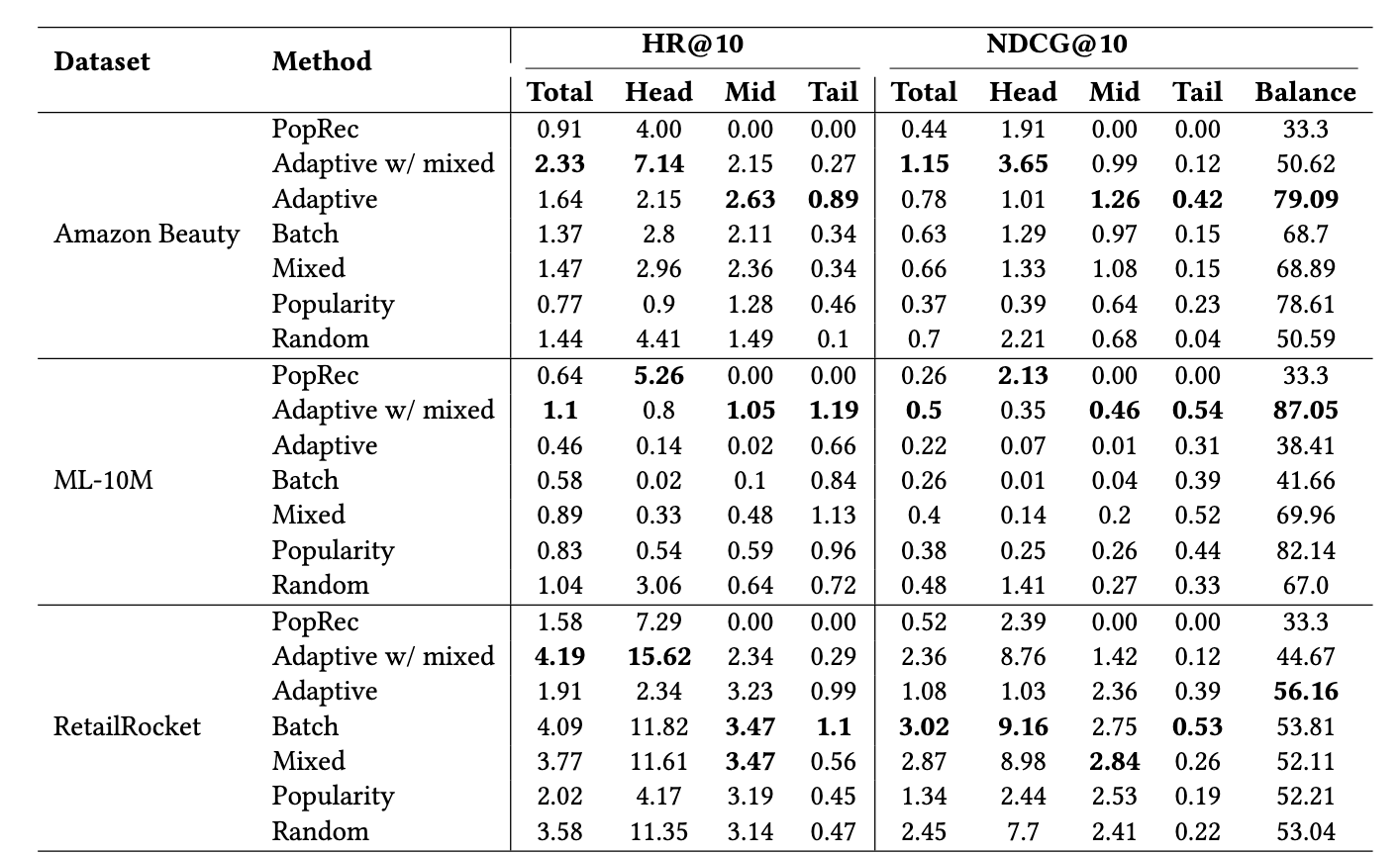
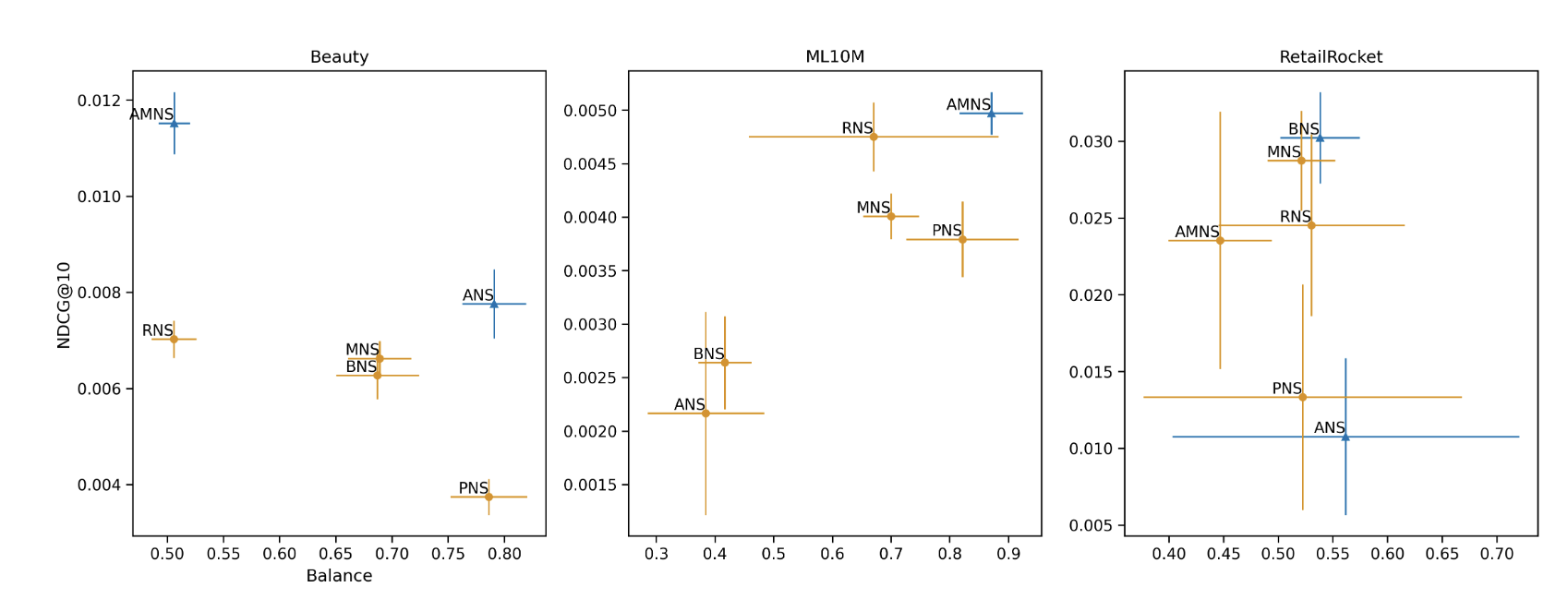
- 주요 발견
- 모델 성능은 데이터셋의 인기도 분포와 Negative Sampling 기법에 크게 의존함
- ML-10M(head 아이템에 상호작용 몰림, 극단적 롱테일, 122:1 )에서는 Random 및 Adaptive with Mixed 방법이 높은 성능과 균형을 보임
- Amazon Beauty 및 RetailRocket 데이터셋(인기도 편향이 상대적으로 적음)에서는 Adaptive with Mixed 및 Random Sampling이 균형 지표 달성에 어려움을 겪음
- RNS는 높은 성능을 달성하지만 데이터의 인기도 편향을 강화하는 경향이 있음 (즉 모델이 head item에 대해 훨씬 더 좋은 성능을 보이게 함)
- 반면 Popularity Sampling은 균형 지표를 개선하지만 RNS에 비해 전체 모델 성능을 현저히 저하시킴
- In-batch는 결국 배치 안에 등장하는 애들이기 때문에 popularity랑 경향성은 같이 가서 random보다 성능이 낮고 균형은 random과 popularity사이인 경향(대부분 다 성능이 일관적으로 낮아서인 것 같기도..)
- Adaptive with Mixed Sampling은 모든 데이터셋에서 가장 높은 전반적인 성능을 달성
- Hard Negative가 성능에 도움이 됨
- Random Sampling과 유사하게 인기도 편향을 강화하는 경향이 있음 (Batch 대 Random 샘플 비율이 1:10이므로)
- 모델 성능은 데이터셋의 인기도 분포와 Negative Sampling 기법에 크게 의존함